Downloaded 186 times

















![FSA SOFTWARE EXAMPLE - REDUCTION
float foo(float);
float myArray[…];
Task<float, ReductionBin> task([myArray]( IndexRange<1> index) [[device]] {
float sum = 0.;
for (size_t I = index.begin(); I != index.end(); i++) {
sum += foo(myArray[i]);
}
return sum;
});
float result = task.enqueueWithReduce( Partition<1, Auto>(1920),
[] (int x, int y) [[device]] { return x+y; }, 0.);
21 | The Programmer’s Guide to the APU Galaxy | June 2011](https://image.slidesharecdn.com/philrogerskeynote-final-120610225926-phpapp02/85/AFDS-2011-Phil-Rogers-Keynote-The-Programmer-s-Guide-to-the-APU-Galaxy-21-320.jpg)

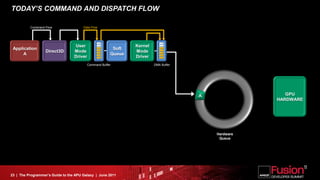
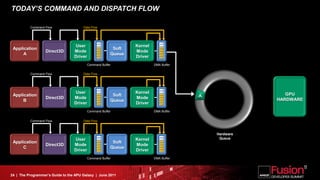
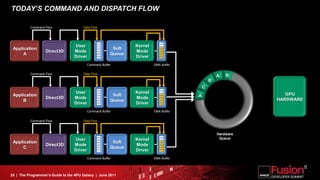
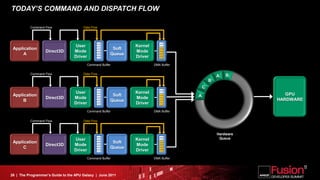

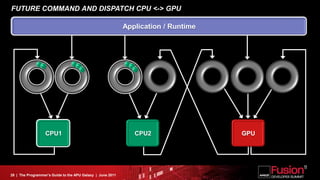
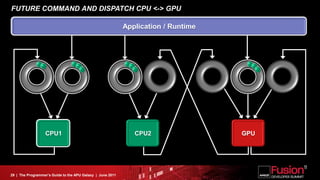
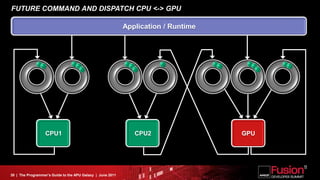
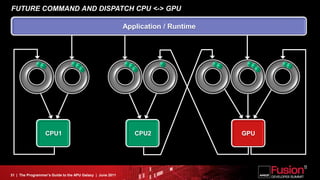




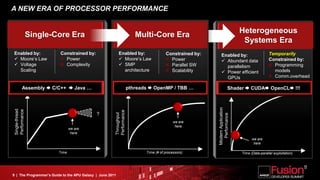
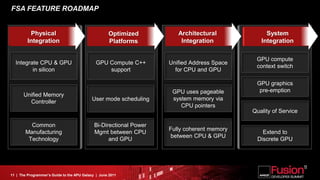
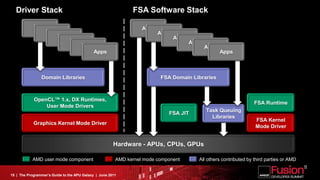
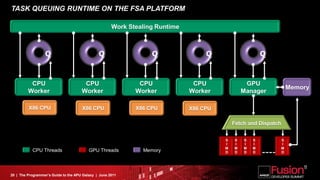
This document is a programmer's guide to AMD's Accelerated Processing Unit (APU) architecture, highlighting its features, programming environment, and future developments. It outlines the integration of CPU and GPU capabilities, improvements in programming accessibility, and performance benchmarks across various APU series. The guide emphasizes the importance of open standards and architectural designs that support advanced heterogeneous computing.







































![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































