Downloaded 13 times





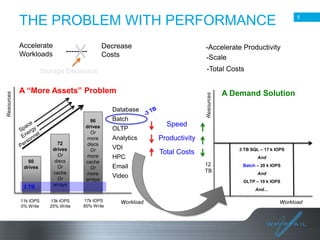







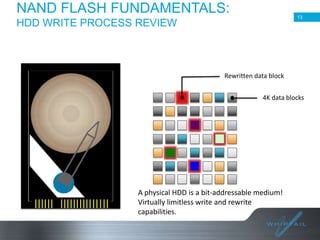
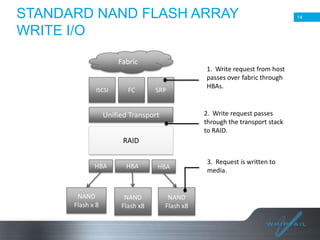


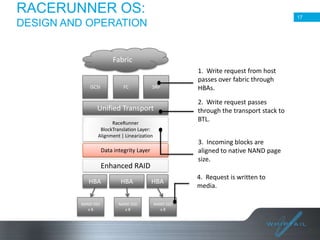
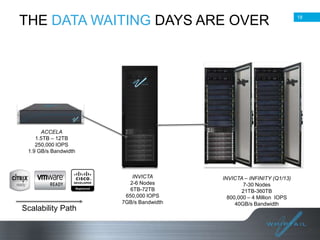

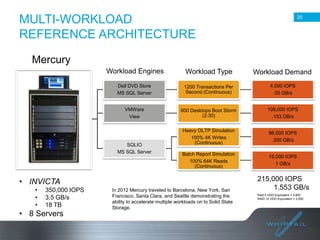





Batch processing allows jobs to run without manual intervention by shifting processing to less busy times. It avoids idling computing resources and allows higher overall utilization. Batch processing provides benefits like prioritizing batch and interactive work. The document then discusses different approaches to batch processing like dedicating all resources to it or sharing resources. It outlines challenges like systems being unavailable during batch processing. The rest of the document summarizes Whiptail's flash storage solutions for accelerating workloads and reducing costs and resources compared to HDDs.





















































































