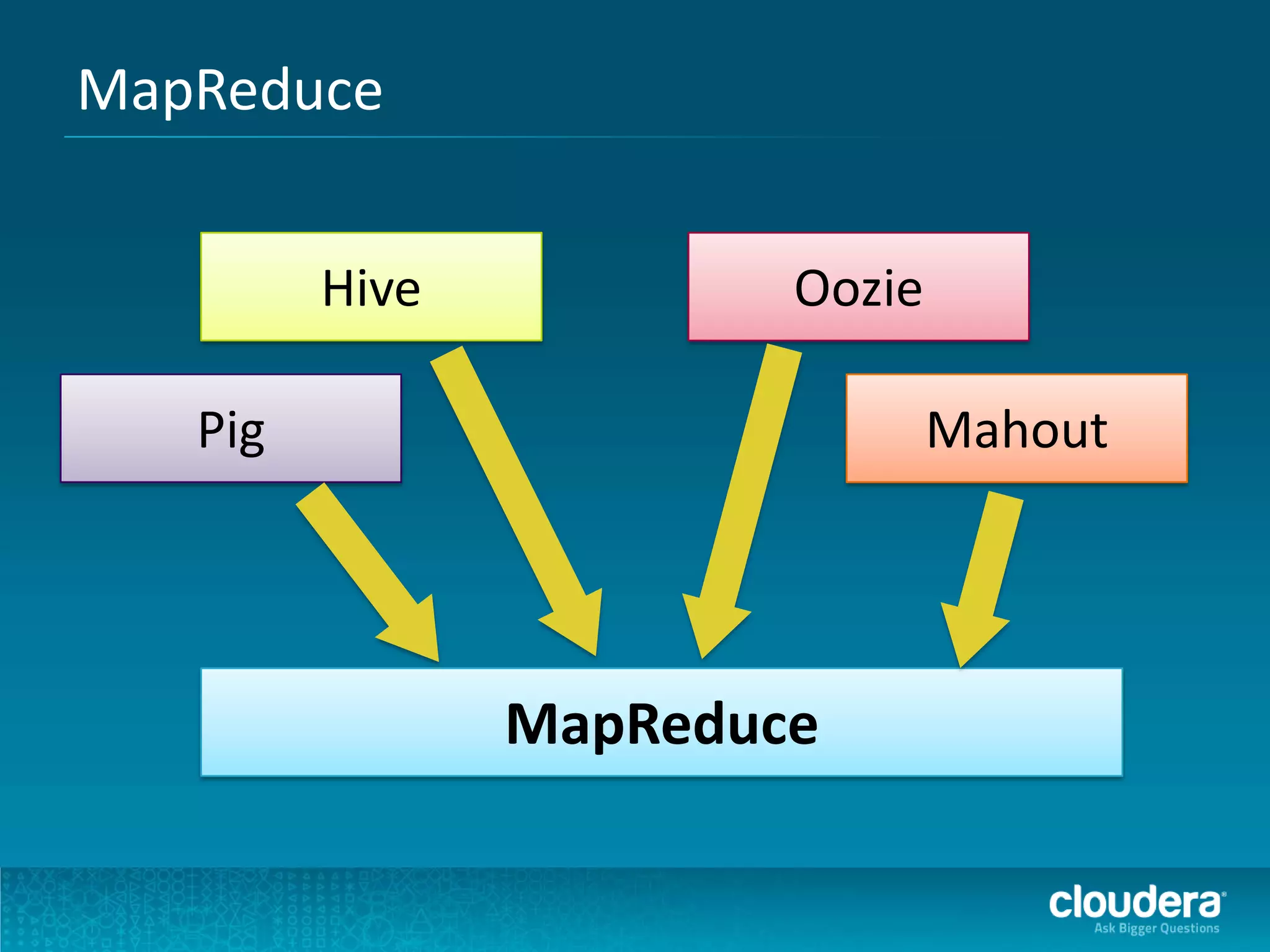
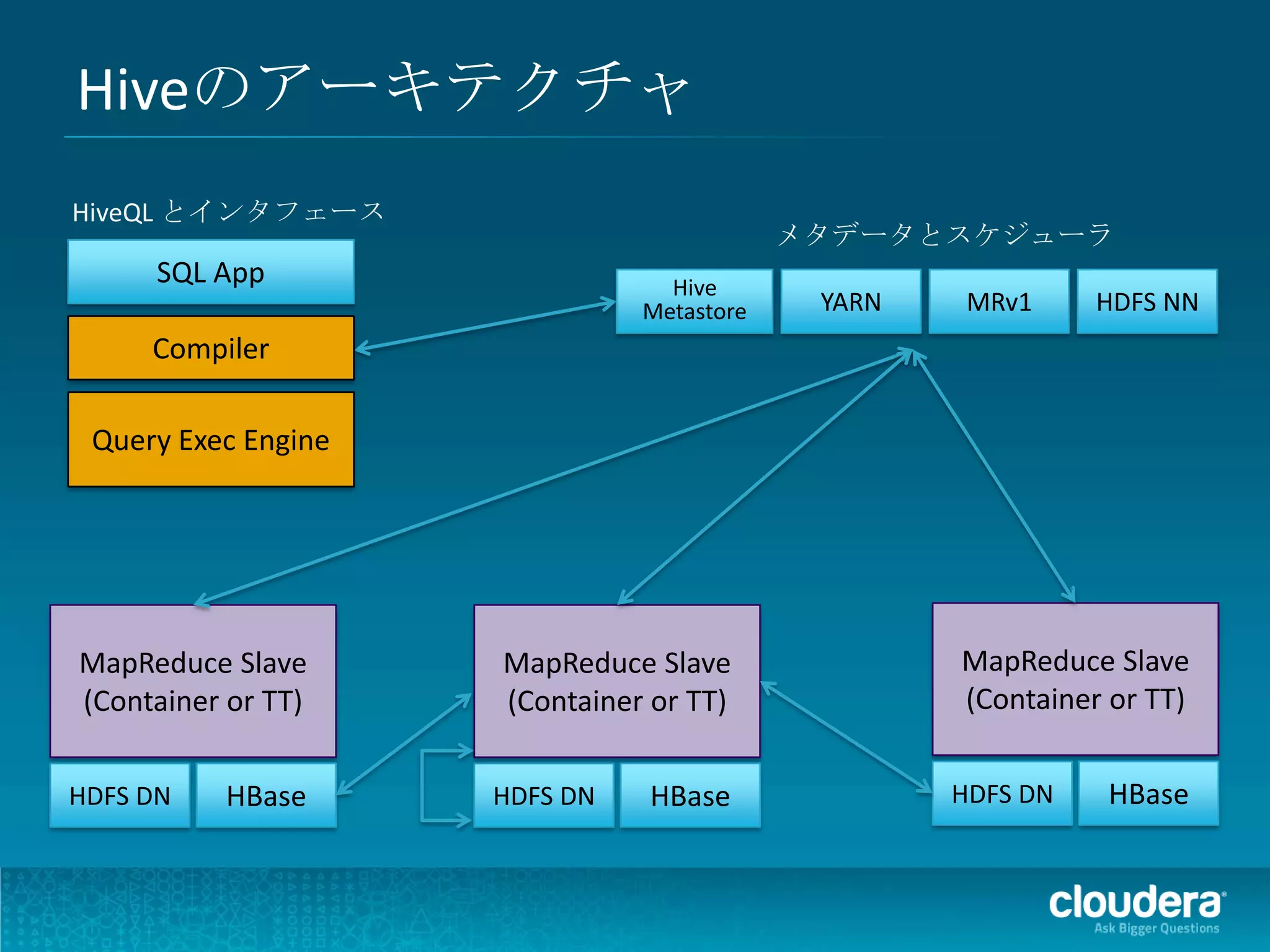
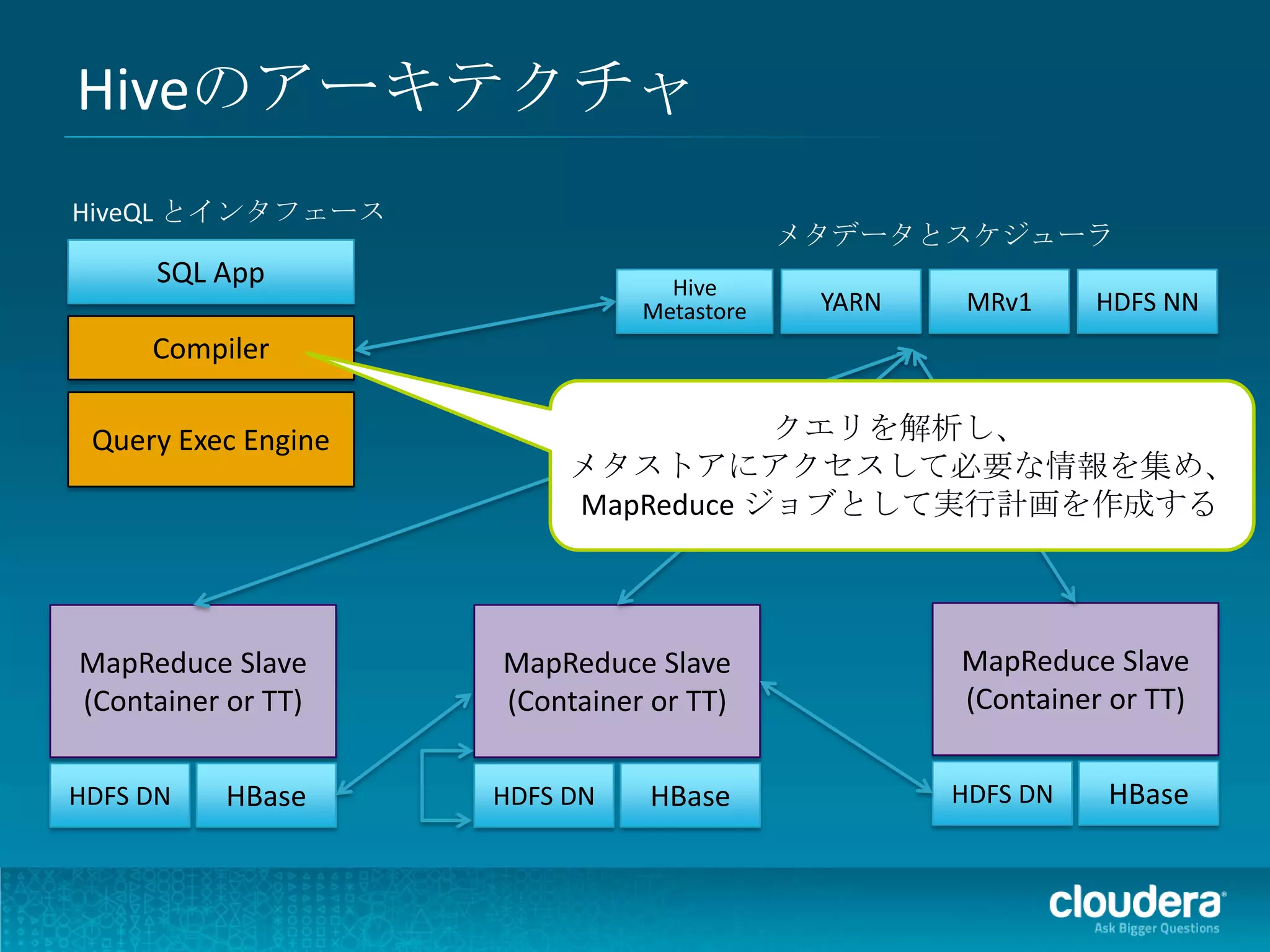
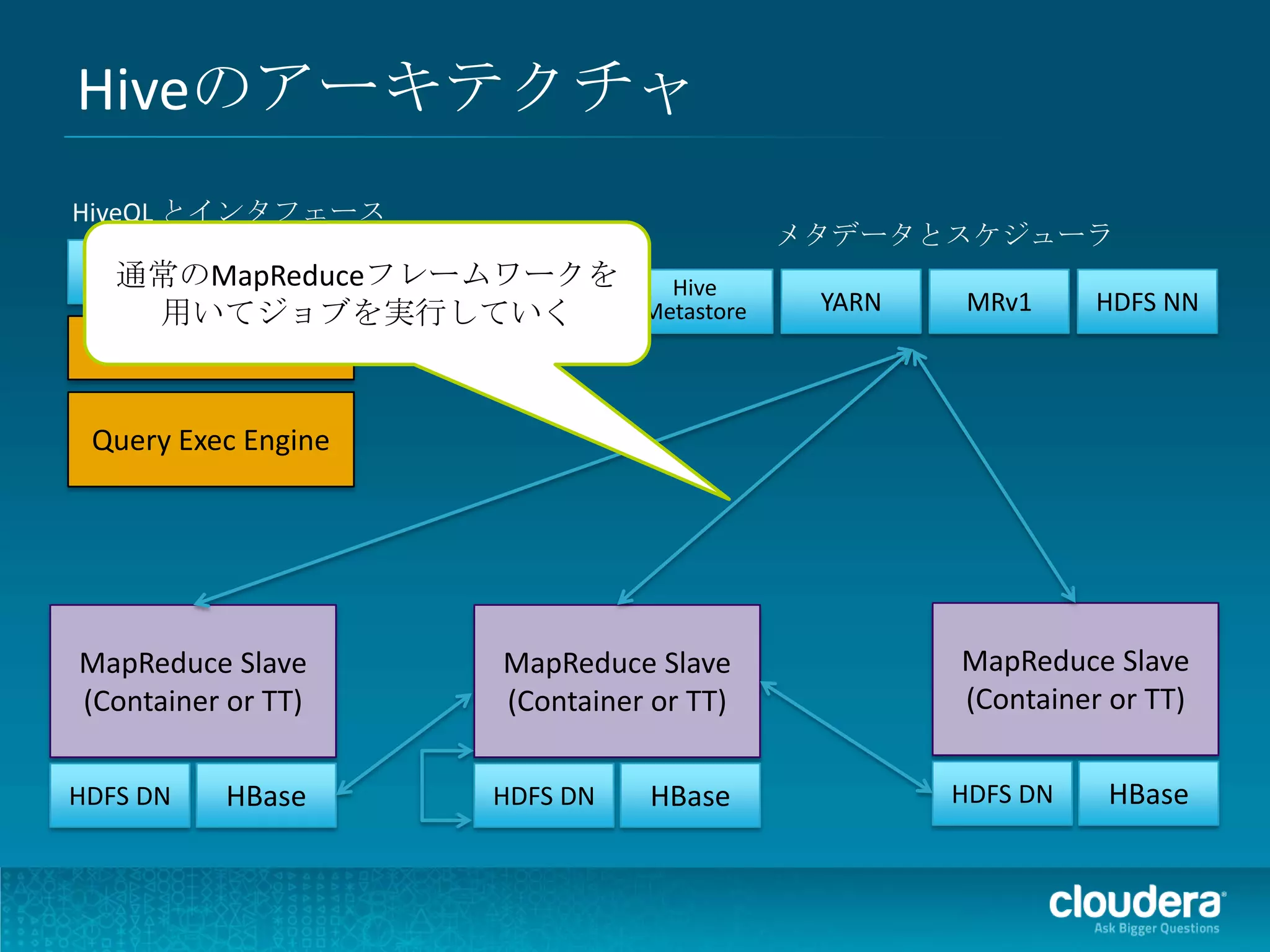
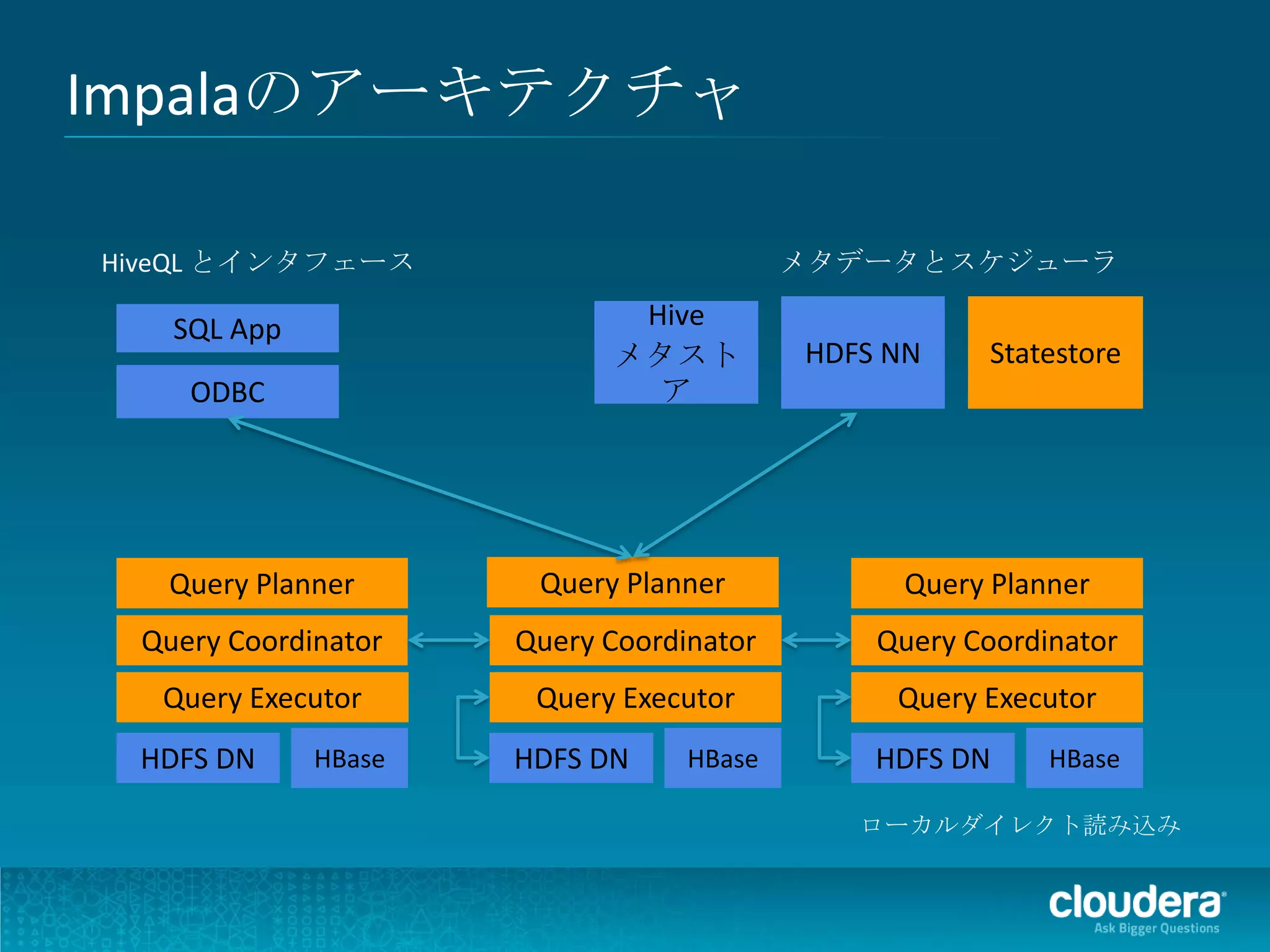
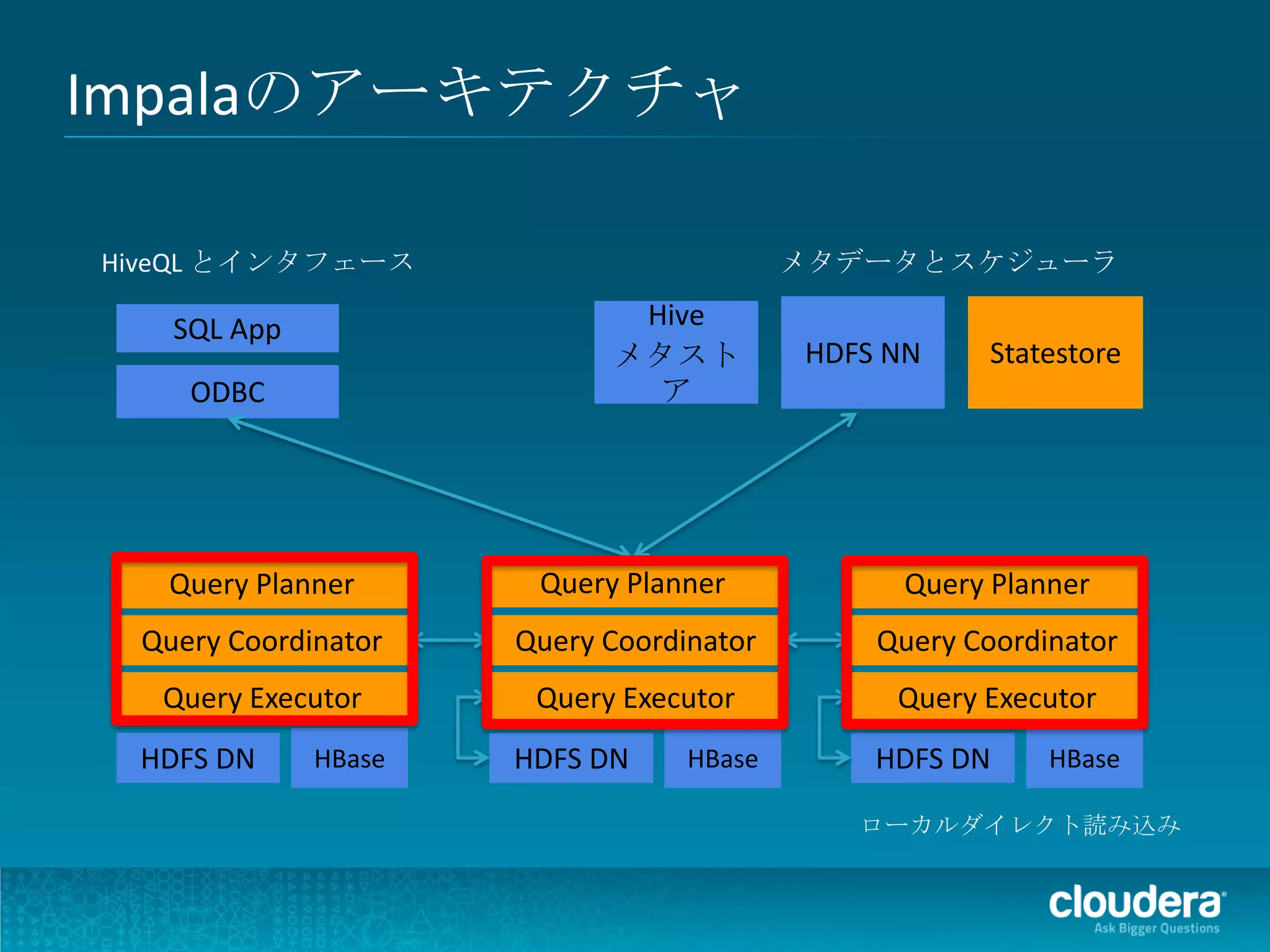
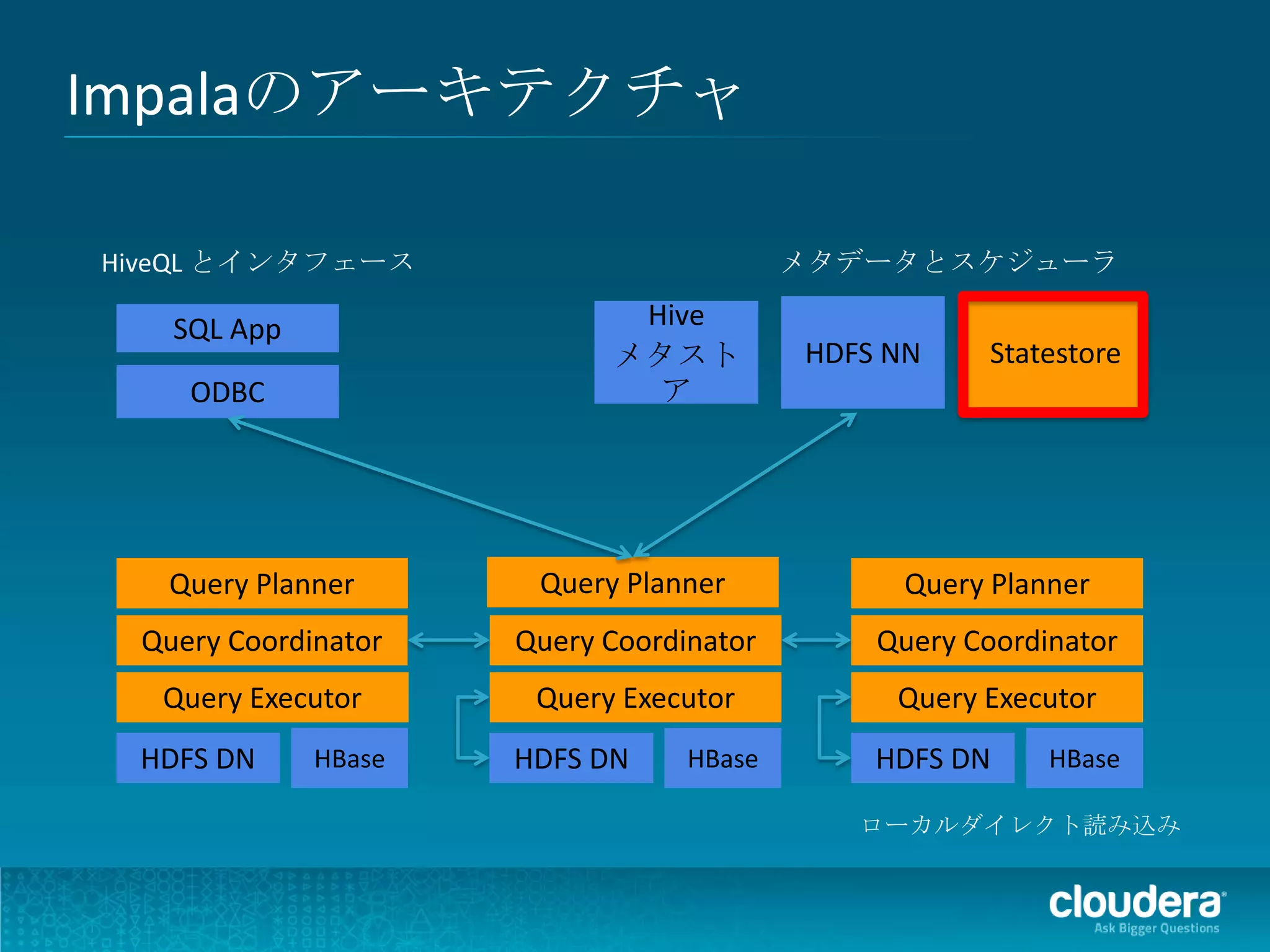
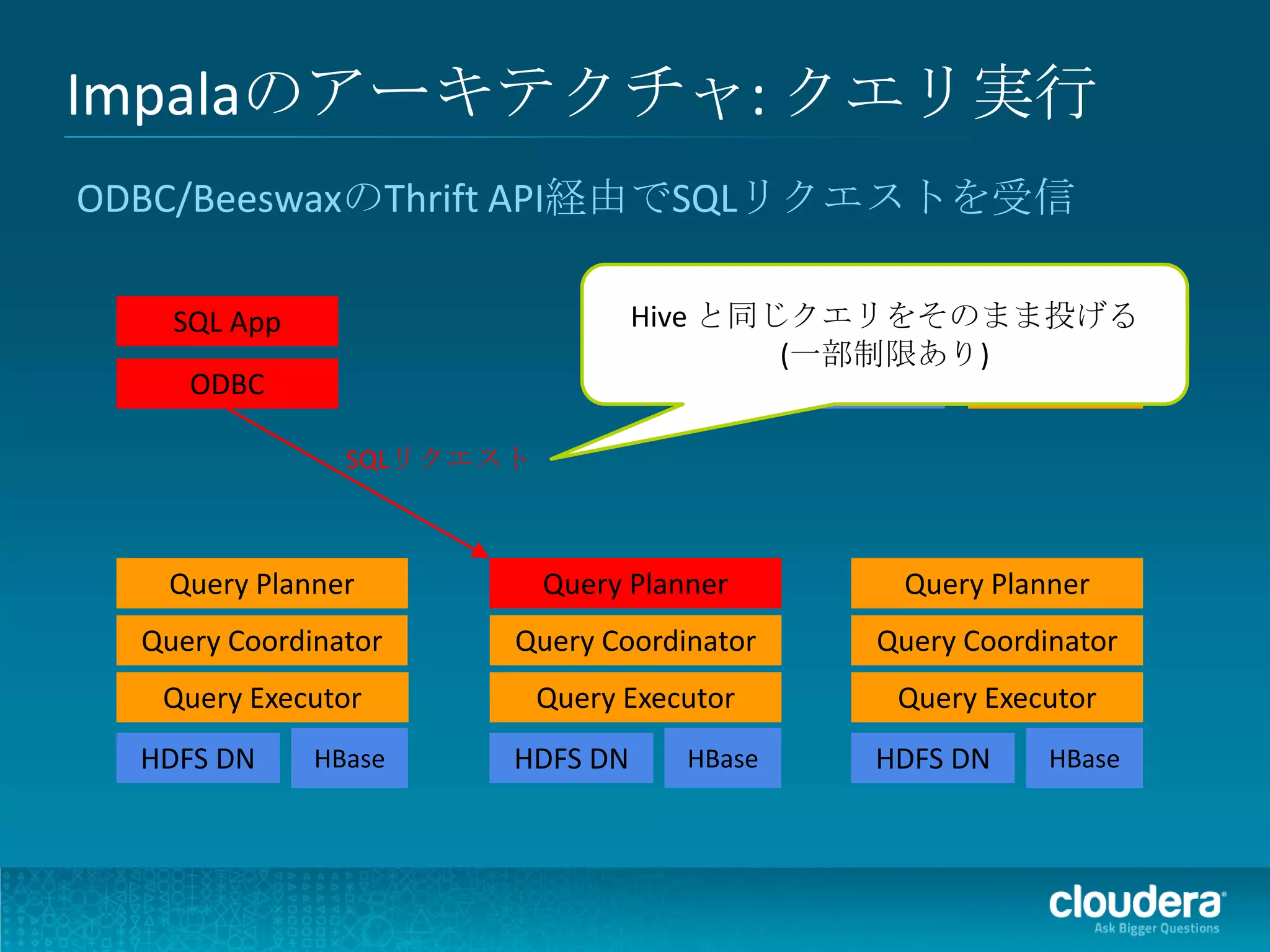
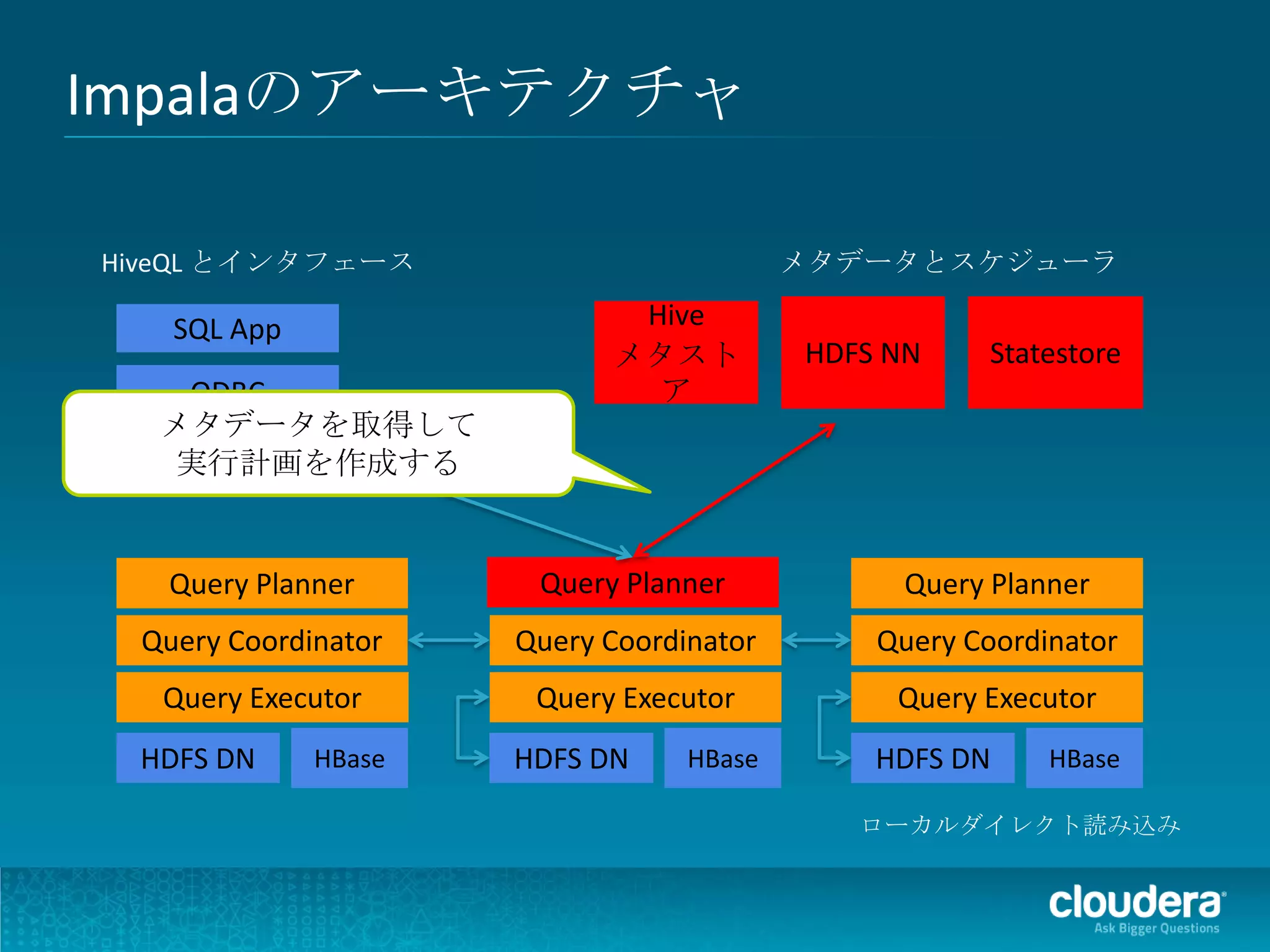
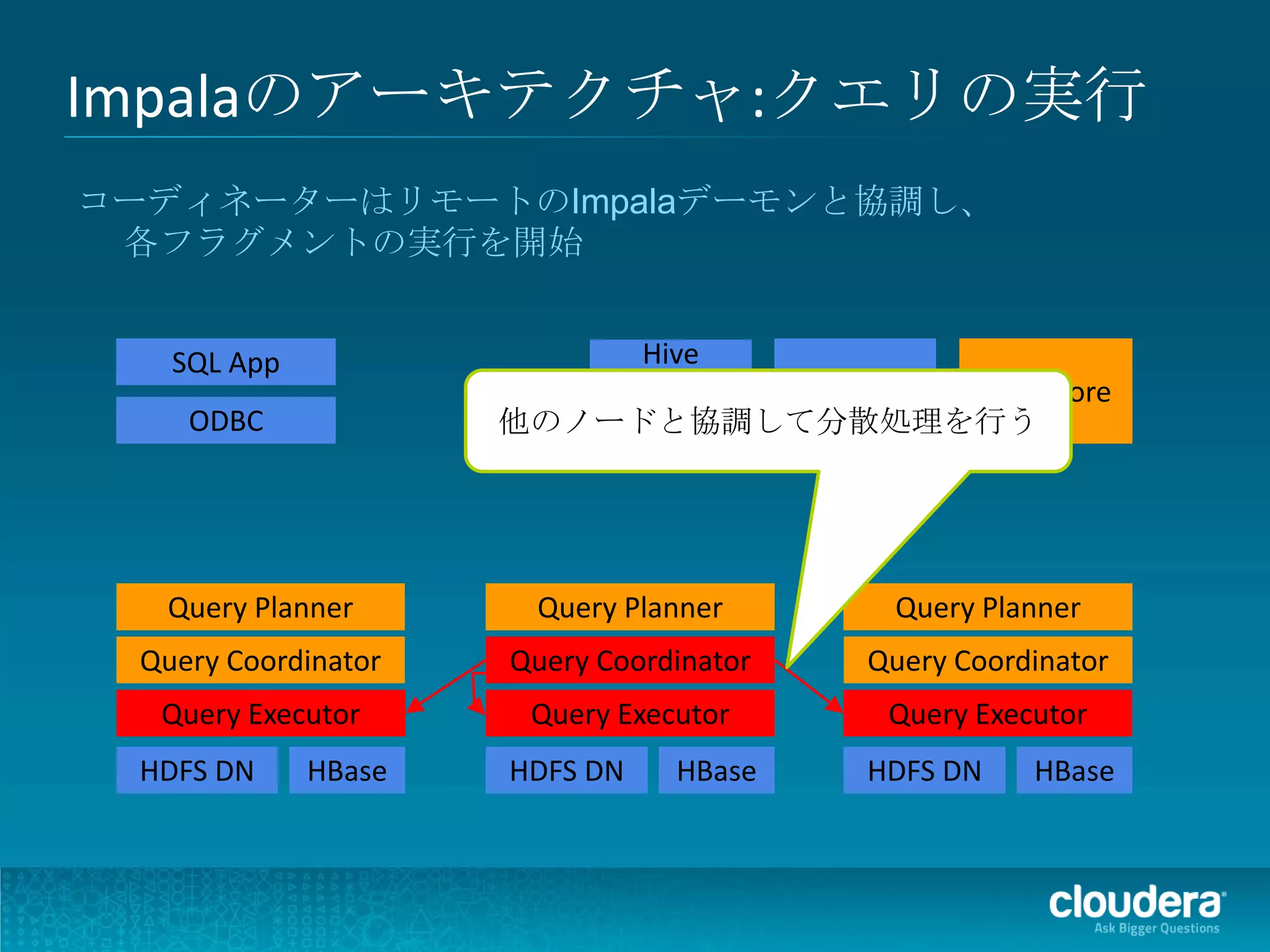
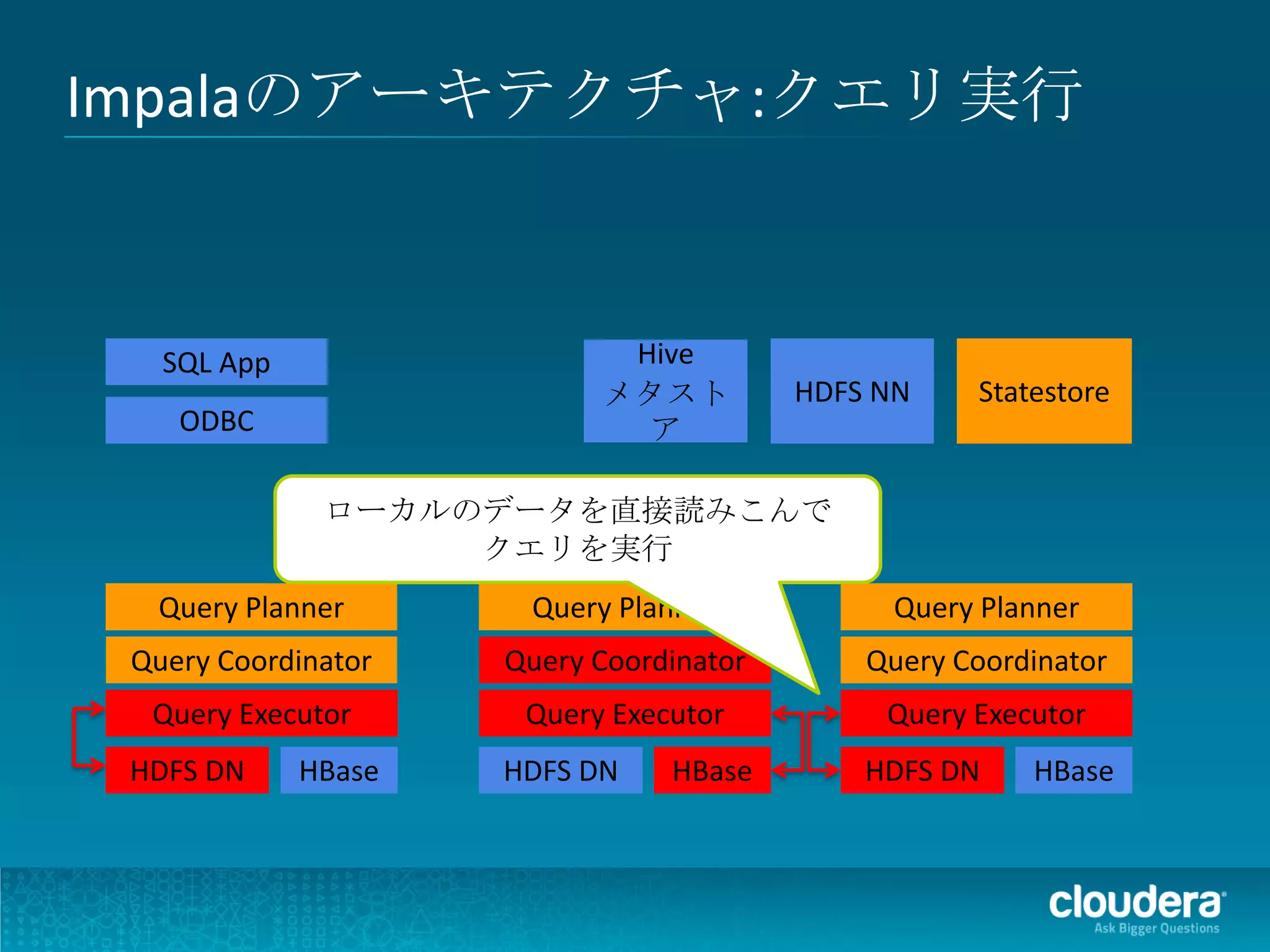
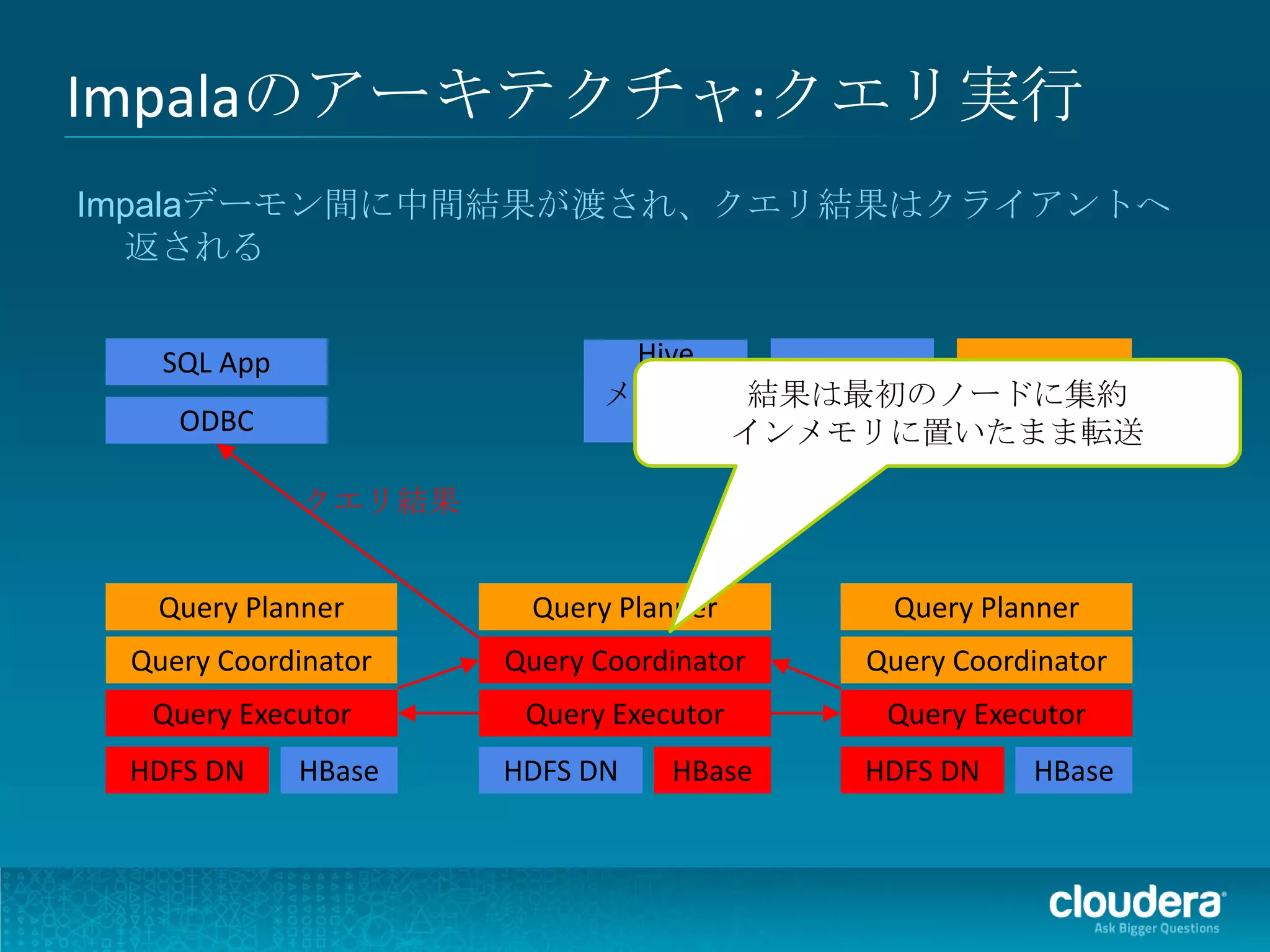
Impalaのアーキテクチャ
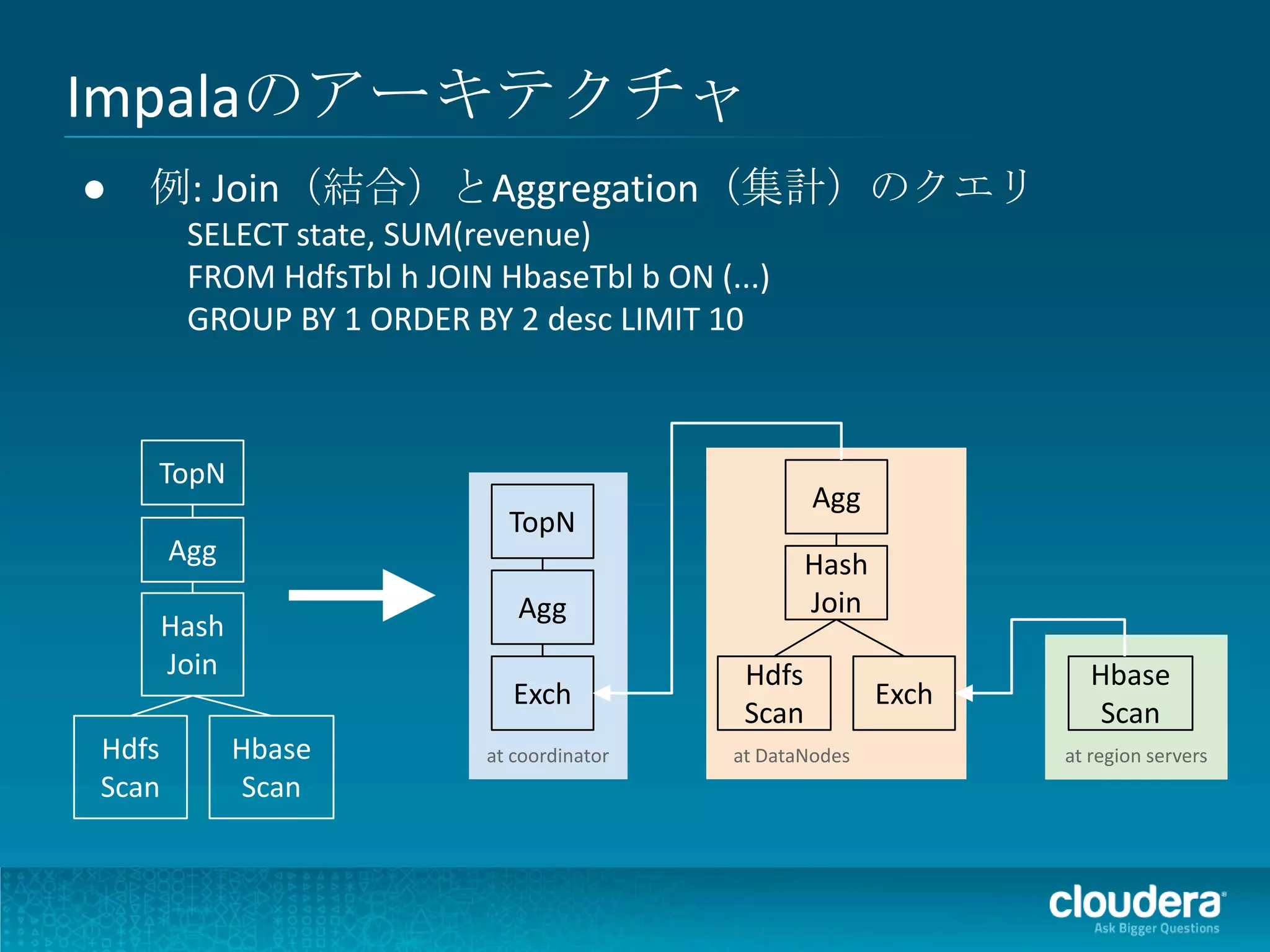
● 例: Join(結合)とAggregation(集計)のクエリ
SELECT state, SUM(revenue)
FROM HdfsTbl h JOIN HbaseTbl b ON (...)
GROUP BY 1 ORDER BY 2 desc LIMIT 10
TopN
Agg
TopN
Agg Hash
Agg Join
Hash
Join Hdfs Hbase
Exch Exch
Scan Scan
Hdfs Hbase at coordinator at DataNodes at region servers
Scan Scan


























































![[D22] Pivotal HD 2.0 -業界最高レベルSQL on Hadoop技術「HAWQ」解説- by Masayuki Matsushita](https://cdn.slidesharecdn.com/ss_thumbnails/d22pivotal-140709032745-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)































