Download as PDF, PPTX










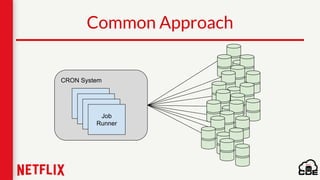
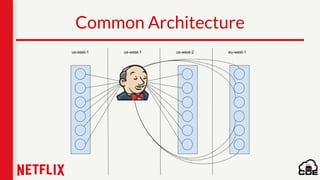



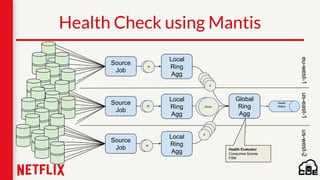


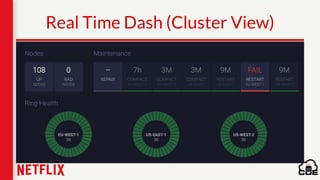






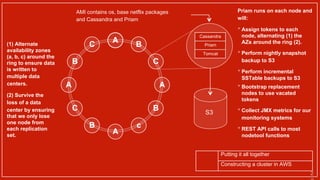
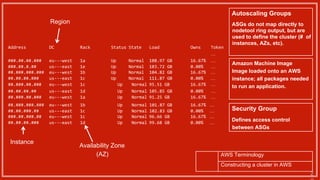






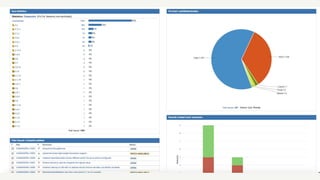






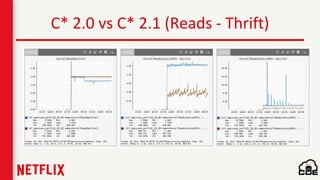
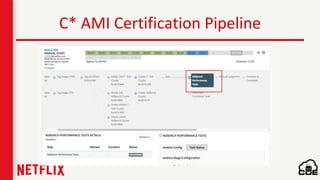
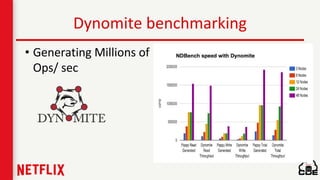

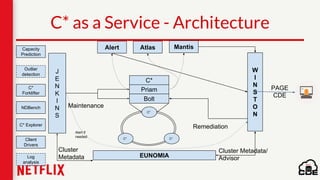


1) Netflix uses Apache Cassandra as its main data store and has hundreds of Cassandra clusters across multiple regions containing terabytes of customer data for services like viewing history and payments. 2) Maintaining and monitoring Cassandra at Netflix's scale presents challenges around configuration, availability across regions and availability zones, and operating Cassandra in public clouds. 3) Netflix addresses these challenges through tools like Priam for automated bootstrapping and backup/restore, monitoring through services like Mantis and Atlas, and capacity planning with tools like NDBench and Unomia.











































































