Download as PDF, PPTX




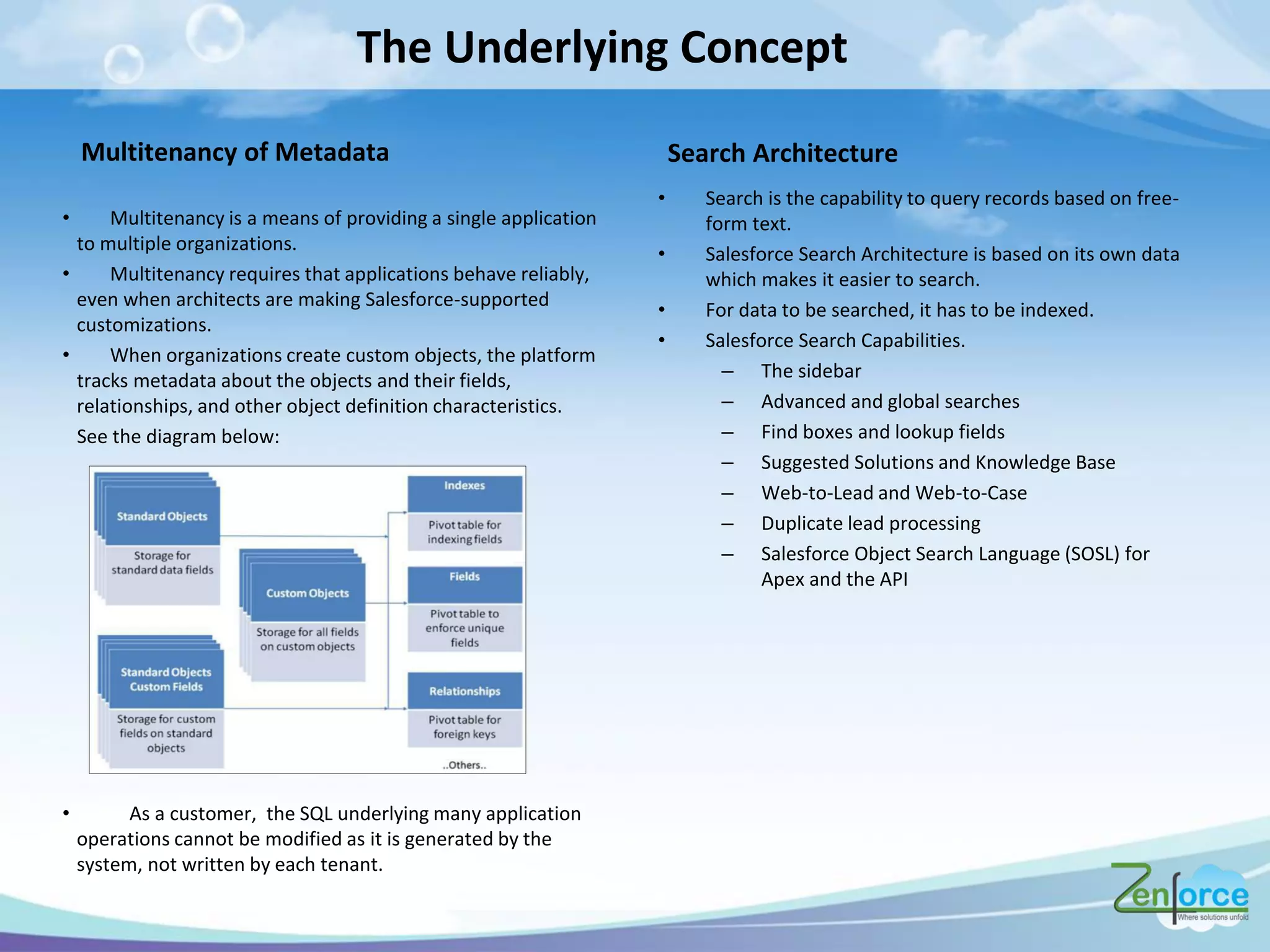
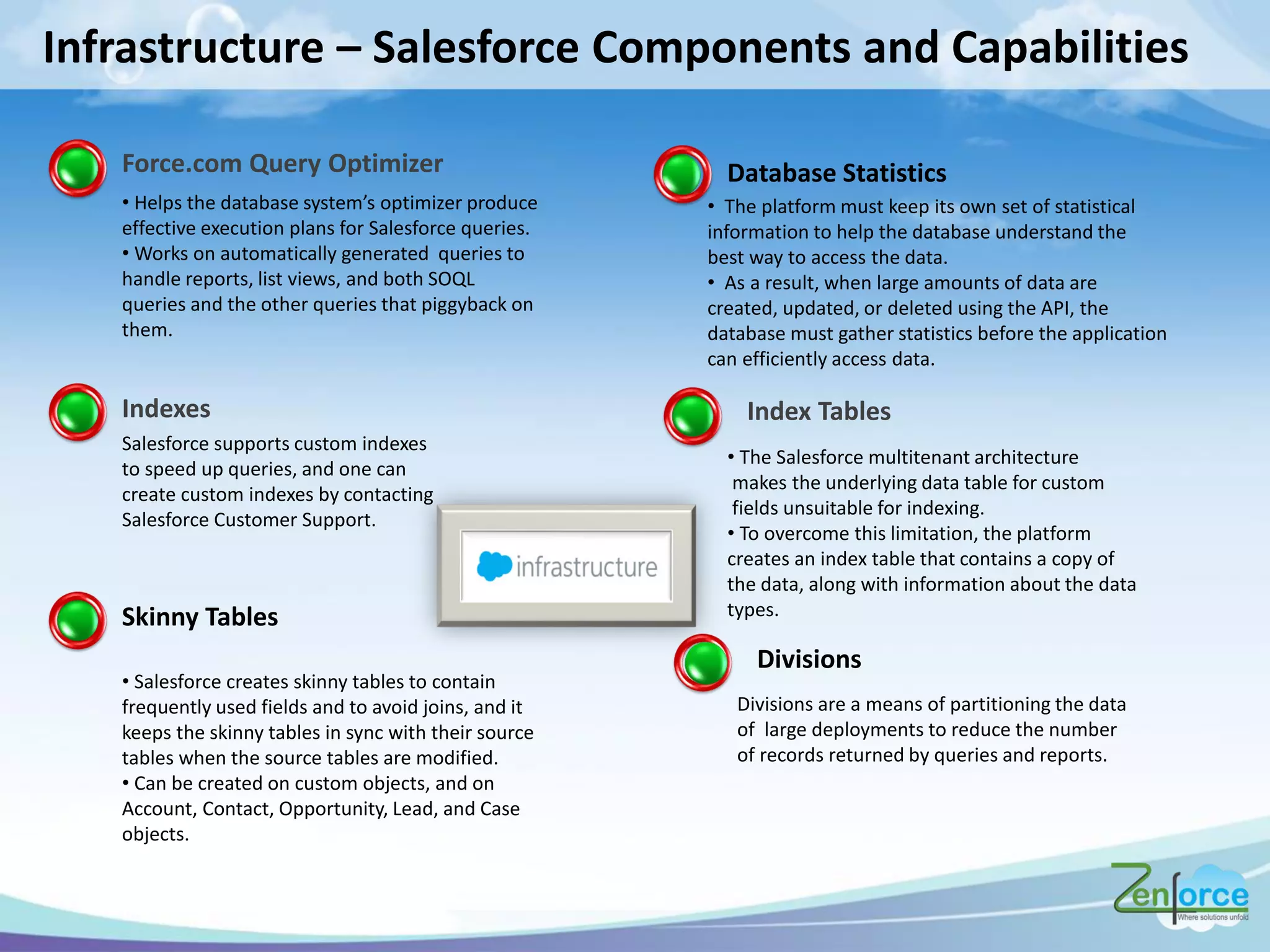
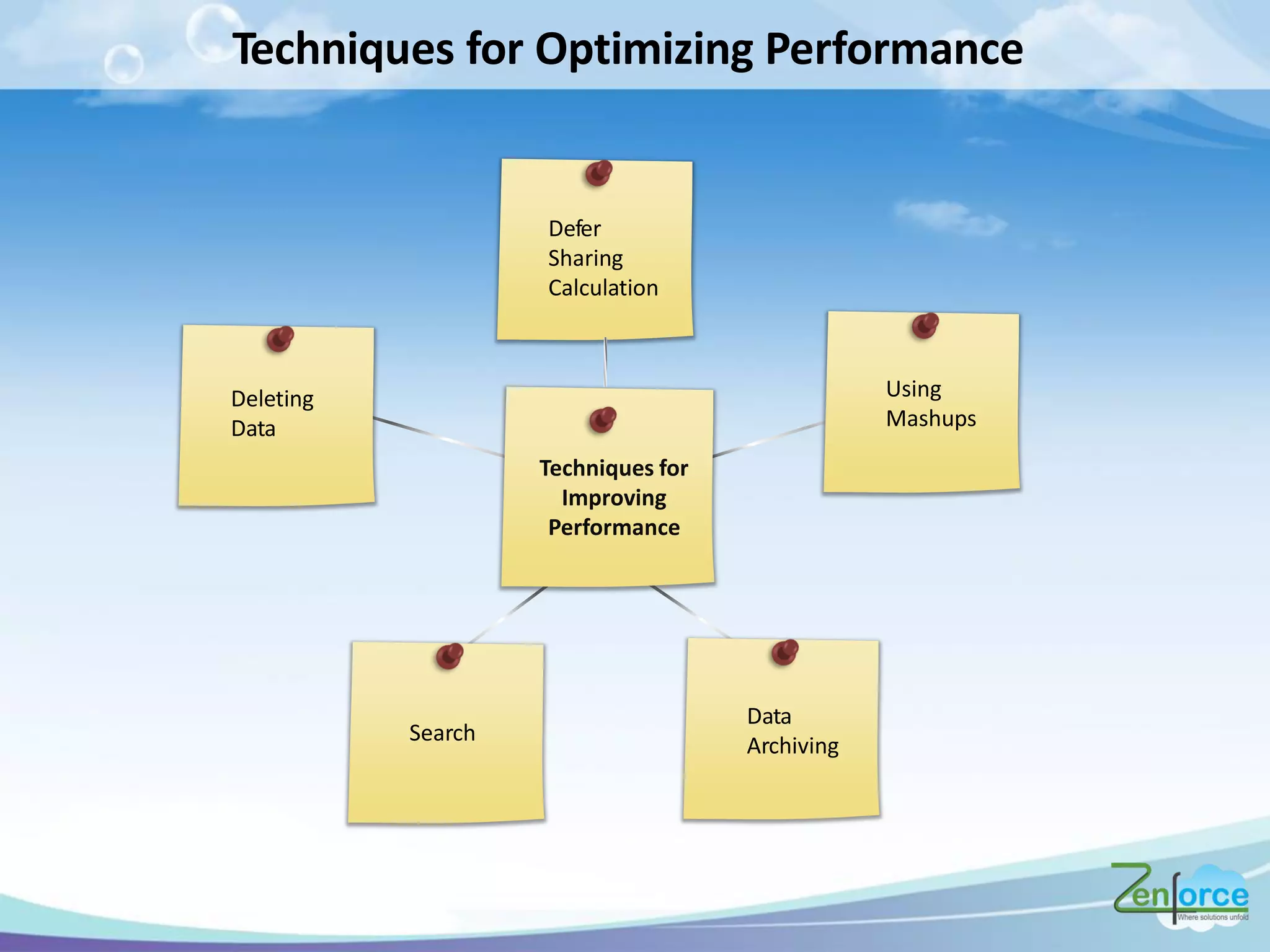


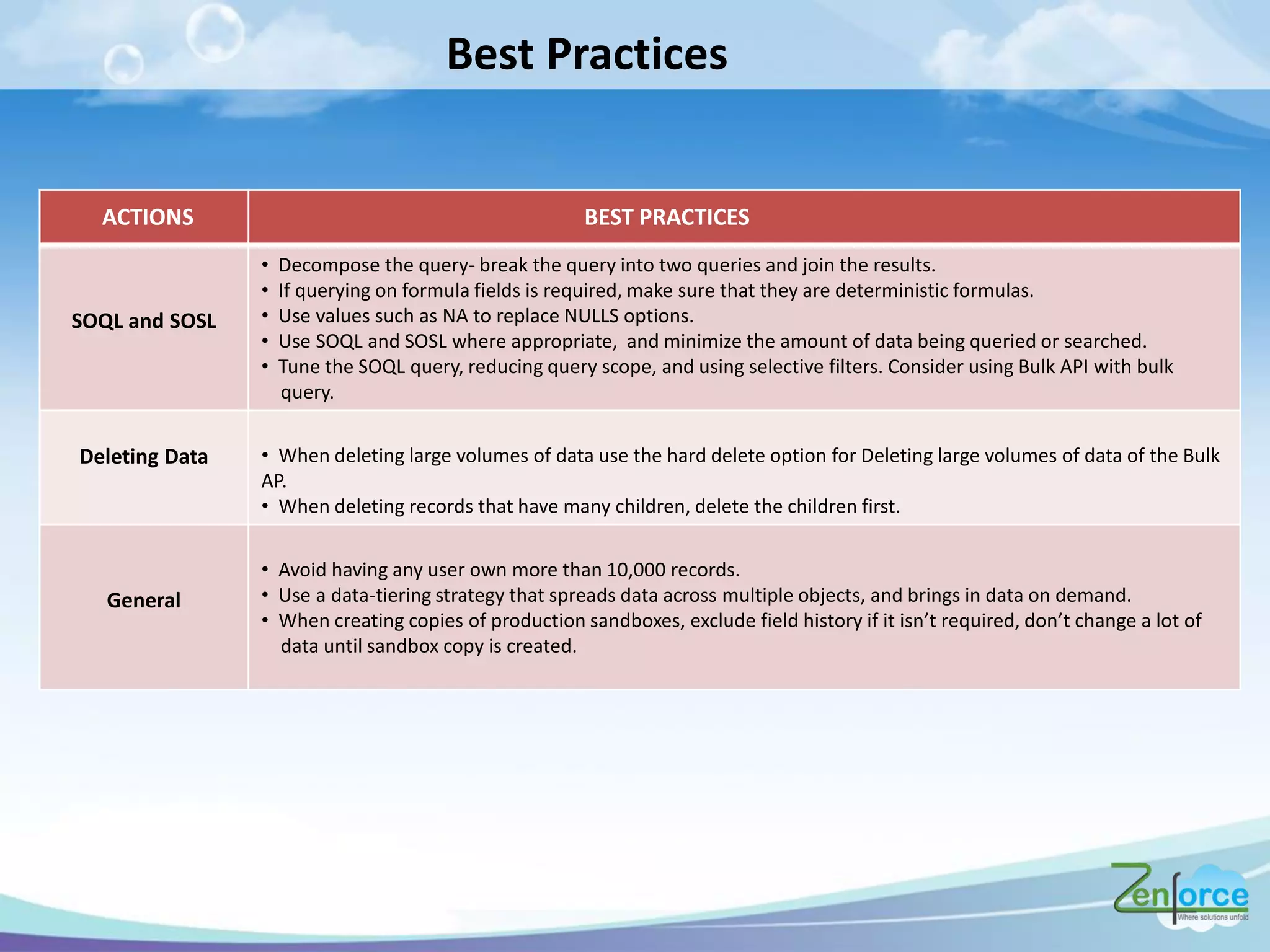


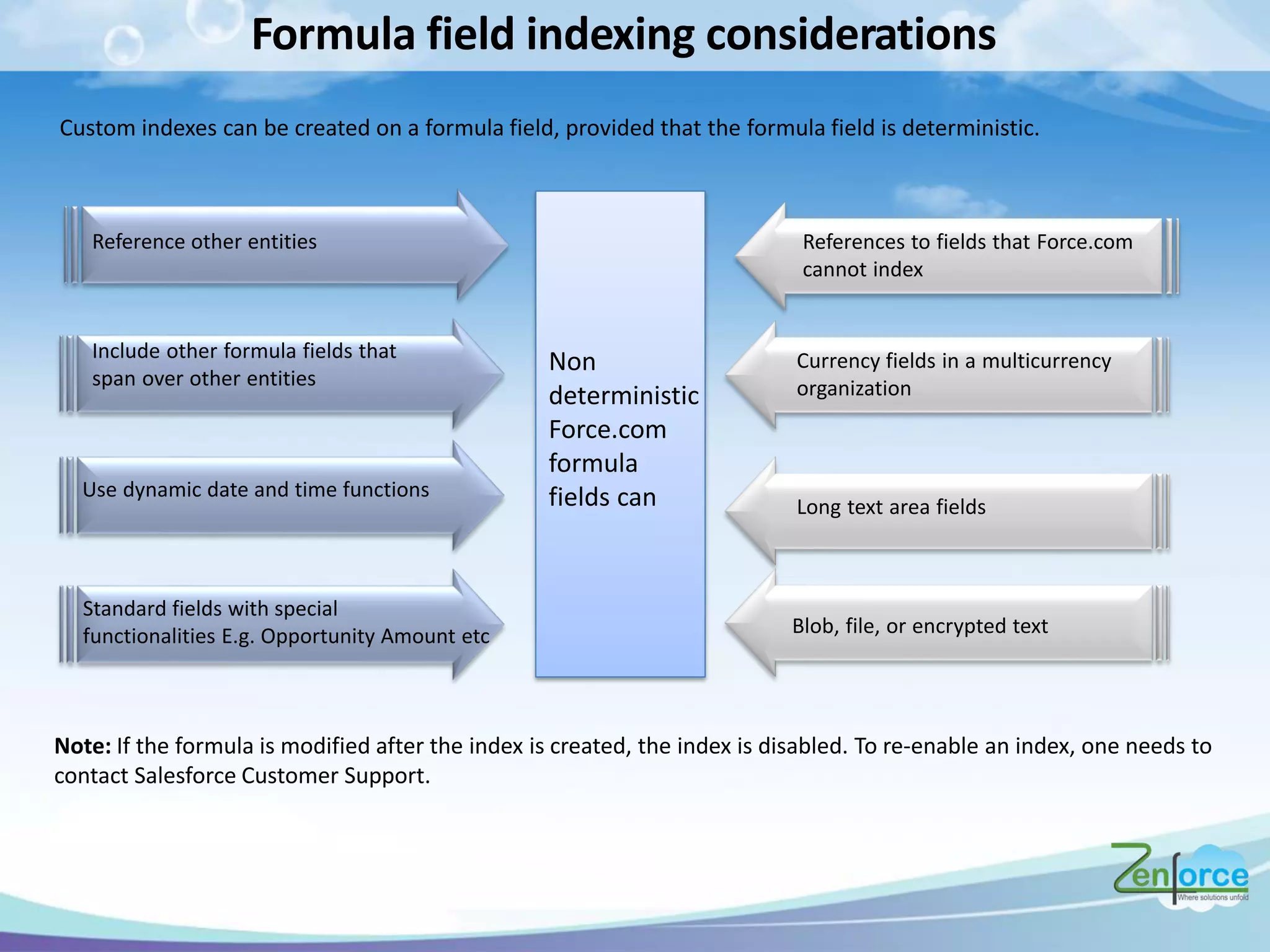
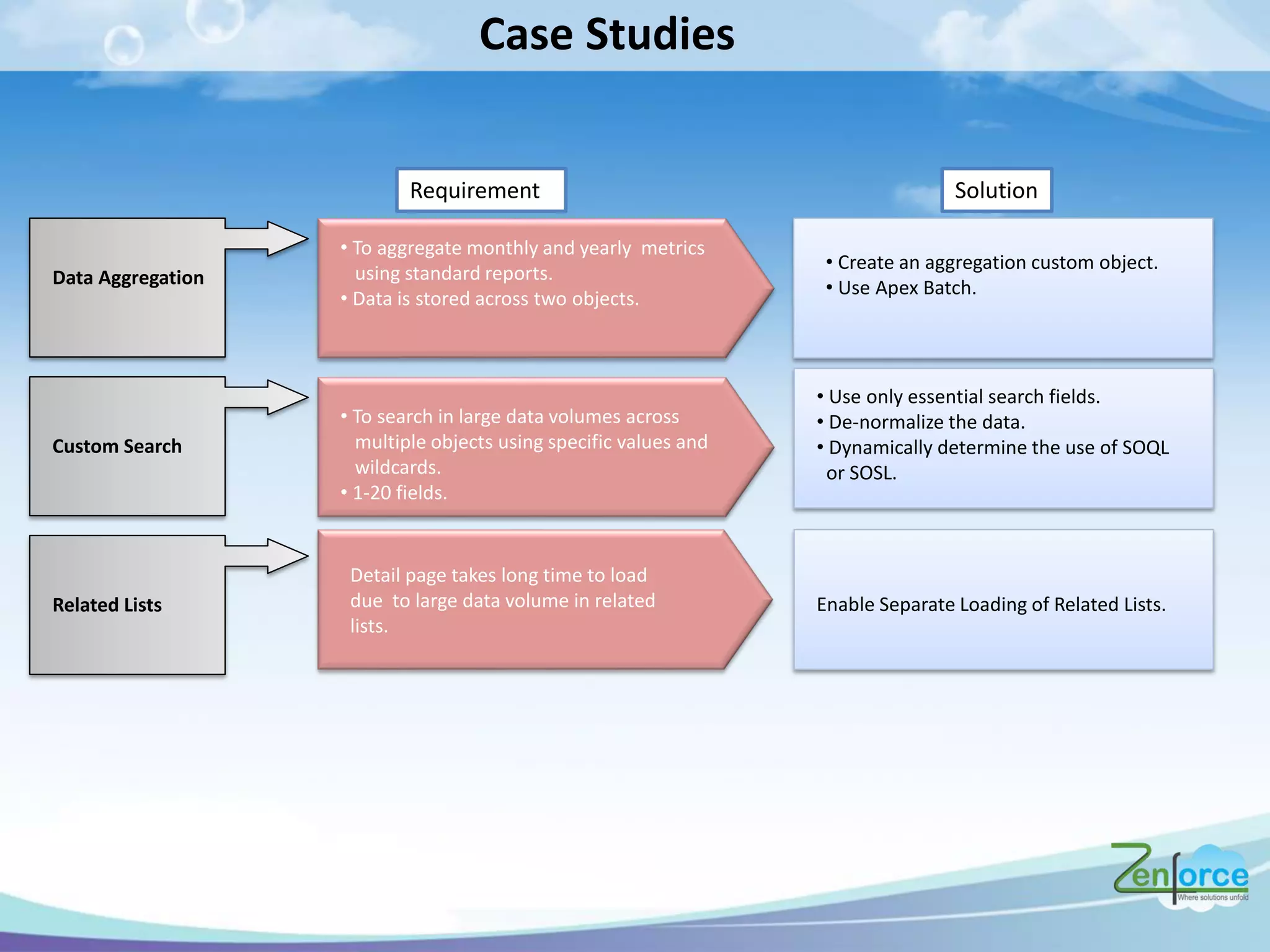
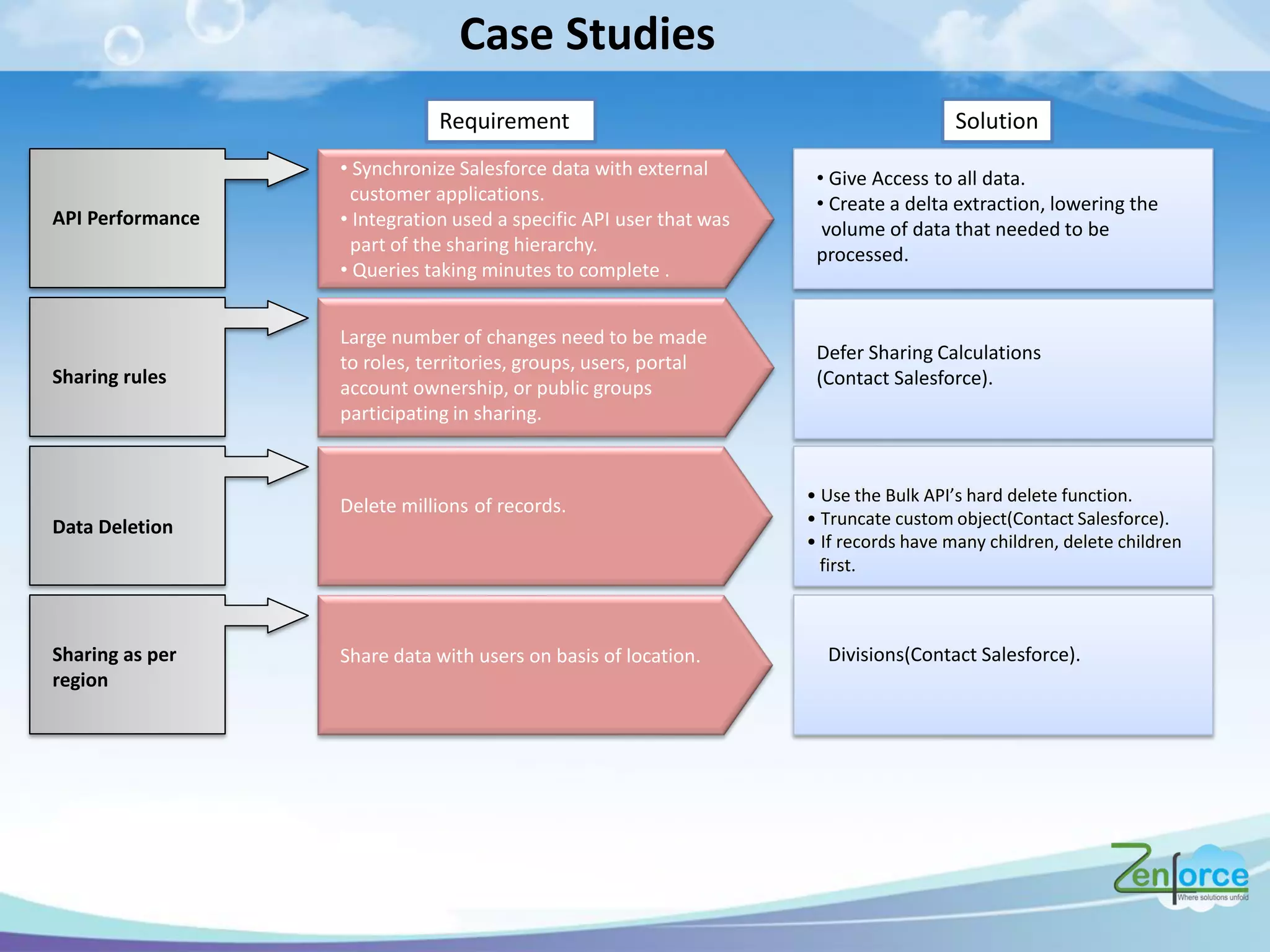
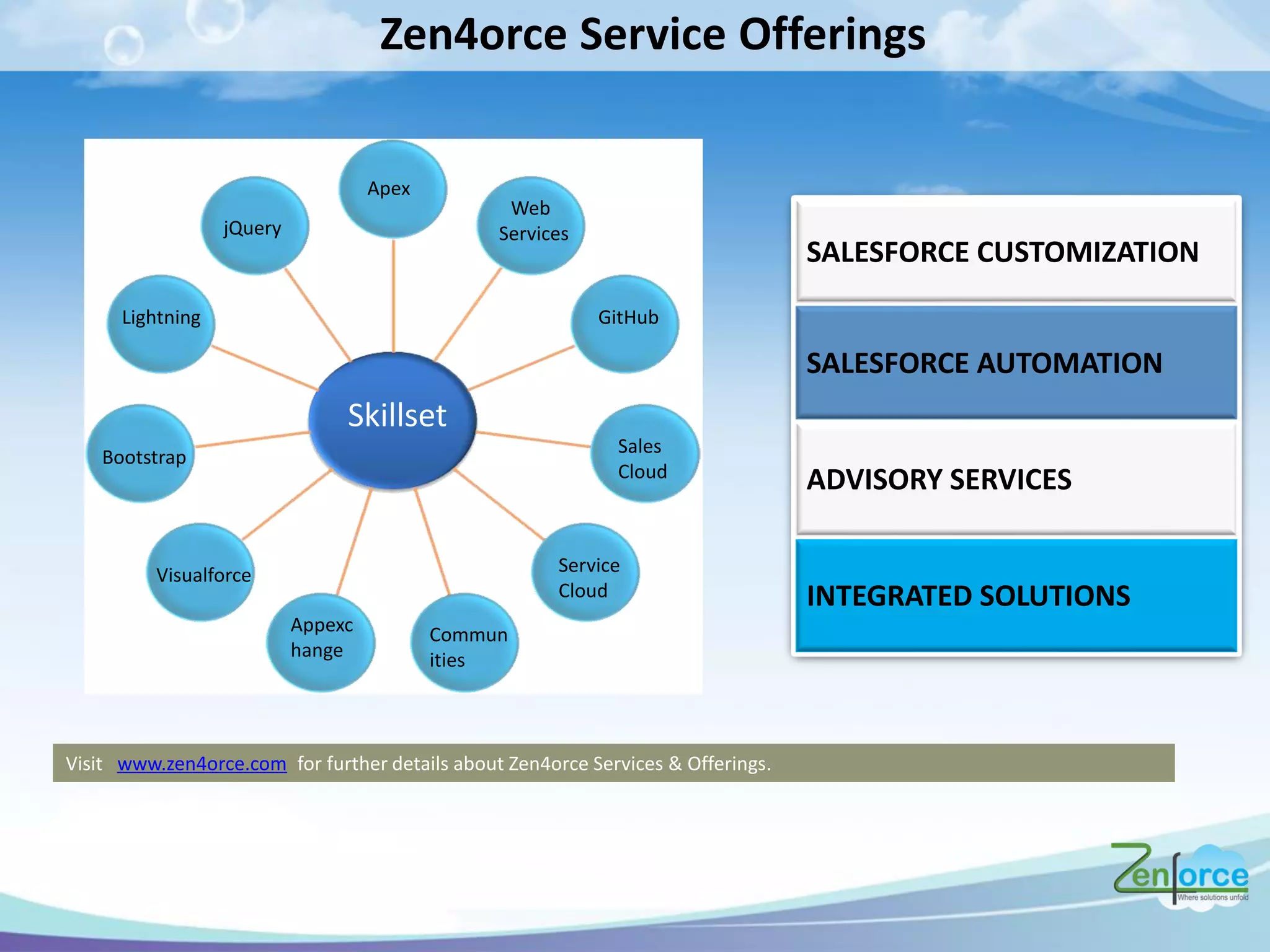

The document discusses how Salesforce handles large data volumes through its multitenant infrastructure, optimizing performance techniques, and best practices for data management. It covers key strategies like using custom indexes, employing the Salesforce bulk API for data operations, and reducing data complexity in queries. Several case studies illustrate successful implementations and considerations for performance improvements while managing large datasets.