Downloaded 288 times





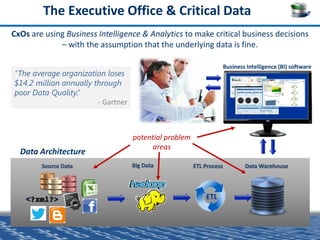

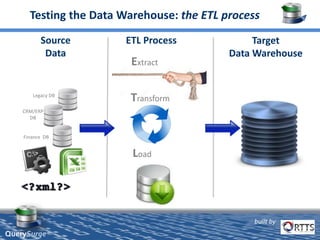
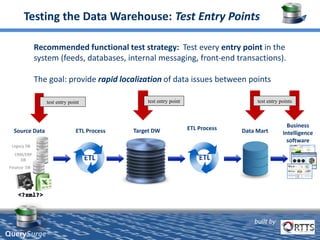


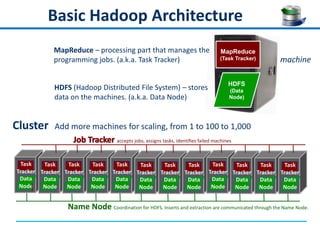
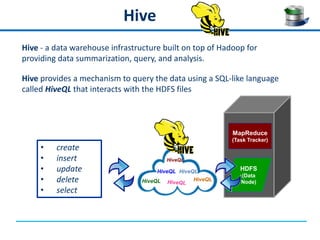
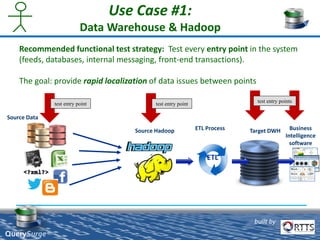
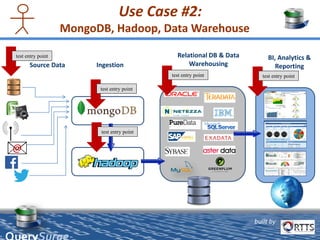







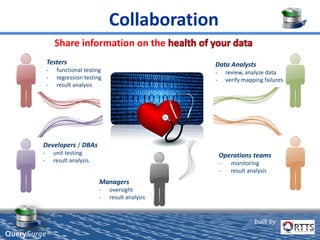
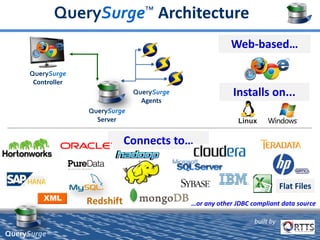
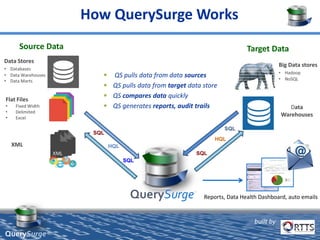

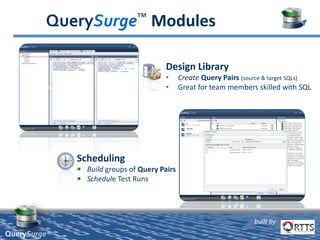


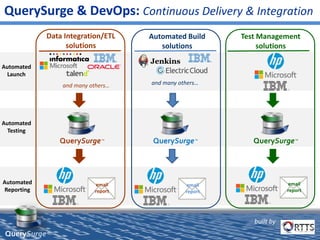











QuerySurge is an automated big data testing solution that enables enterprises to verify data quality without requiring coding expertise. It focuses on testing data warehouses and big data systems while addressing data quality issues that can lead to significant financial losses for organizations. The platform supports various data formats and integrates easily with existing software environments, offering functionalities like automated testing, reporting, and real-time data comparison.




































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)














