The document discusses strategies for managing large data volumes in Salesforce, including:
- Using "skinny tables" to combine standard and custom fields to improve performance.
- Creating indexes on fields used in queries to optimize search.
- Partitioning data using "divisions" to separate large amounts of records.
- Maintaining large external datasets through "mashups" to reduce the data in Salesforce.
- Avoiding "ownership skew" and "parenting skew" to prevent a single owner or parent from impacting performance.
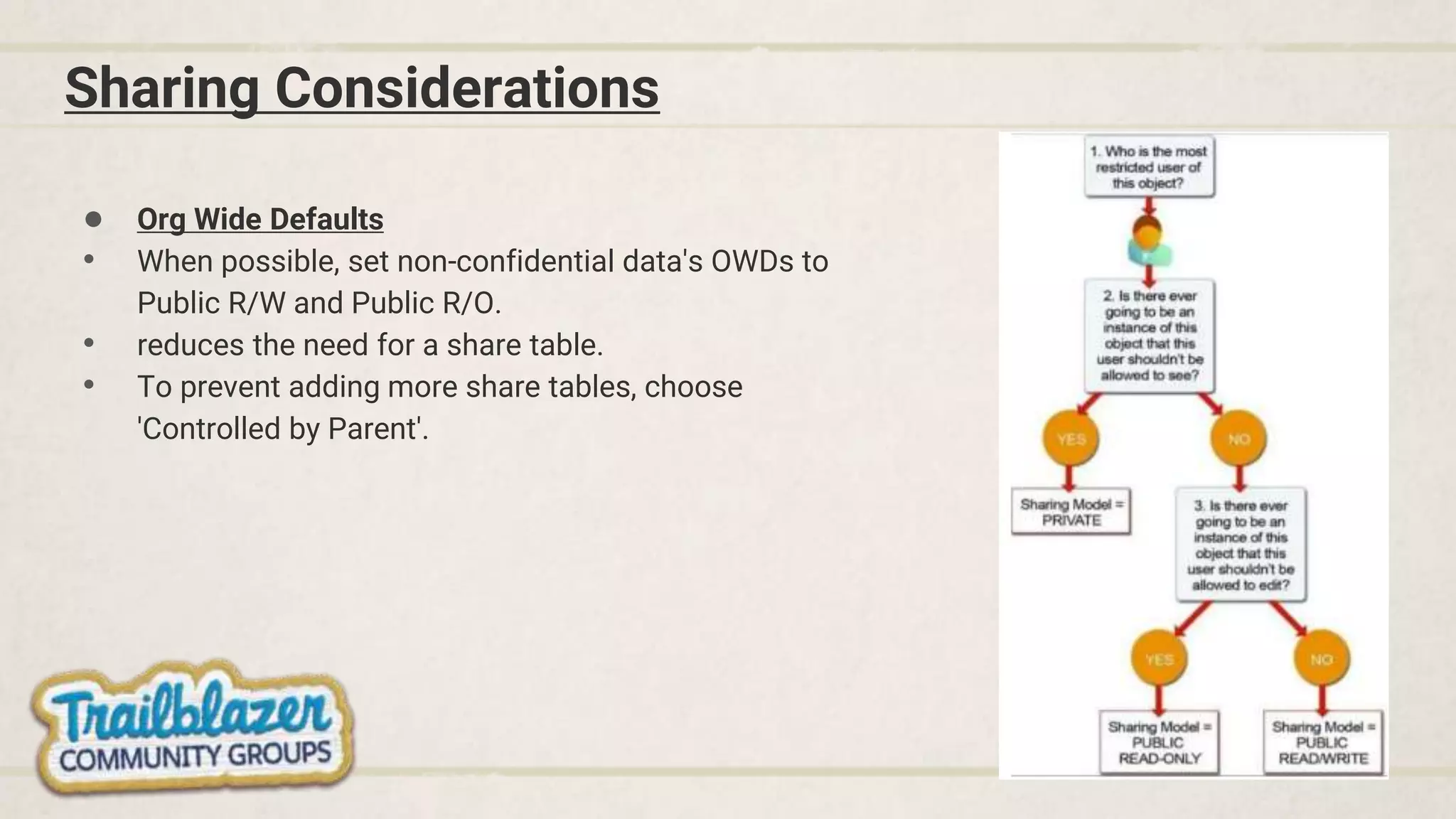
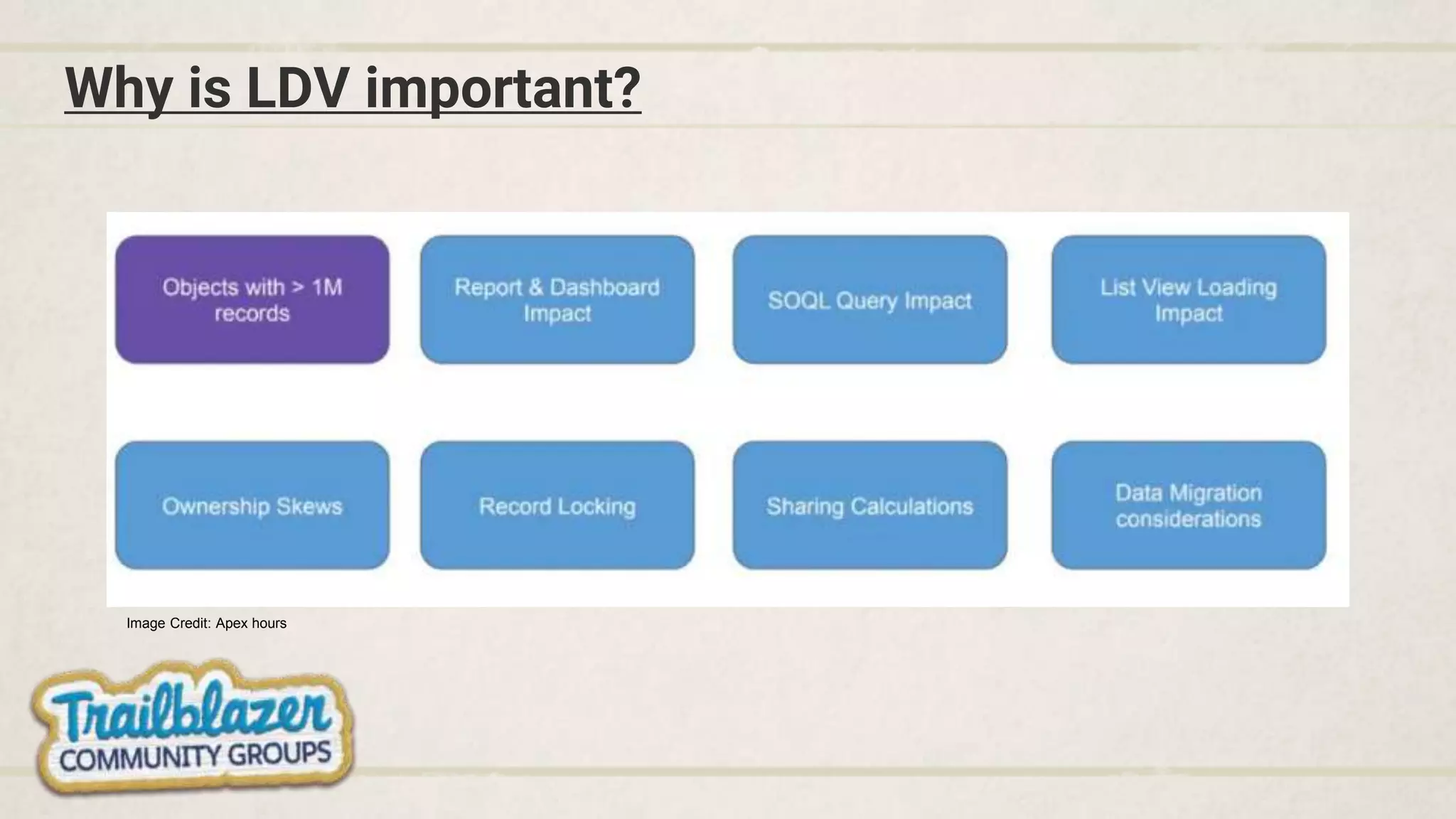
- Considering data sharing, load strategies, and archiving techniques when dealing with large volumes.







![Indexing Principles
What is an index?
• Sorted column or
column
combination that
uniquely identifies
rows of data.
• The index contains
sorted columns as
well as references
to data rows.
Example
• Created index on ID
field
• [SELECT * FROM
Table WHERE ID <
14]
• Query uses the
Sorted ID(Index)
column to quickly
identify data rows
• Query does not
need to do full table
scan to fetch rows](https://image.slidesharecdn.com/ldv-azlanallahwala2-221103142722-998dfb83/75/LDV-v2-pptx-9-2048.jpg)