Downloaded 17 times




















![Building BetterTables
UsingThe Right DataTypes
DECLARE
@var1 CHAR(10) = 'abc',
@var2 NCHAR(10) = 'abc',
@var3 VARCHAR(10) = 'abc',
@var4 NVARCHAR(10) = 'abc'
SELECT
DATALENGTH(@var1) AS [char],
DATALENGTH(@var2) AS [nchar],
DATALENGTH(@var3) AS [varchar],
DATALENGTH(@var4) AS [nvarchar]](https://image.slidesharecdn.com/cfsummit2016-building-better-dbs-161114161238/85/Building-better-SQL-Server-Databases-30-320.jpg)
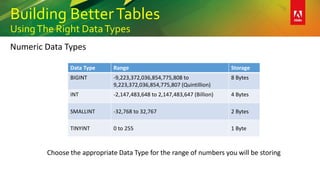








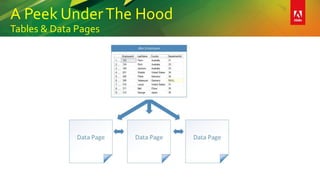
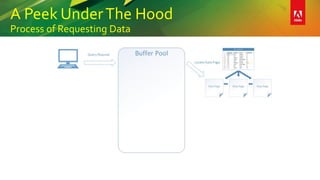
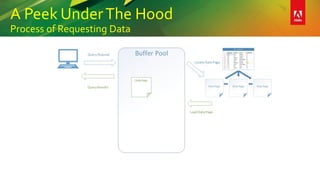
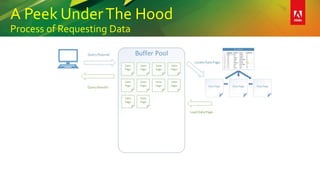
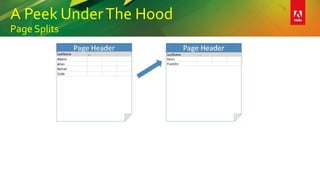
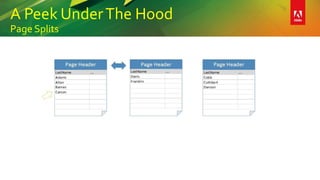
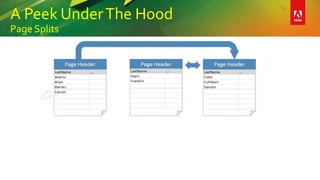
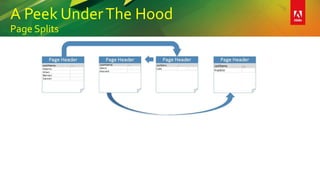
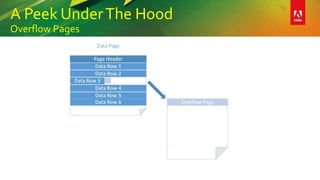
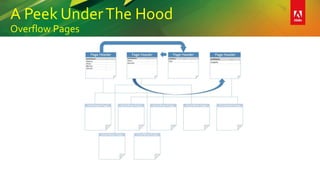
This document provides an overview of a presentation on building better SQL Server databases. The presentation covers how SQL Server stores and retrieves data by looking under the hood at tables, data pages, and the process of requesting data. It then discusses best practices for database design such as using the right data types, avoiding page splits, and tips for writing efficient T-SQL code. The presentation aims to teach attendees how to design databases for optimal performance and scalability.