Download as PDF, PPTX




















The document outlines AWS services that accelerate data preparation for machine learning, detailing the capabilities of AWS Glue and Amazon SageMaker for integrating and processing data efficiently. It emphasizes the transition from traditional data warehousing to modern data architectures, including lake house models for scalable analytics and machine learning. AWS Glue offers serverless integration and data transformation tools, while SageMaker simplifies the machine learning workflow, making it accessible for analysts and data scientists.
Overview of AWS data preparation for ML pipelines. Speaker: Francesco Marelli, AWS Solutions Architect.
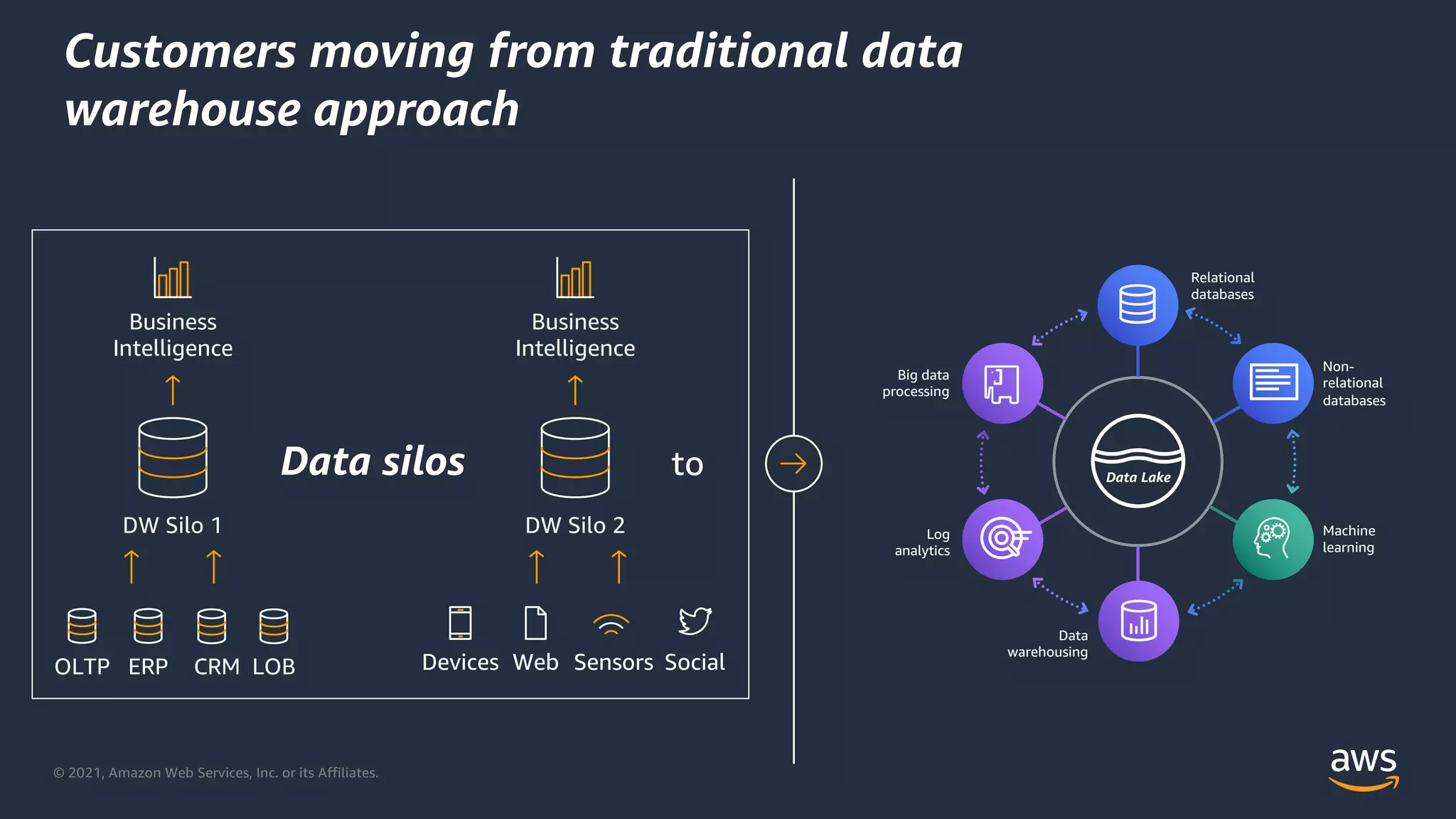
Shift from traditional data warehouses to integrated solutions using cloud technologies.
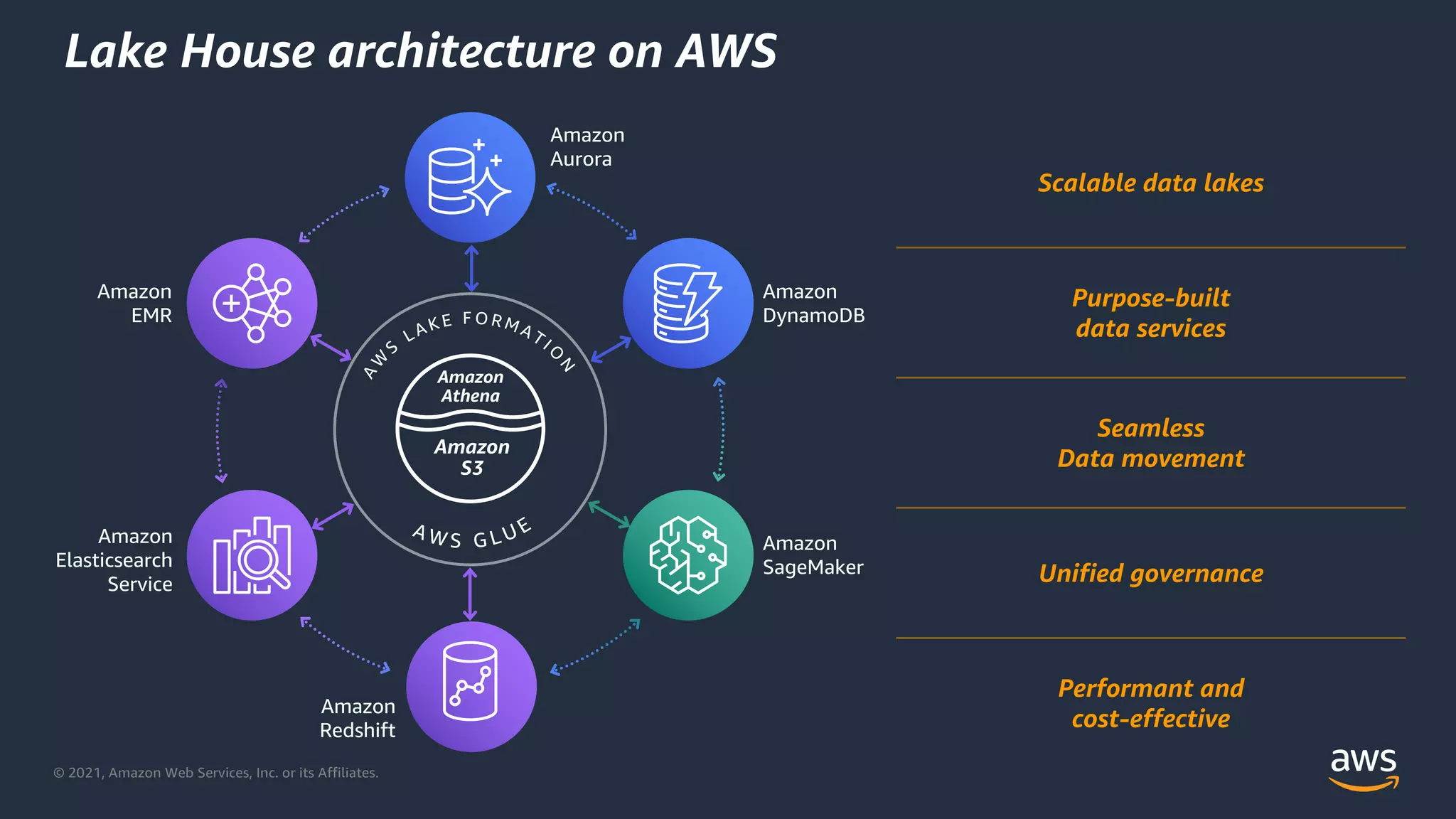
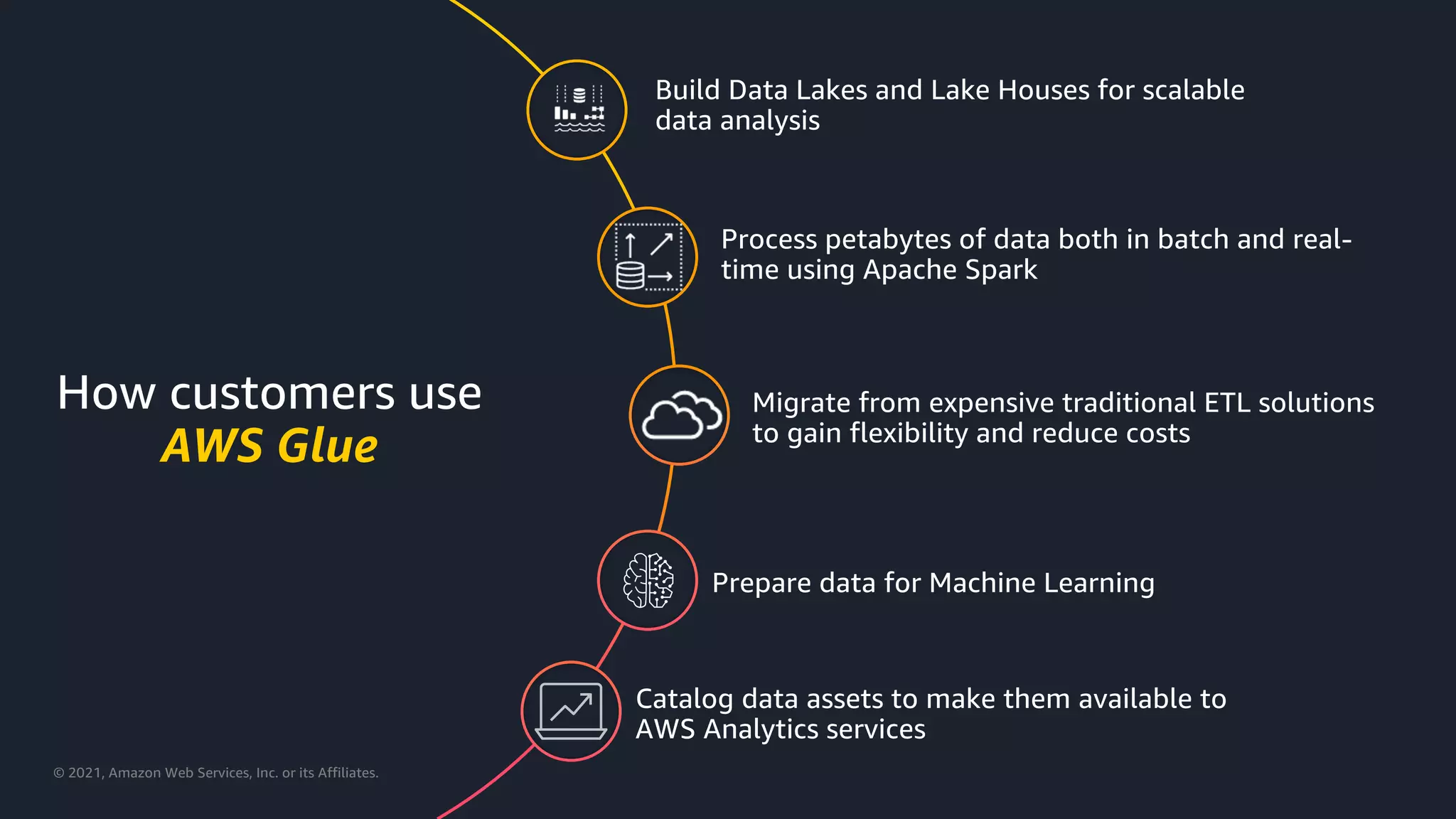
Introduction to Lake House architecture on AWS, emphasizing scalable data lakes and data services.
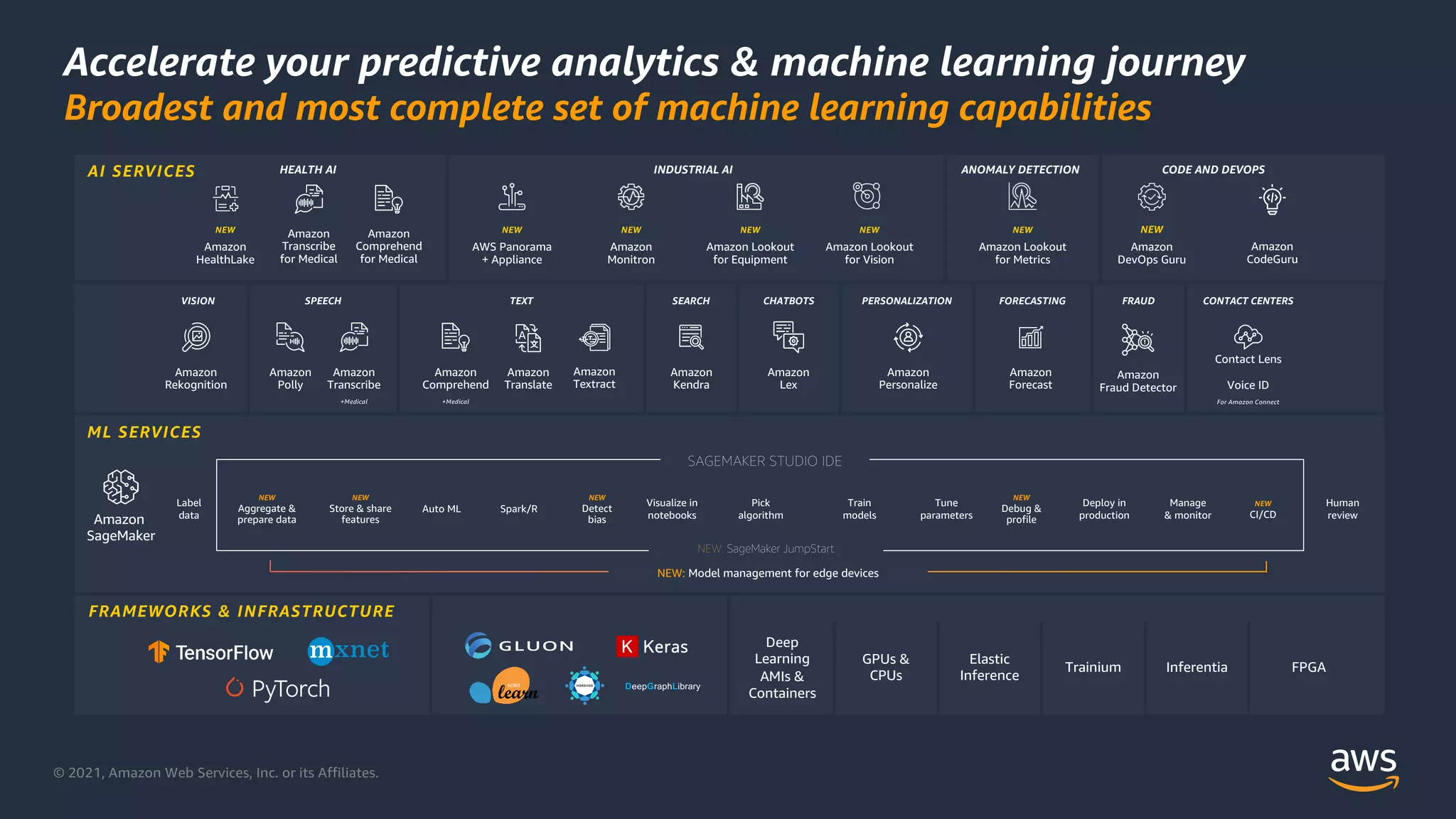
Overview of AWS analytics services including data movement, analytics, and machine learning capabilities.
Comprehensive ML capabilities in AWS, featuring services like SageMaker and tools for various AI applications.
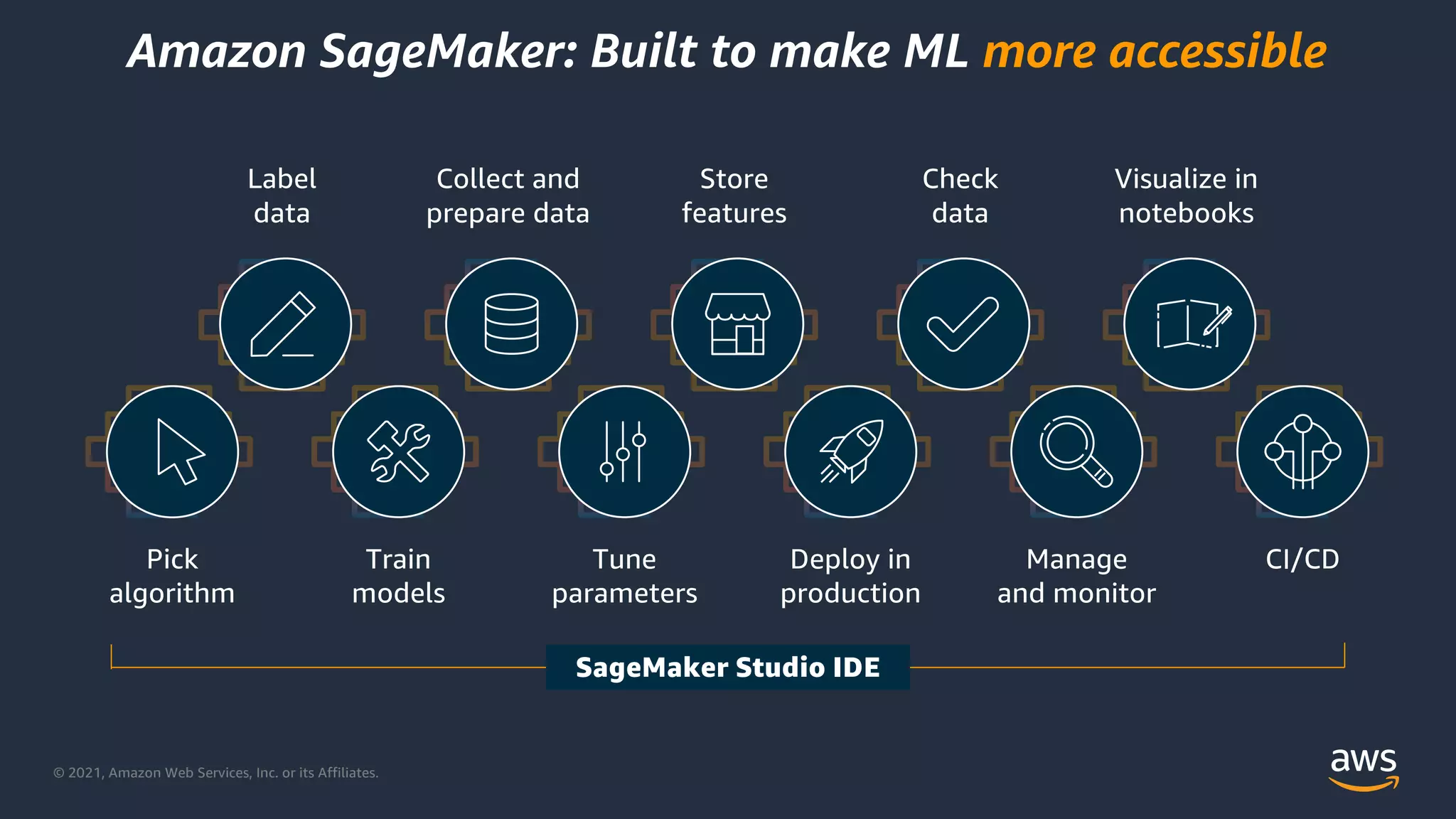
Features of Amazon SageMaker including data preparation, model training, and monitoring capabilities.
AWS Glue as a serverless data integration tool for complex workloads and its cost benefits.
Practical uses of AWS Glue for machine learning data preparation and building data lakes.
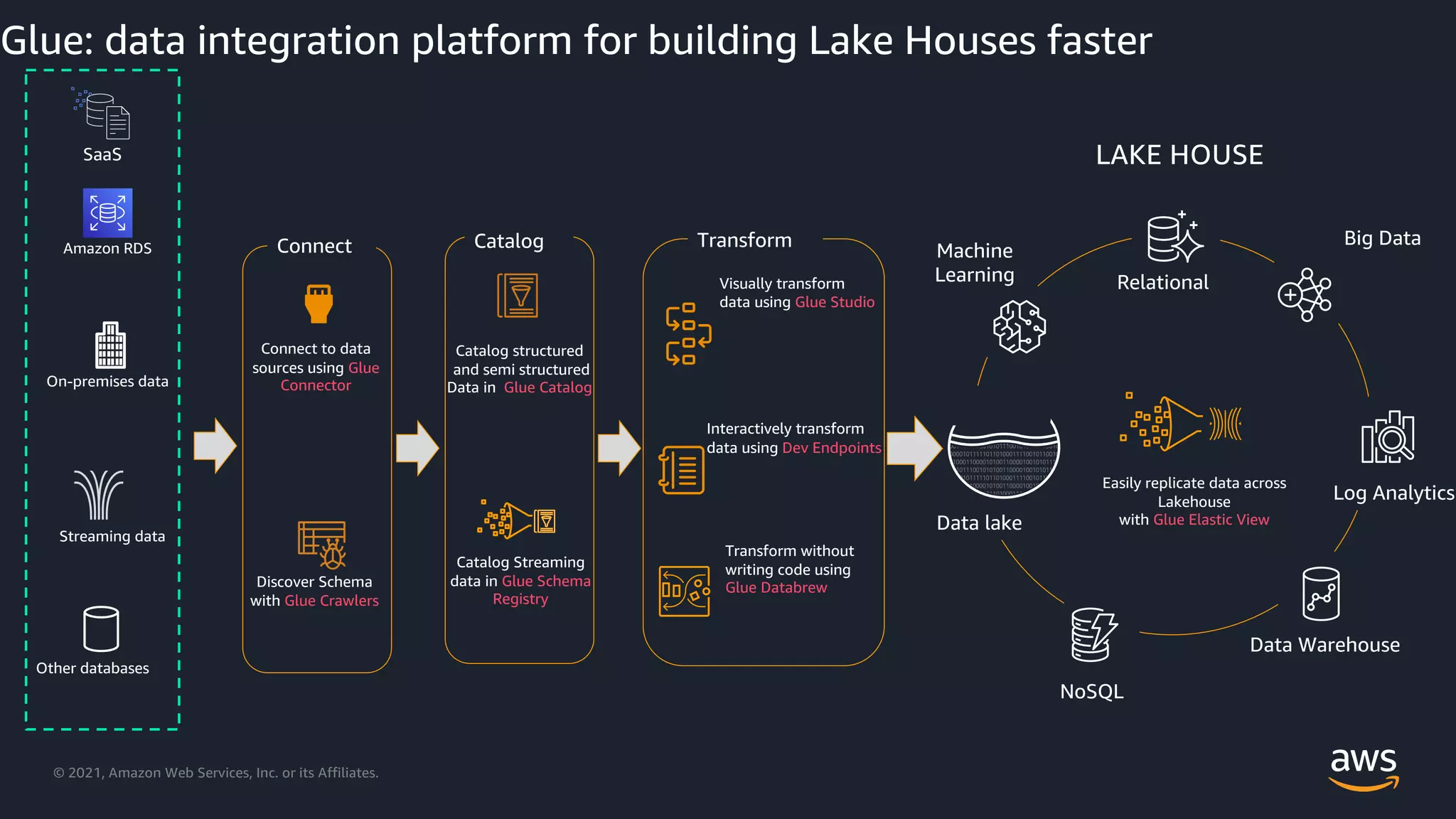
Utilizing AWS Glue to connect, catalog, and transform data across Lake Houses.
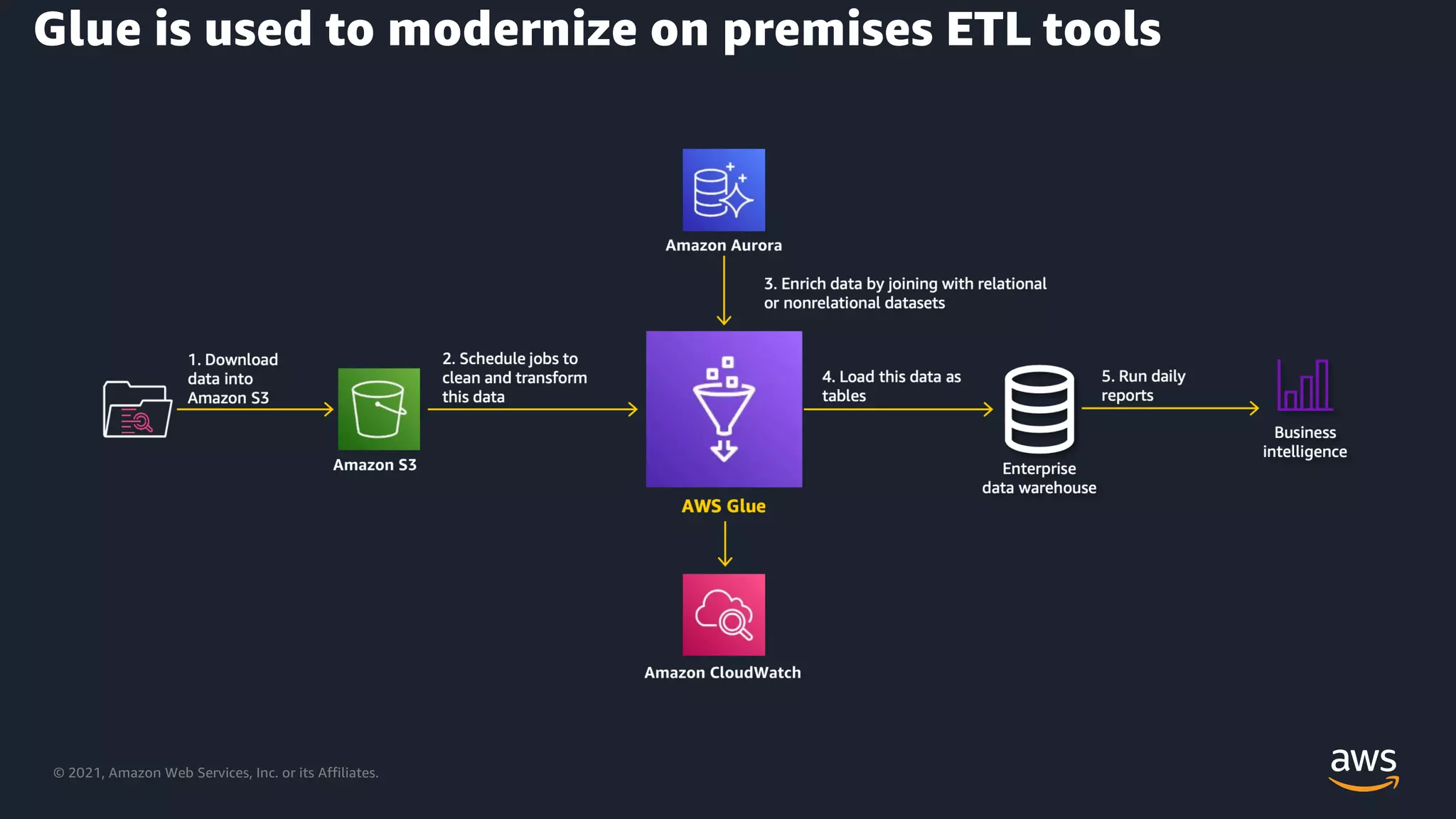
AWS Glue’s application in modernizing traditional on-premises ETL tools.
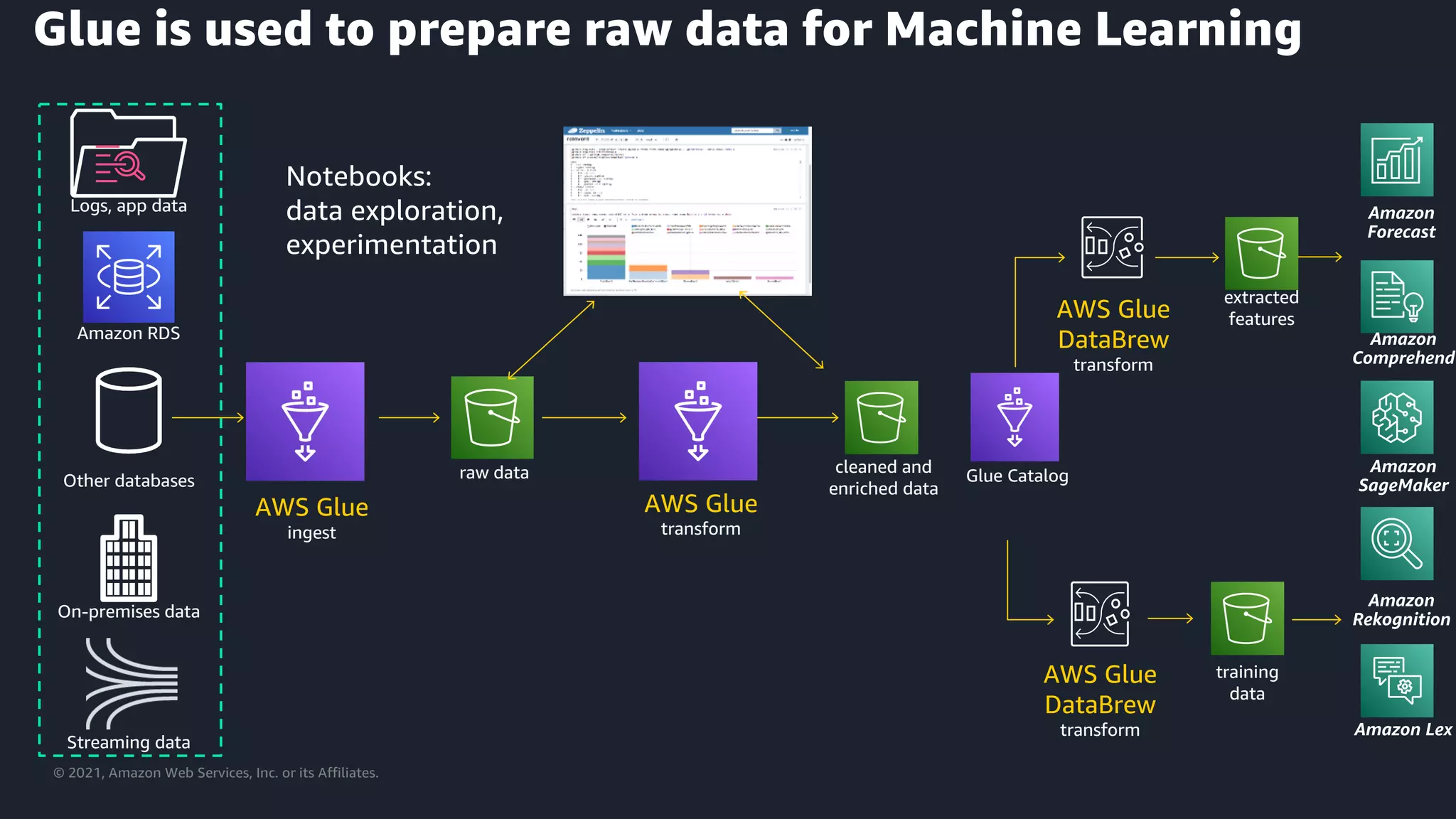
Utilizing AWS Glue for cleaning and preparing raw data for machine learning applications.
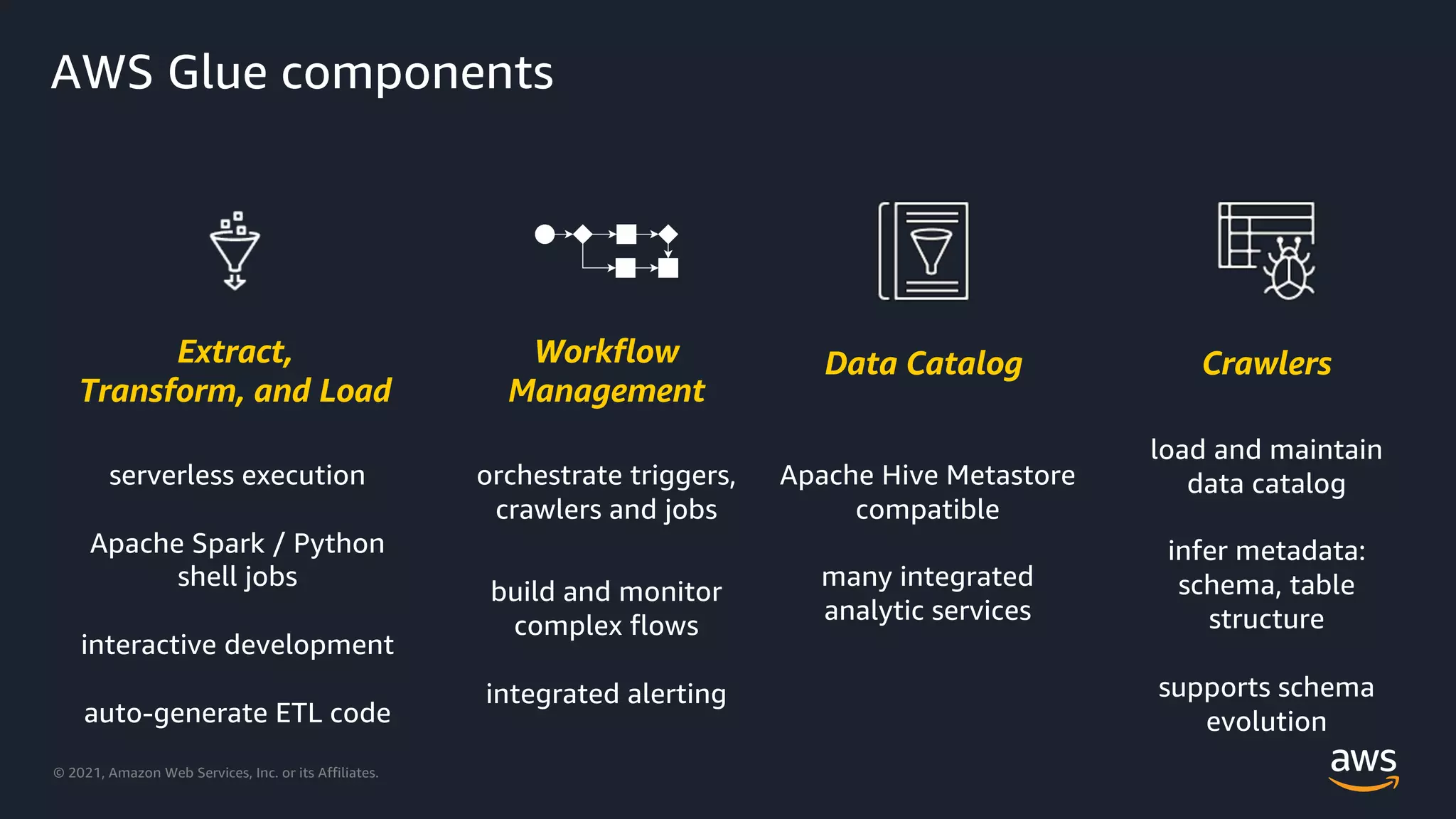
Explanation of AWS Glue components including crawlers, data cataloging, and ETL processes.
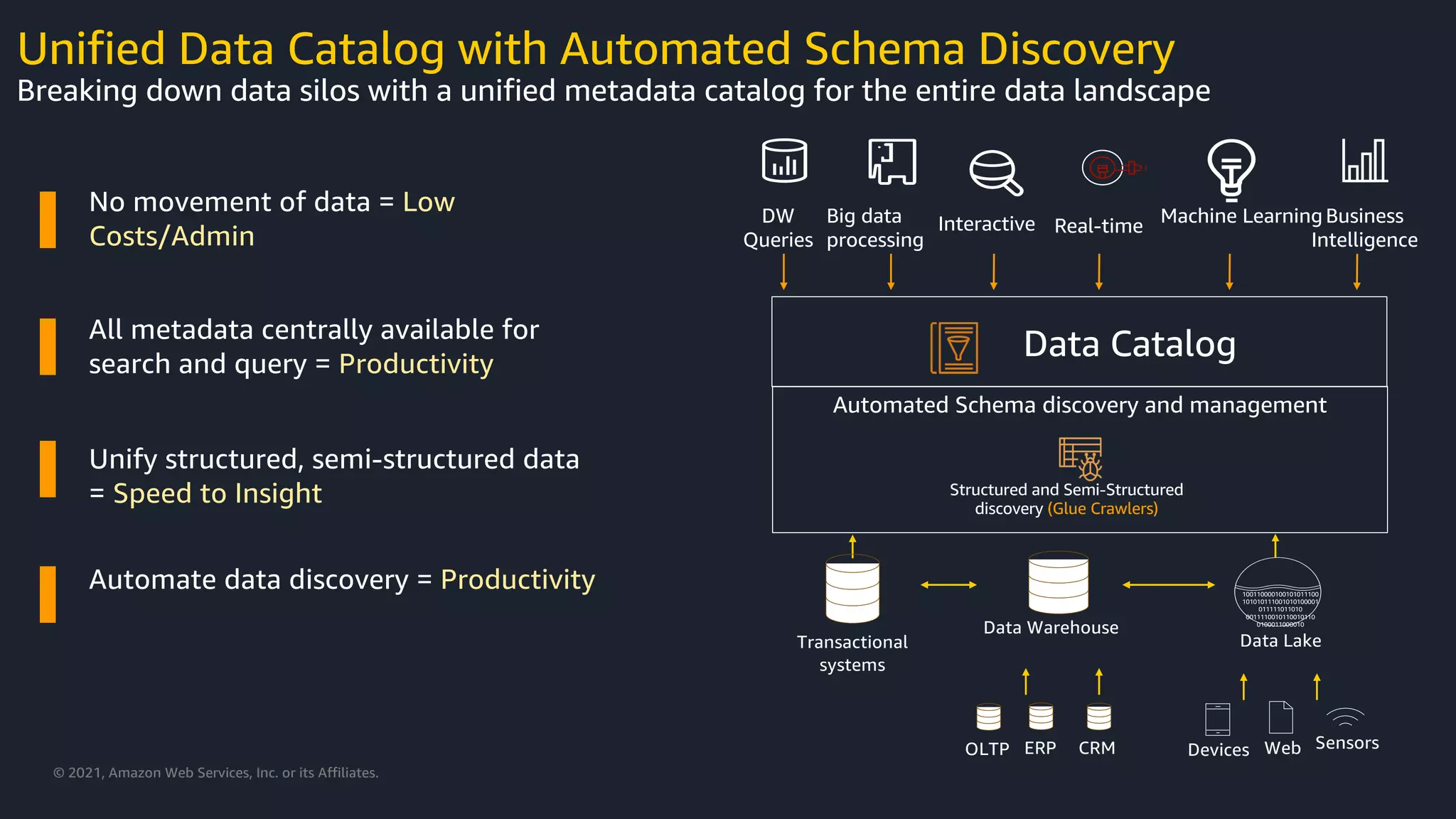
Benefits of a unified data catalog in breaking data silos and enhancing productivity through metadata management.
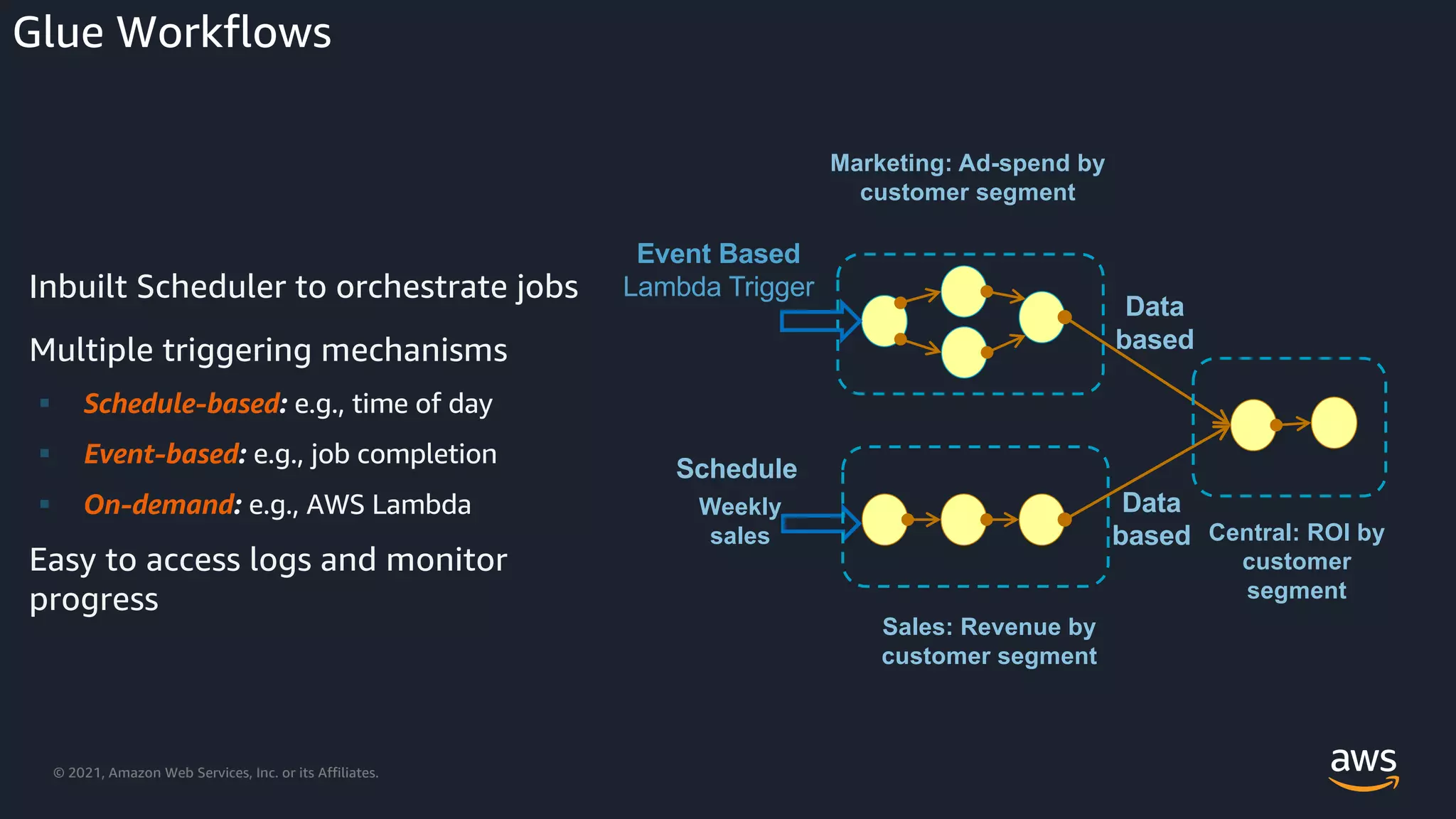
Overview of AWS Glue workflows and job orchestration capabilities.
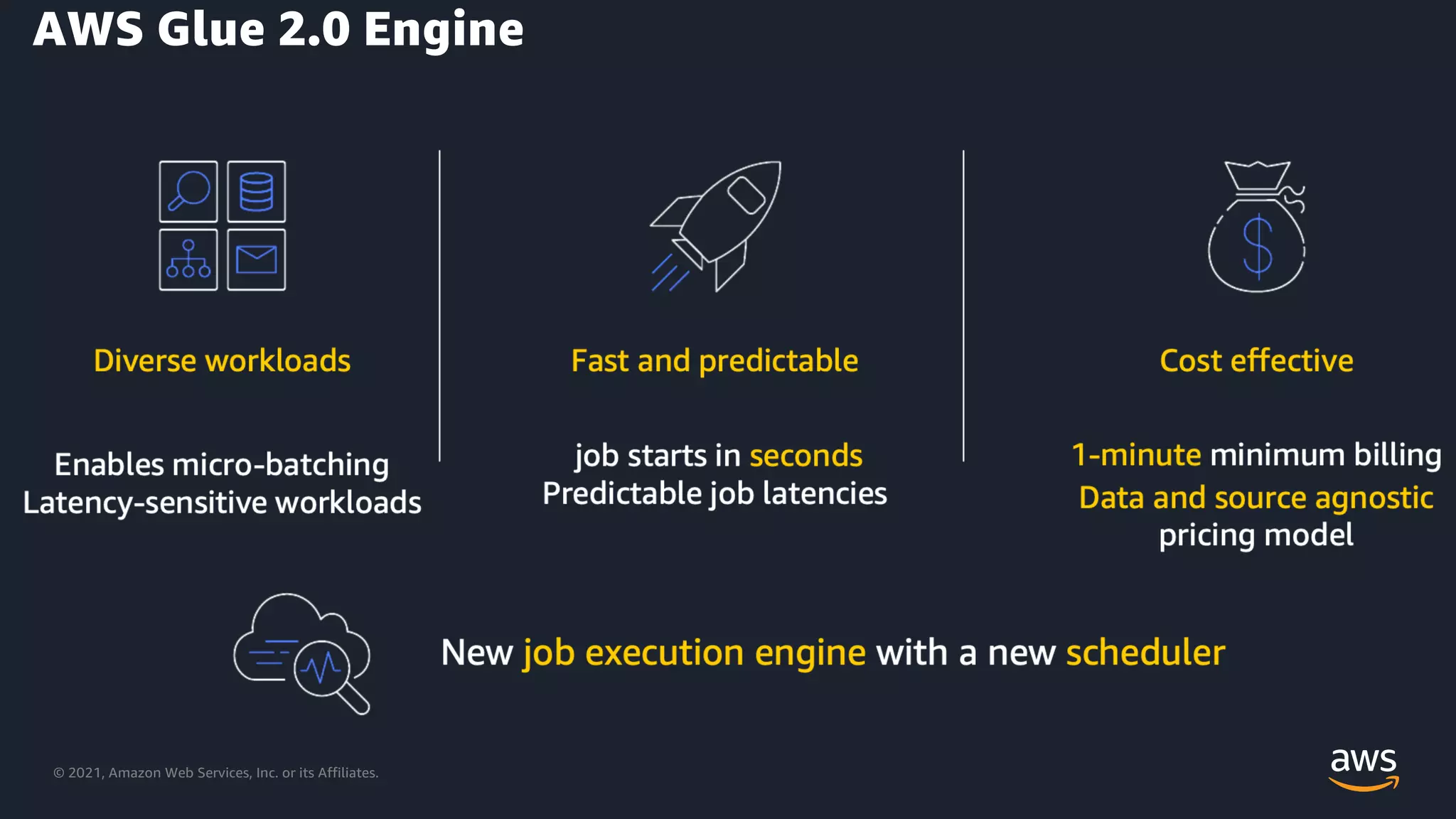
Feature enhancements in AWS Glue 2.0 for improved performance and operational efficiency.
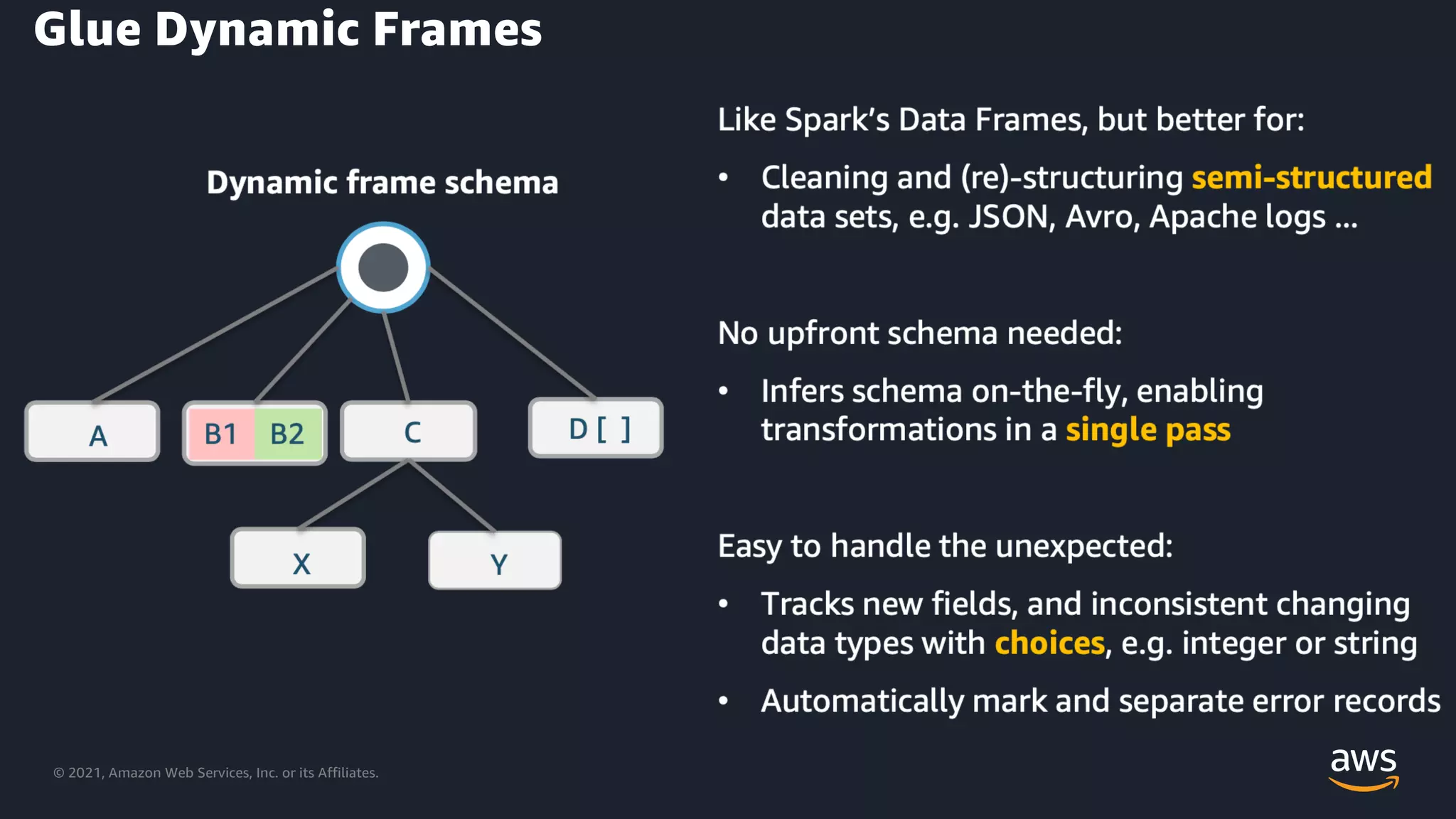
Introduction to Glue Dynamic Frames for flexible data transformation.
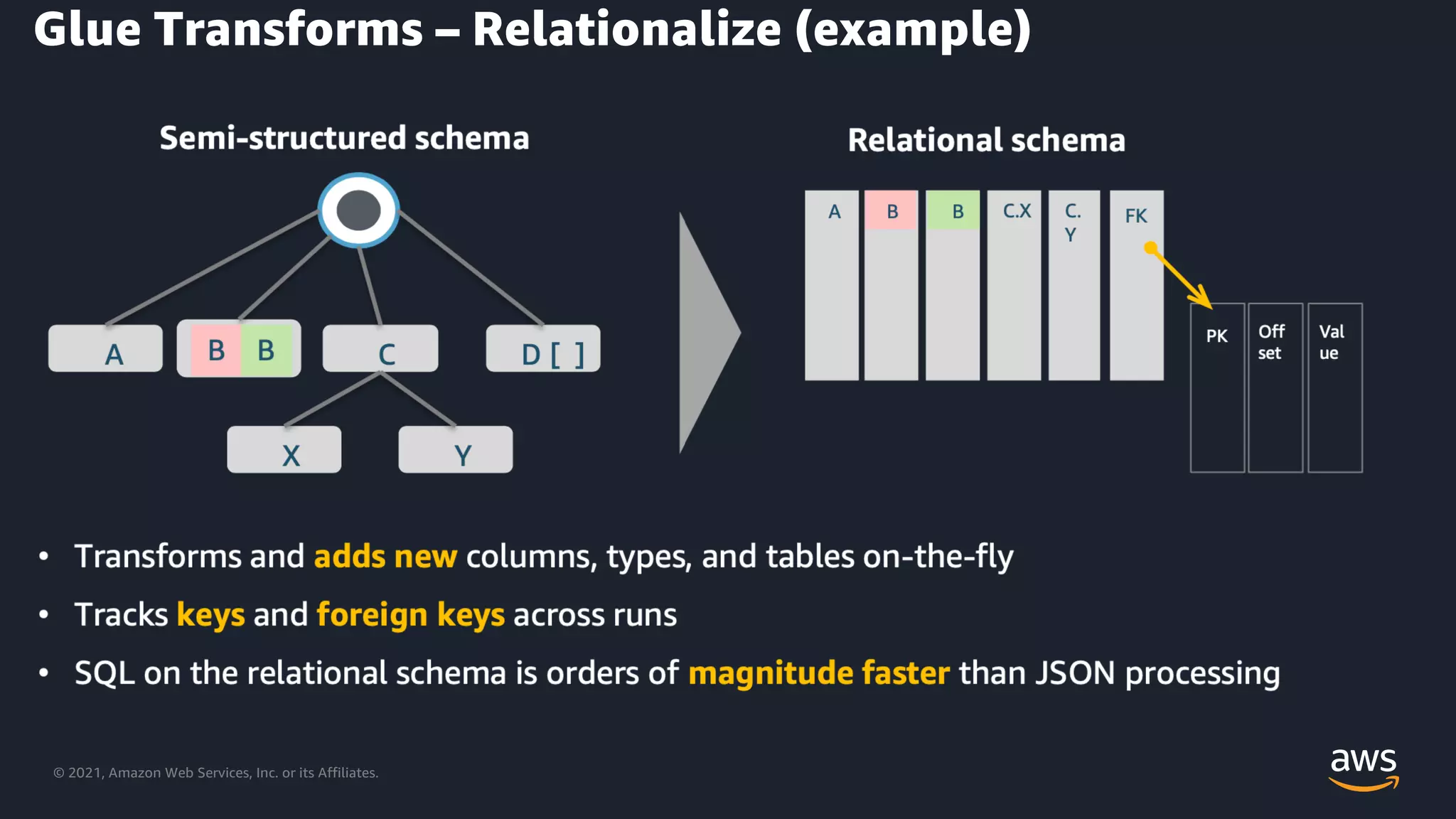
Explains transforming data into relational formats using AWS Glue transforms.
Details on AWS Glue connectors to integrate various data sources efficiently.
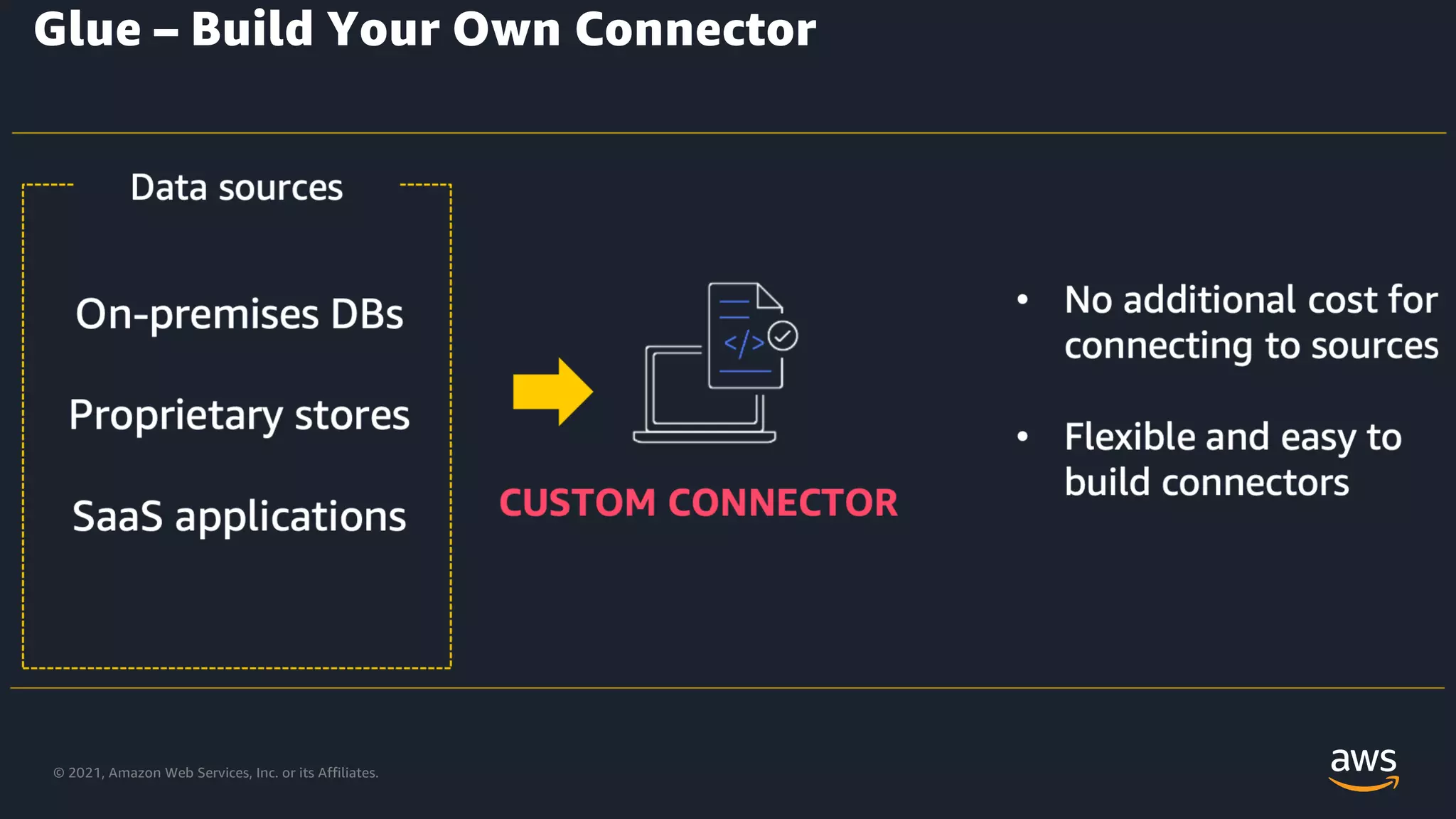
Building custom connectors in AWS Glue for specific data integrations.
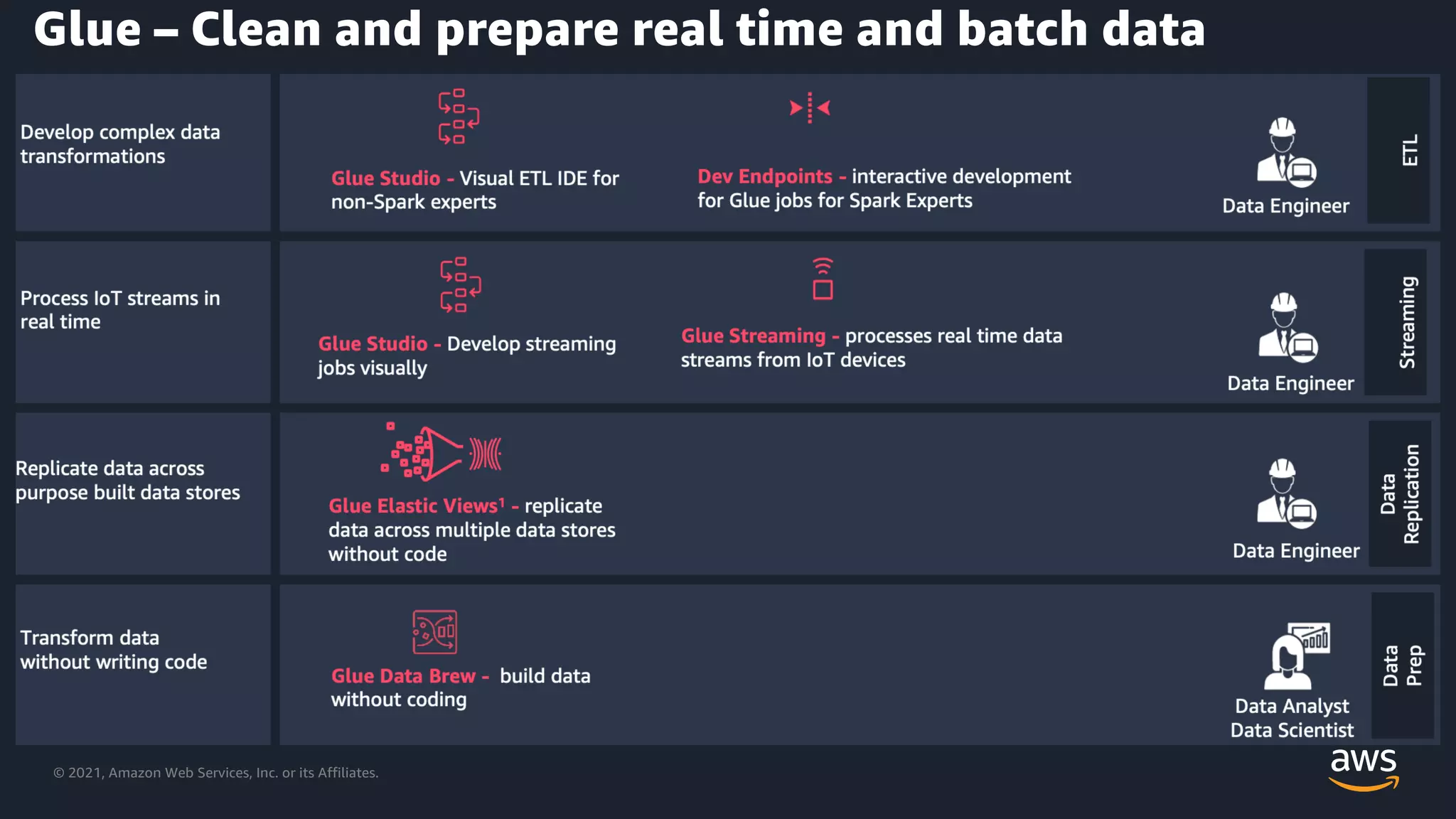
Capabilities of AWS Glue in cleansing and preparing both real-time and batch data.
Introduction and demo of AWS Glue Studio as a visual interface for creating and monitoring ETL jobs.
Demonstration of the AWS Glue Studio interface and its capabilities.
Common issues teams face in data preparation including repetitive tasks and inefficiencies.
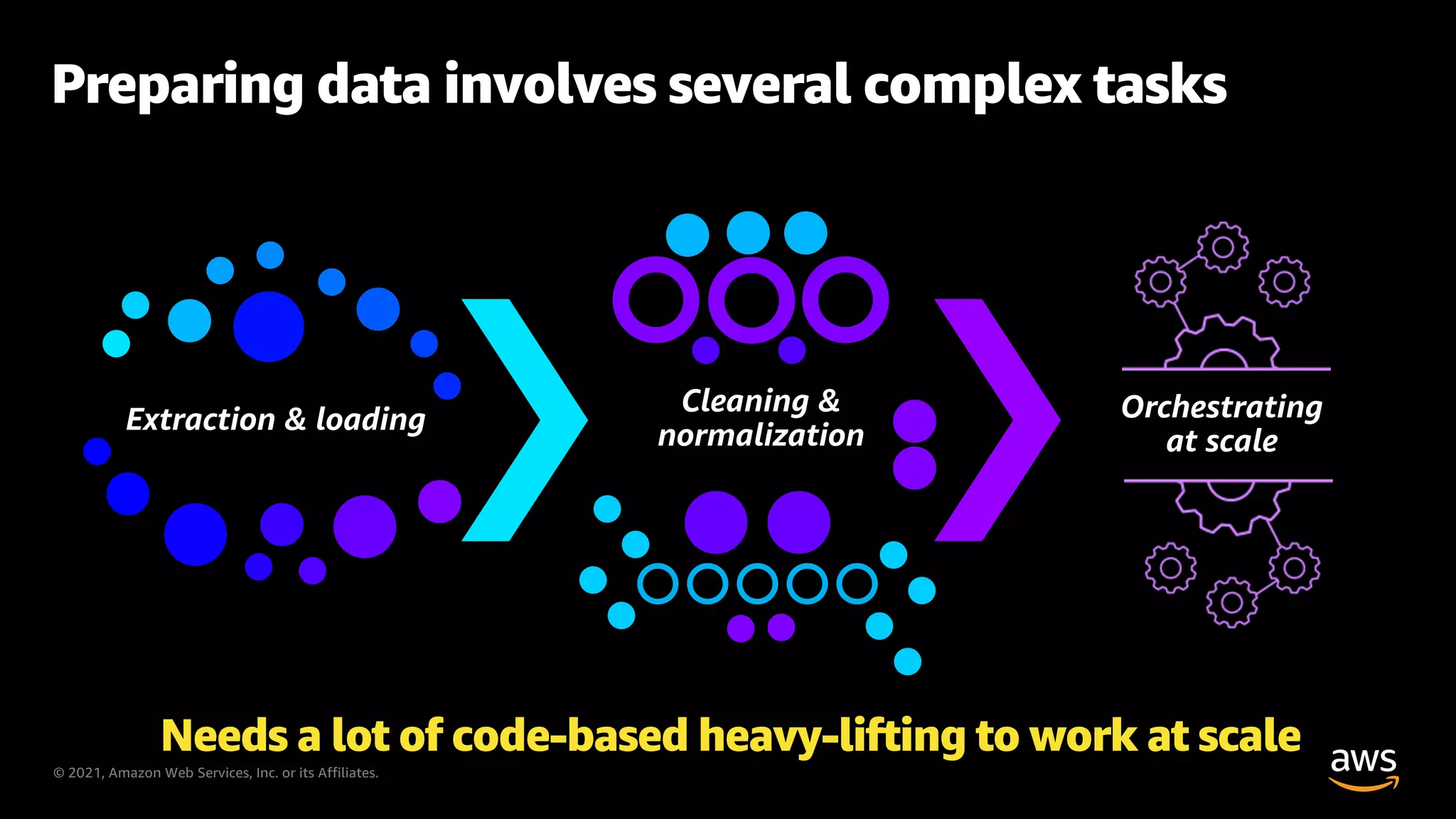
Overview of the complexity involved in data preparation tasks and the need for efficient tools.
Statistics indicating that up to 80% of time is spent on data preparation tasks.
Challenges associated with traditional data preparation methods including time consumption and manual processes.
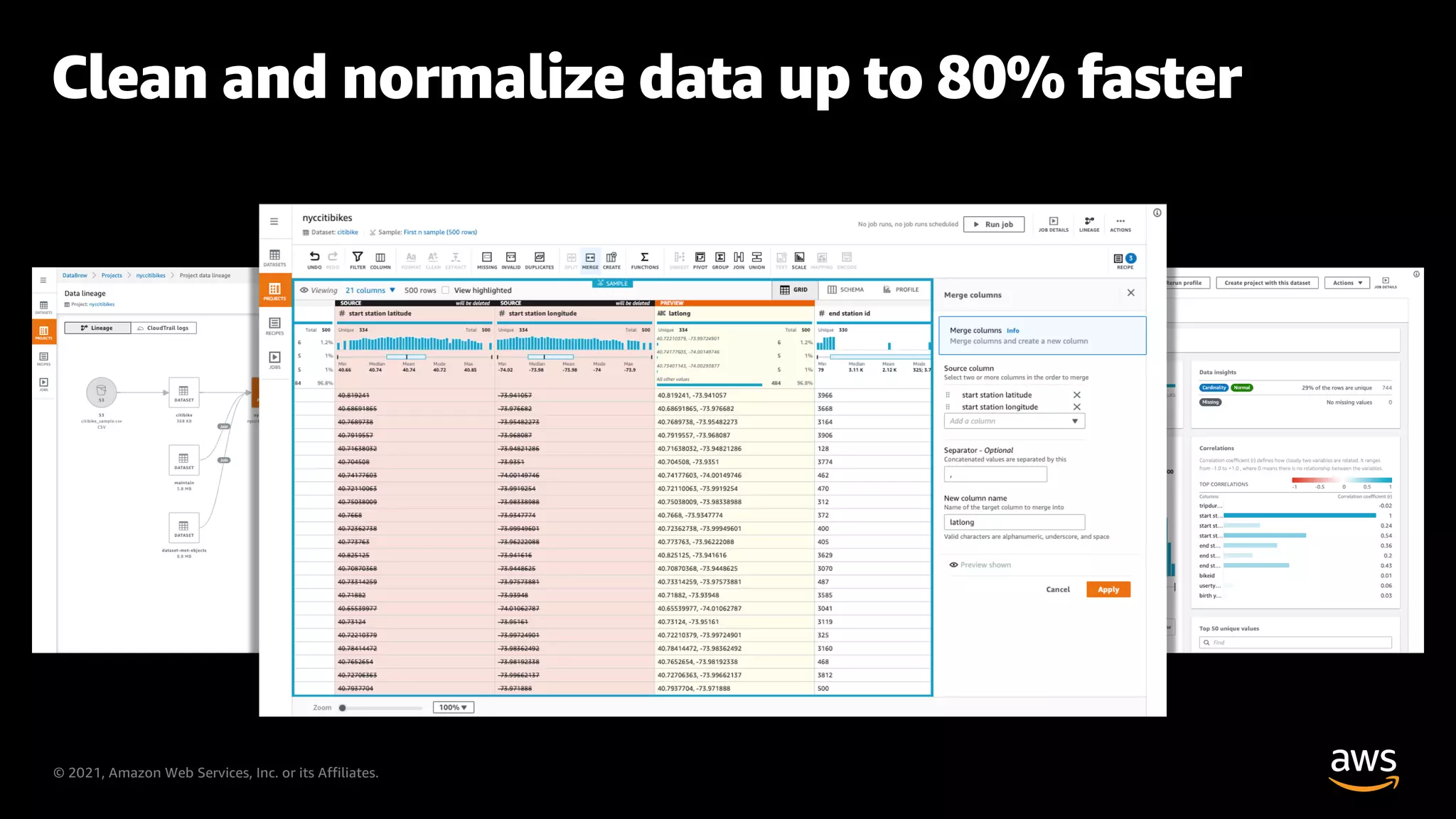
AWS Glue's capability to clean and normalize data significantly faster.
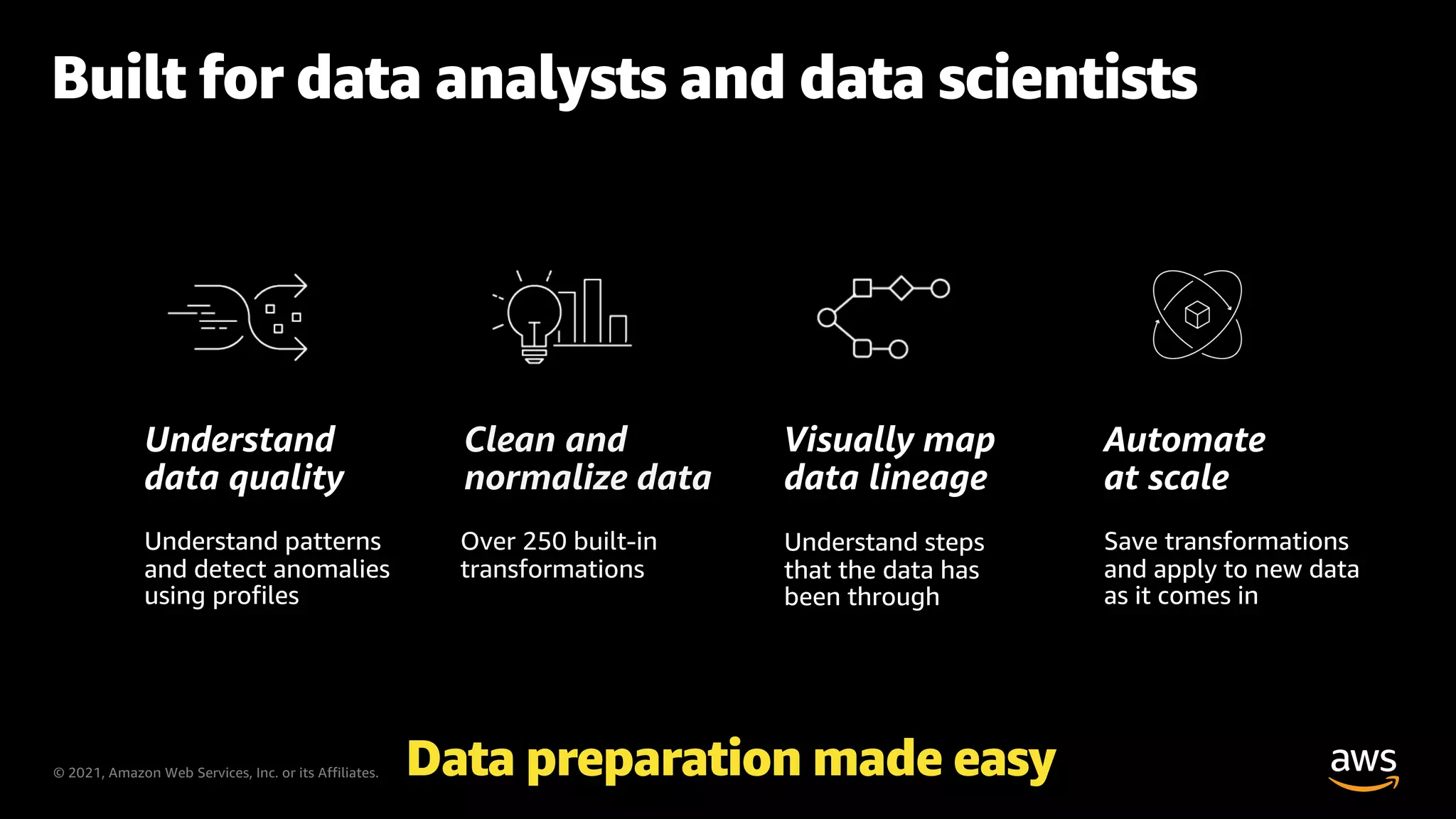
Features built for data analysts and scientists to simplify data preparation processes.
Demonstration of AWS Glue DataBrew functionalities for data preparation.
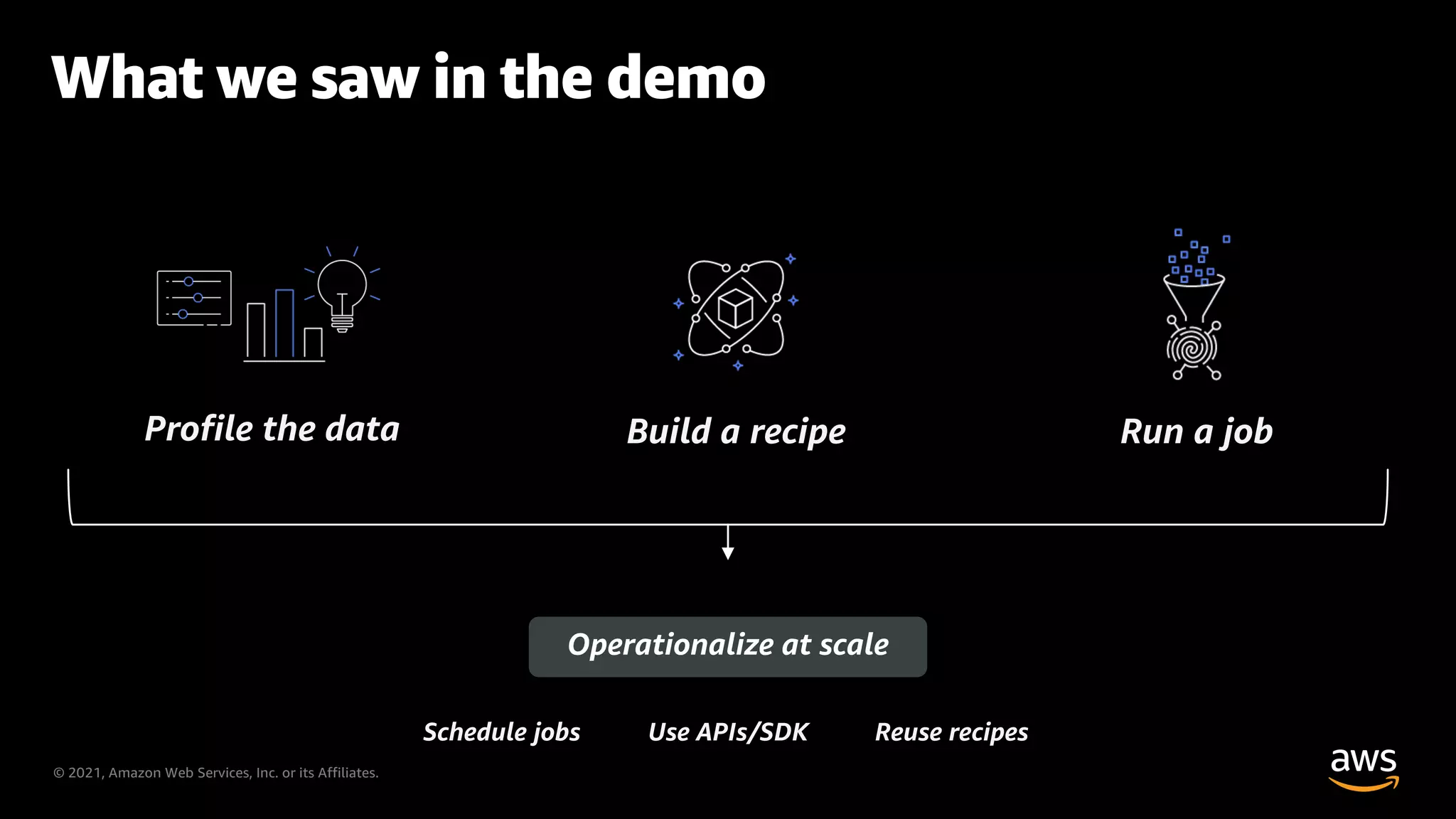
Main points discussed in the AWS Glue DataBrew demo regarding data workflows.
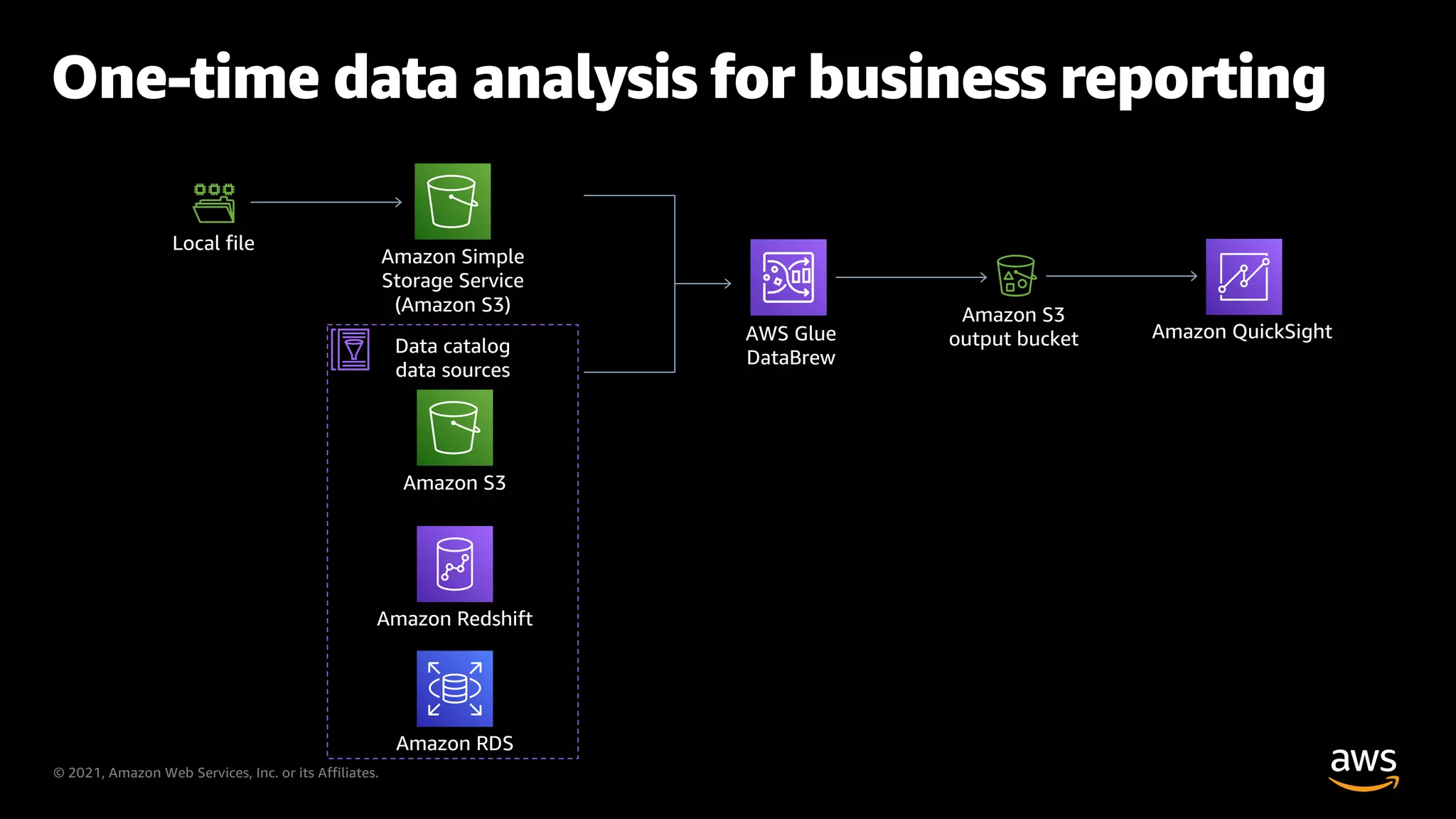
Typical applications of AWS Glue in various business scenarios.
Example of data analysis pipeline using AWS Glue and other AWS services.
Setting up alerts and data quality rules using AWS services for data feeds.
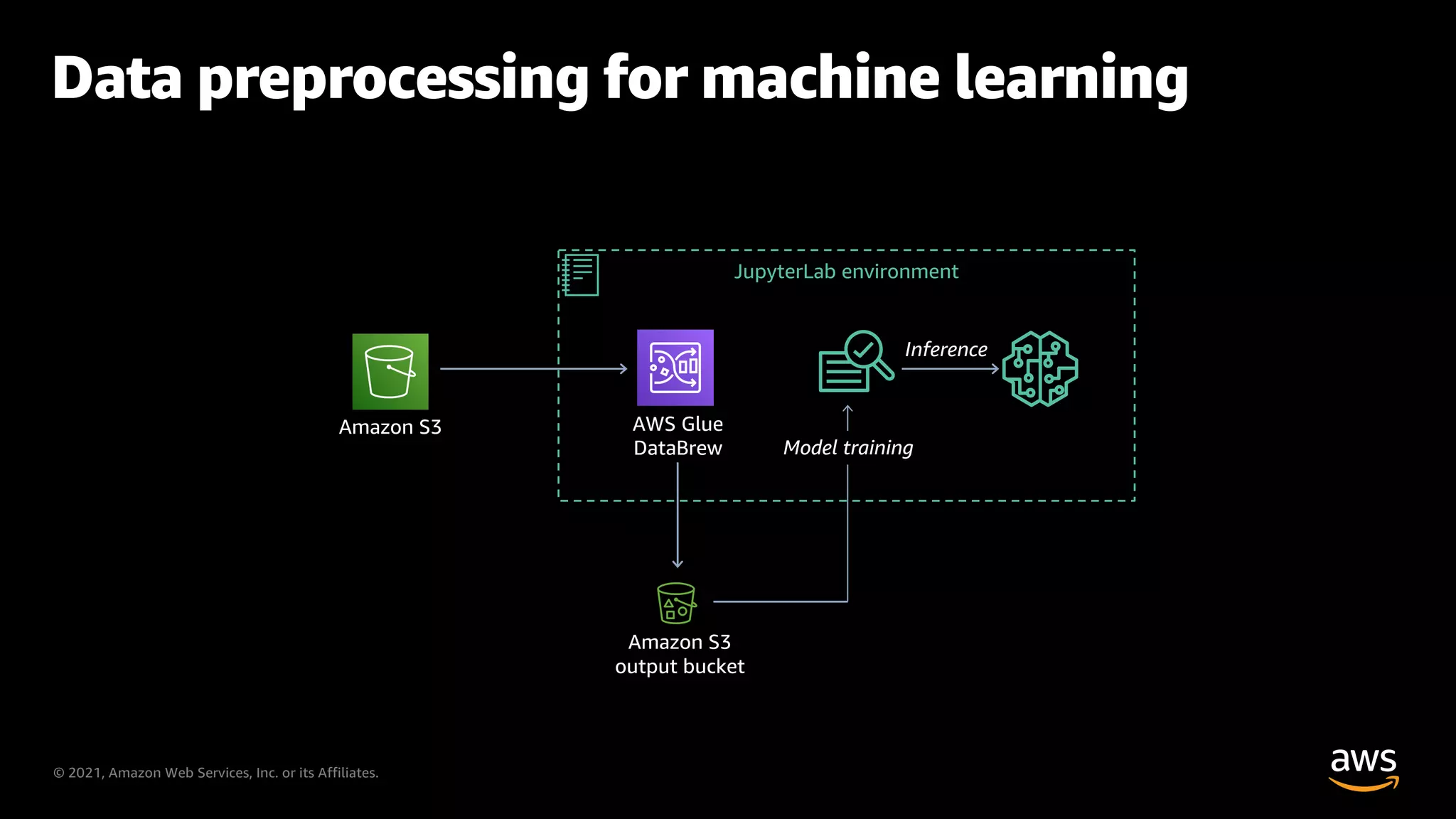
Utilizing AWS Glue for preprocessing data for machine learning models.
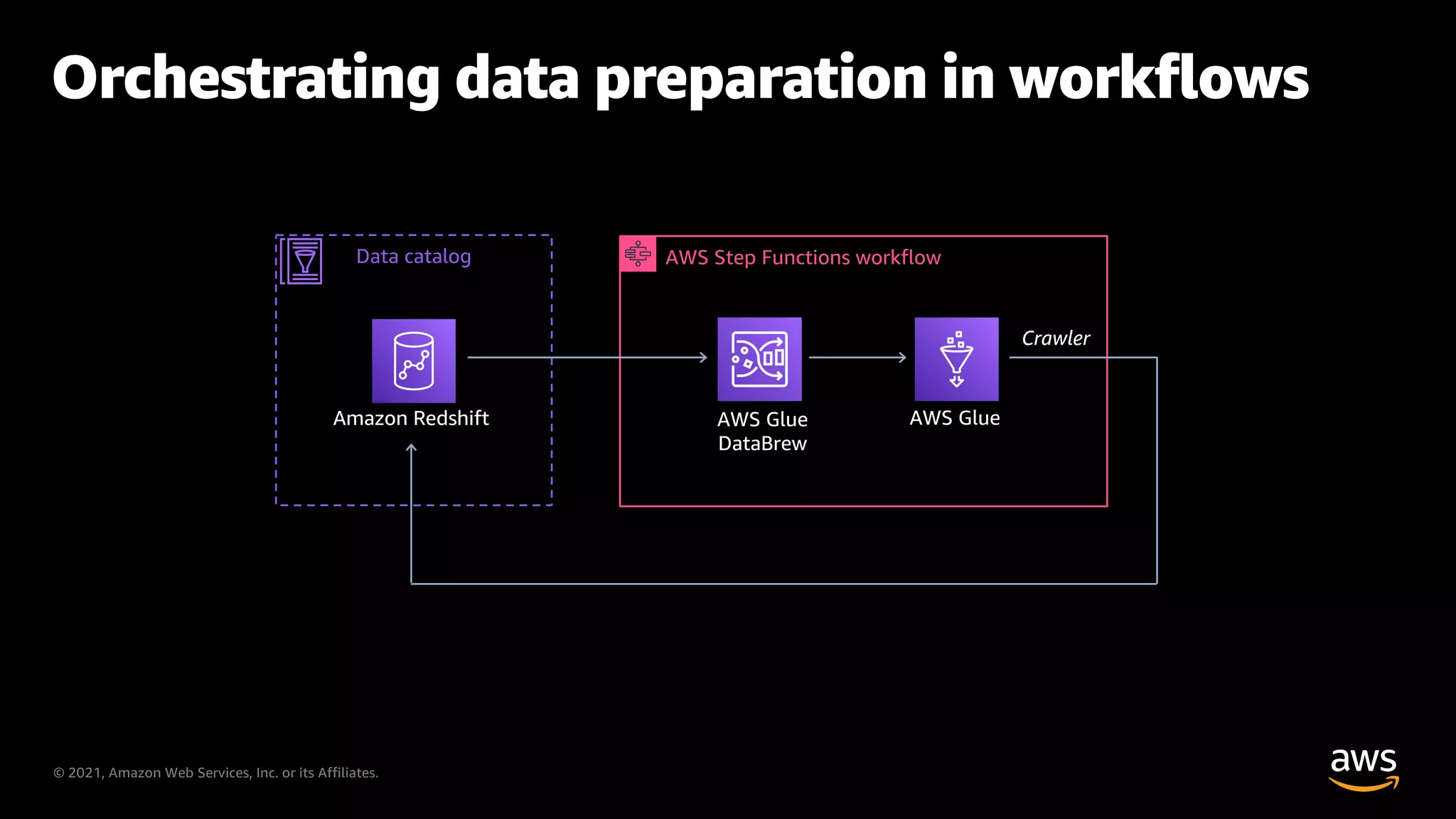
Using AWS Step Functions and Glue for orchestrating data preparation.
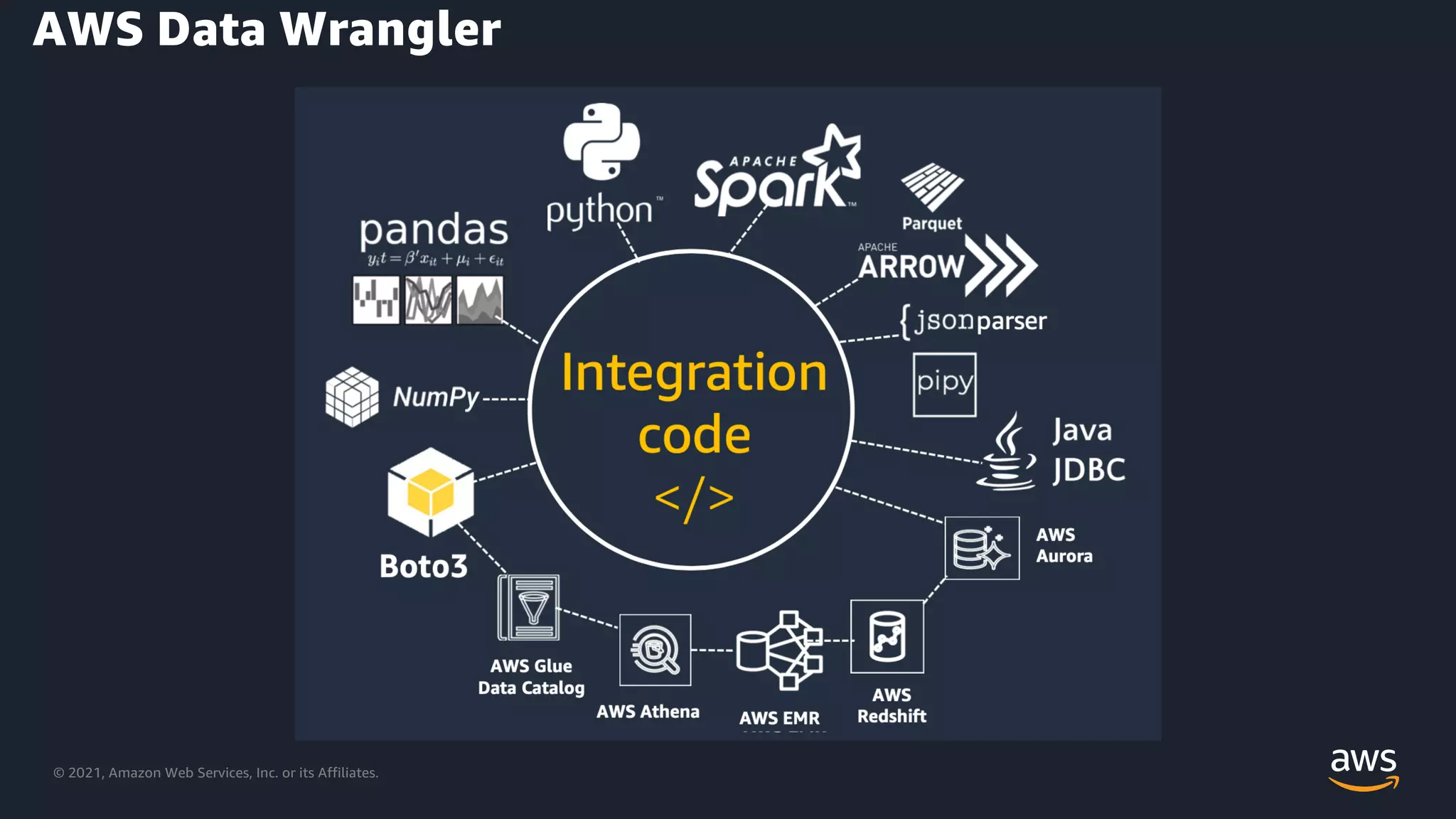
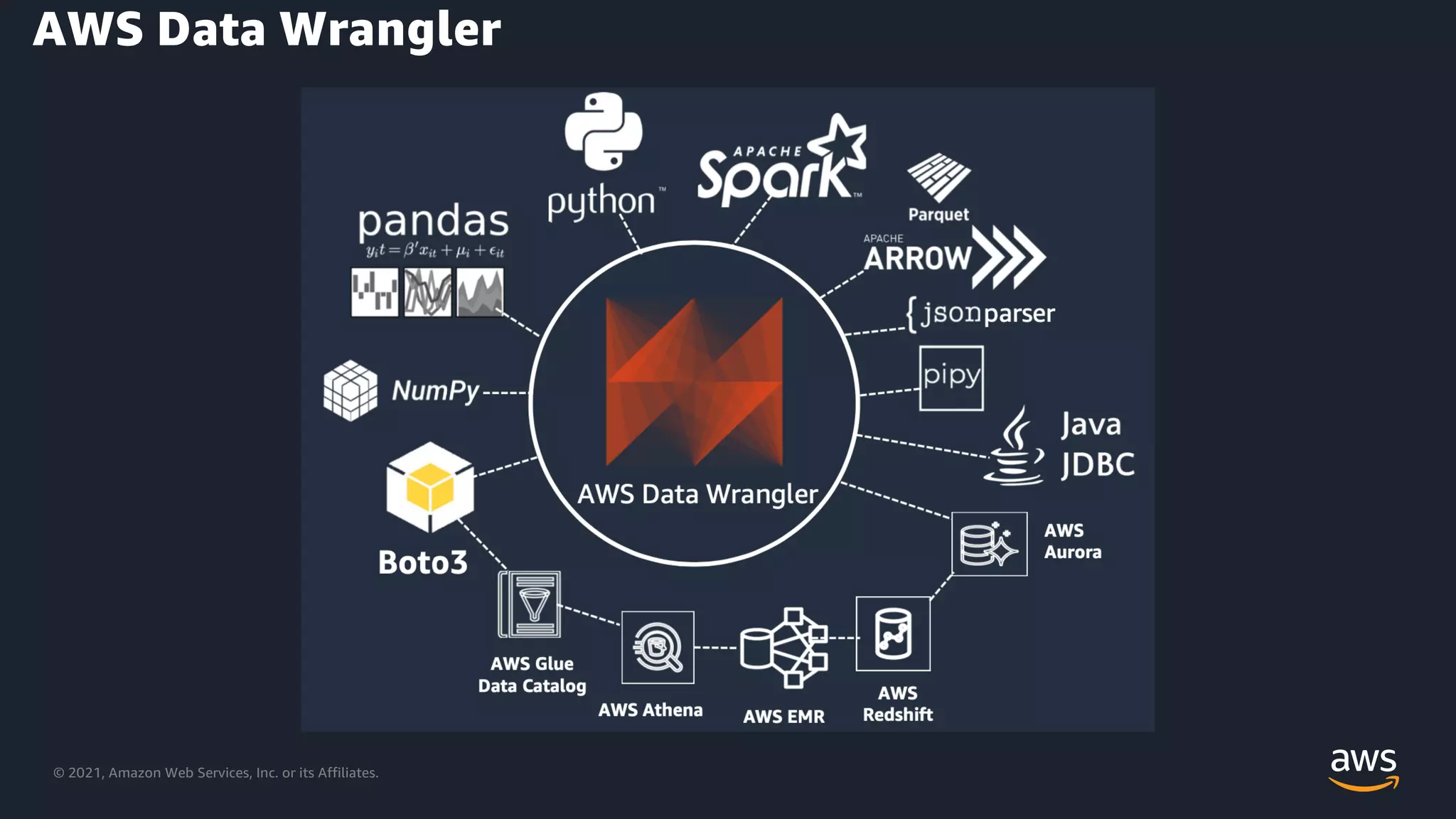
Overview of AWS Data Wrangler and its application in data preparation.
Further descriptions of functionalities within AWS Data Wrangler.
Additional insights into the capabilities of AWS Data Wrangler for data tasks.
Demonstration showcasing AWS Data Wrangler features for data preparation.
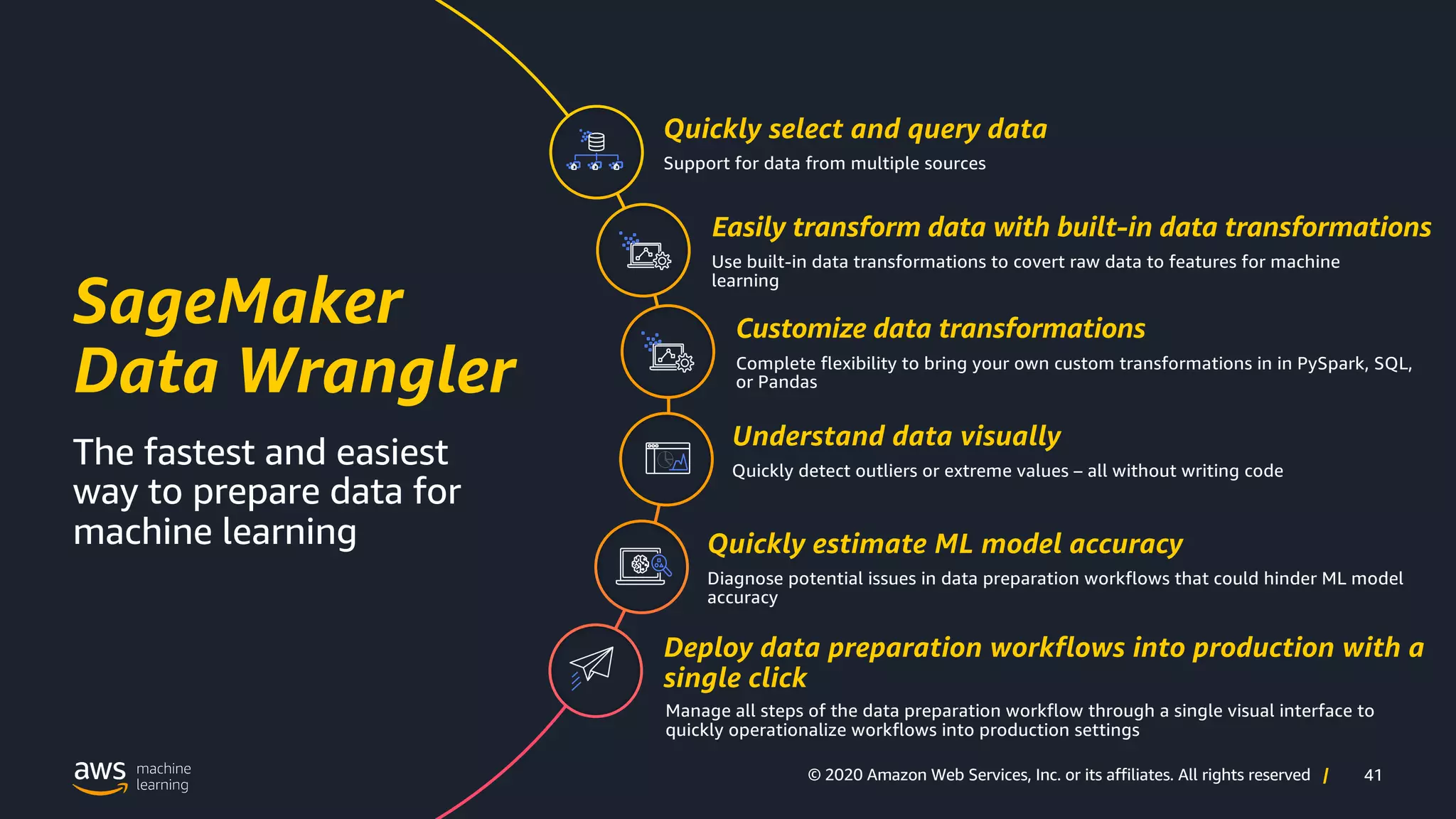
AWS Data Wrangler streamlines data preparation processes and enhances capabilities for ML.
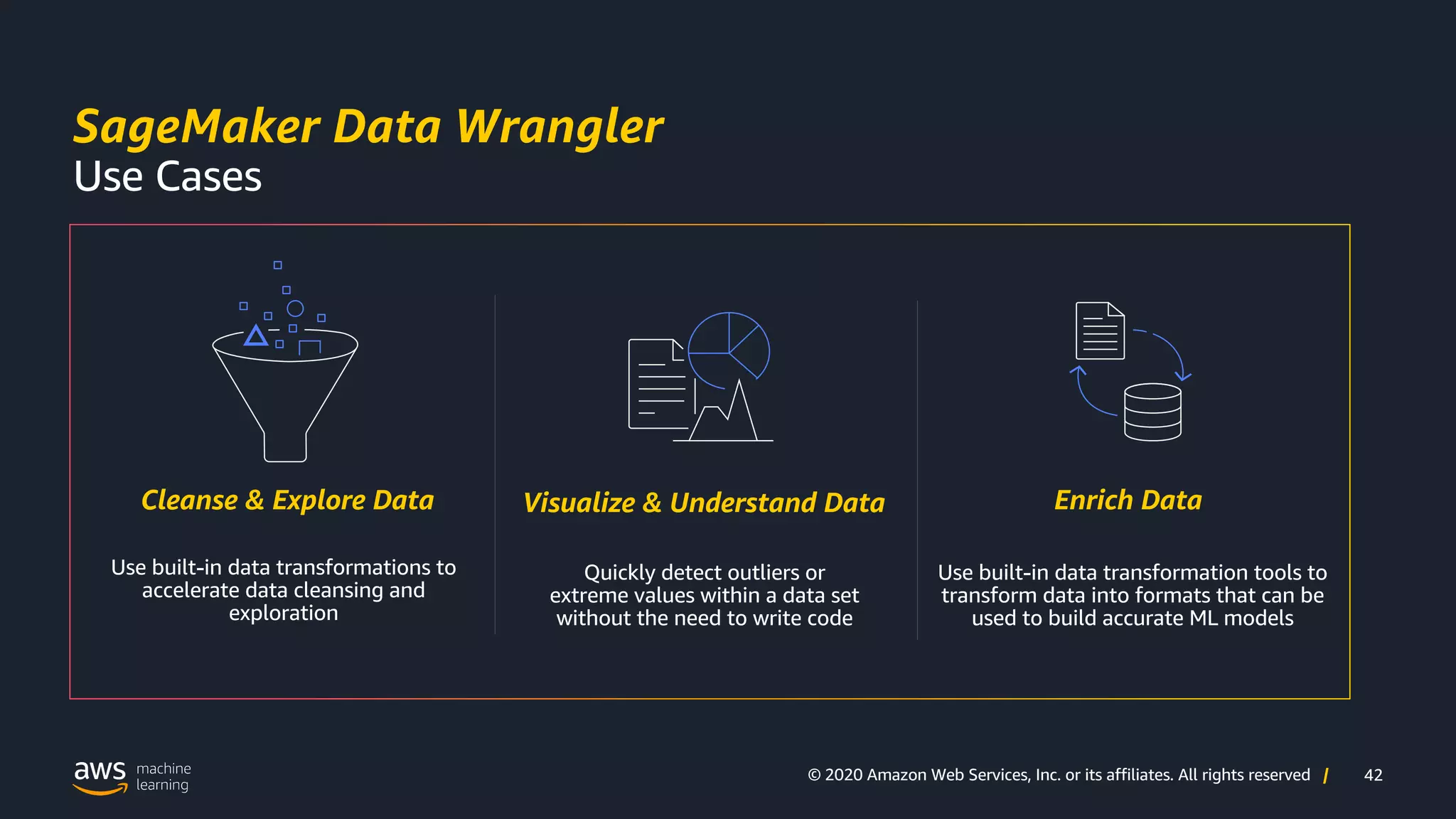
Practical scenarios where AWS Data Wrangler can be utilized effectively.
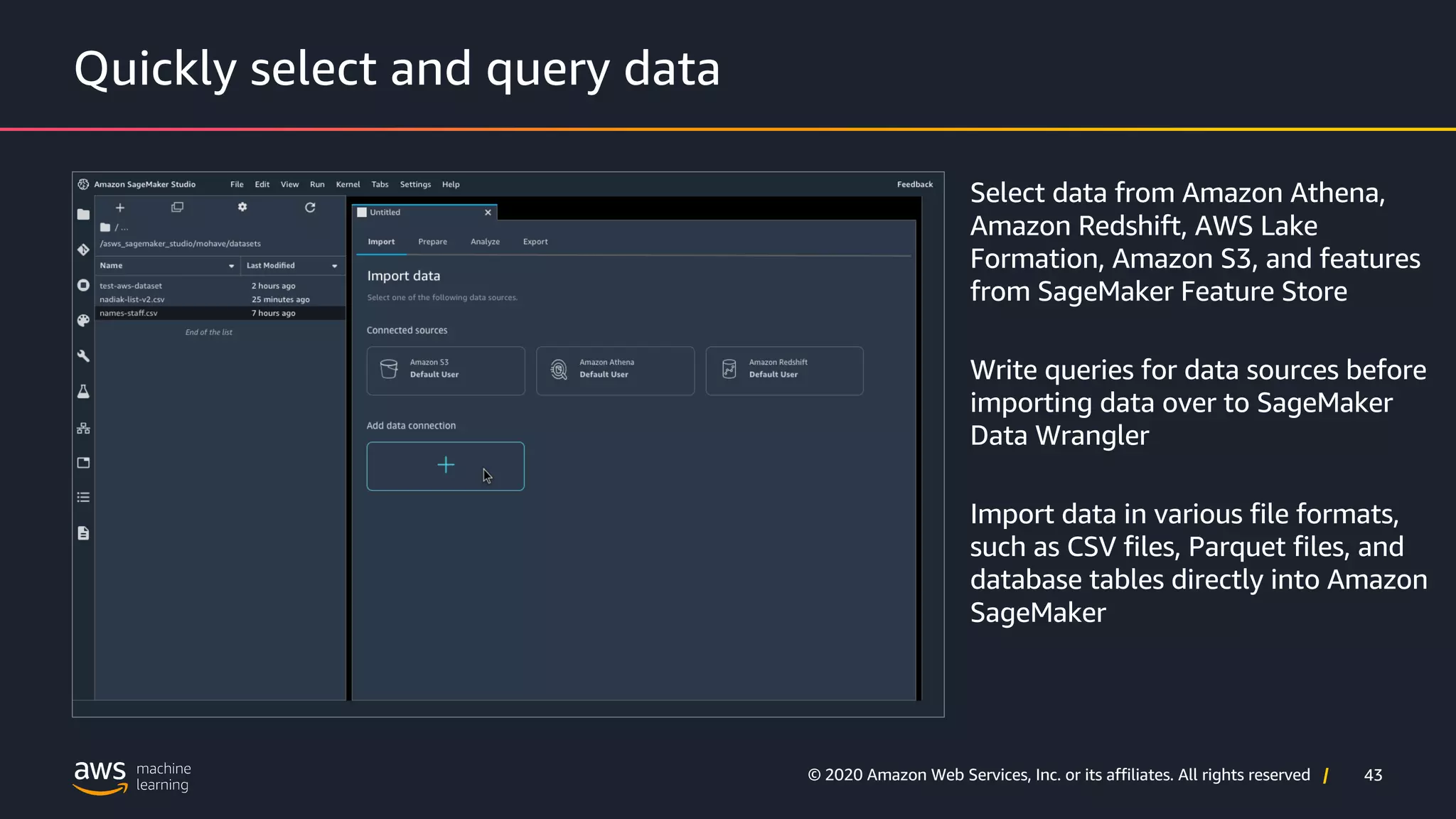
AWS Data Wrangler's ability to manage data from various sources efficiently.
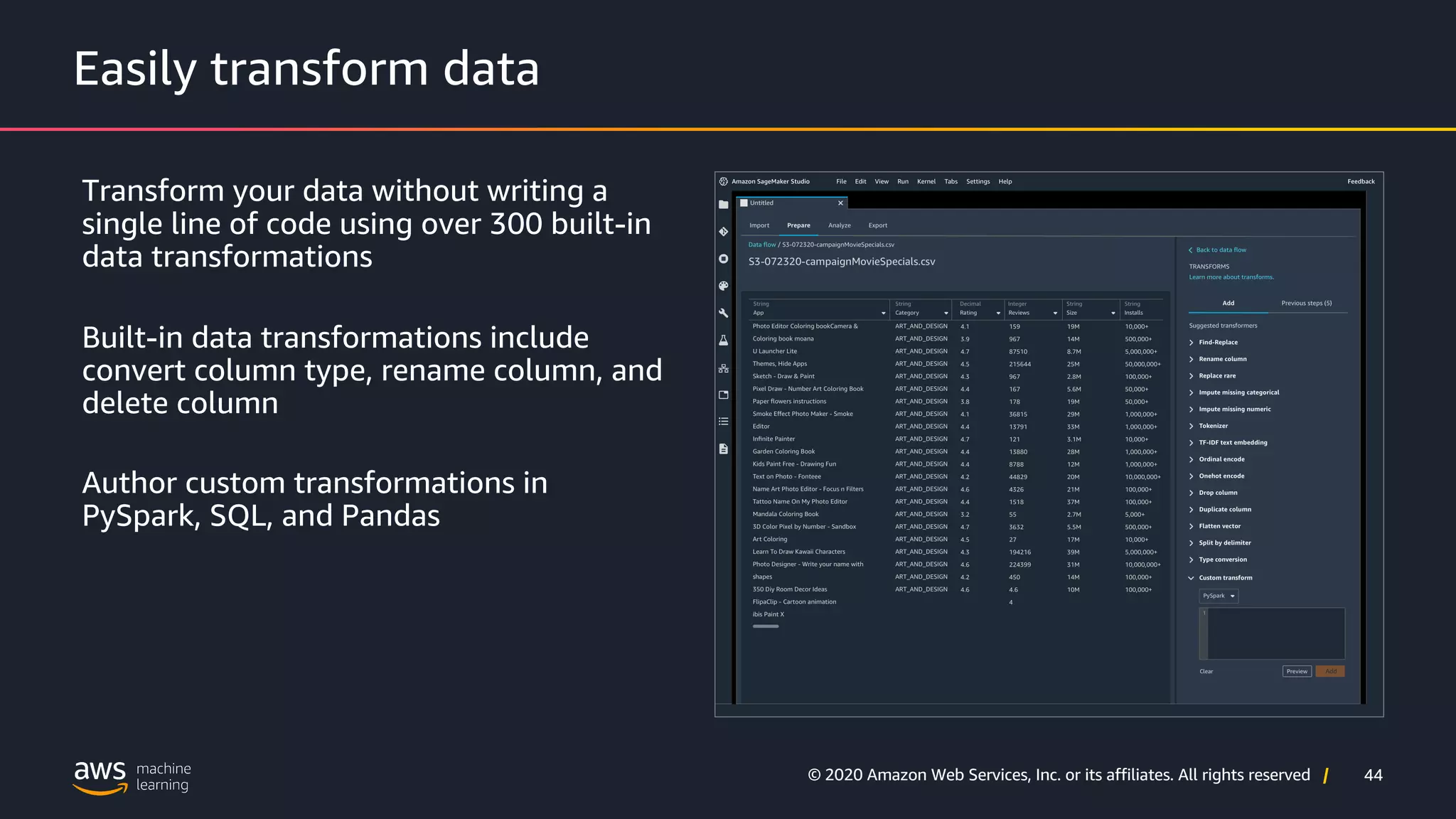
Overview of built-in transformation capabilities within AWS Data Wrangler.
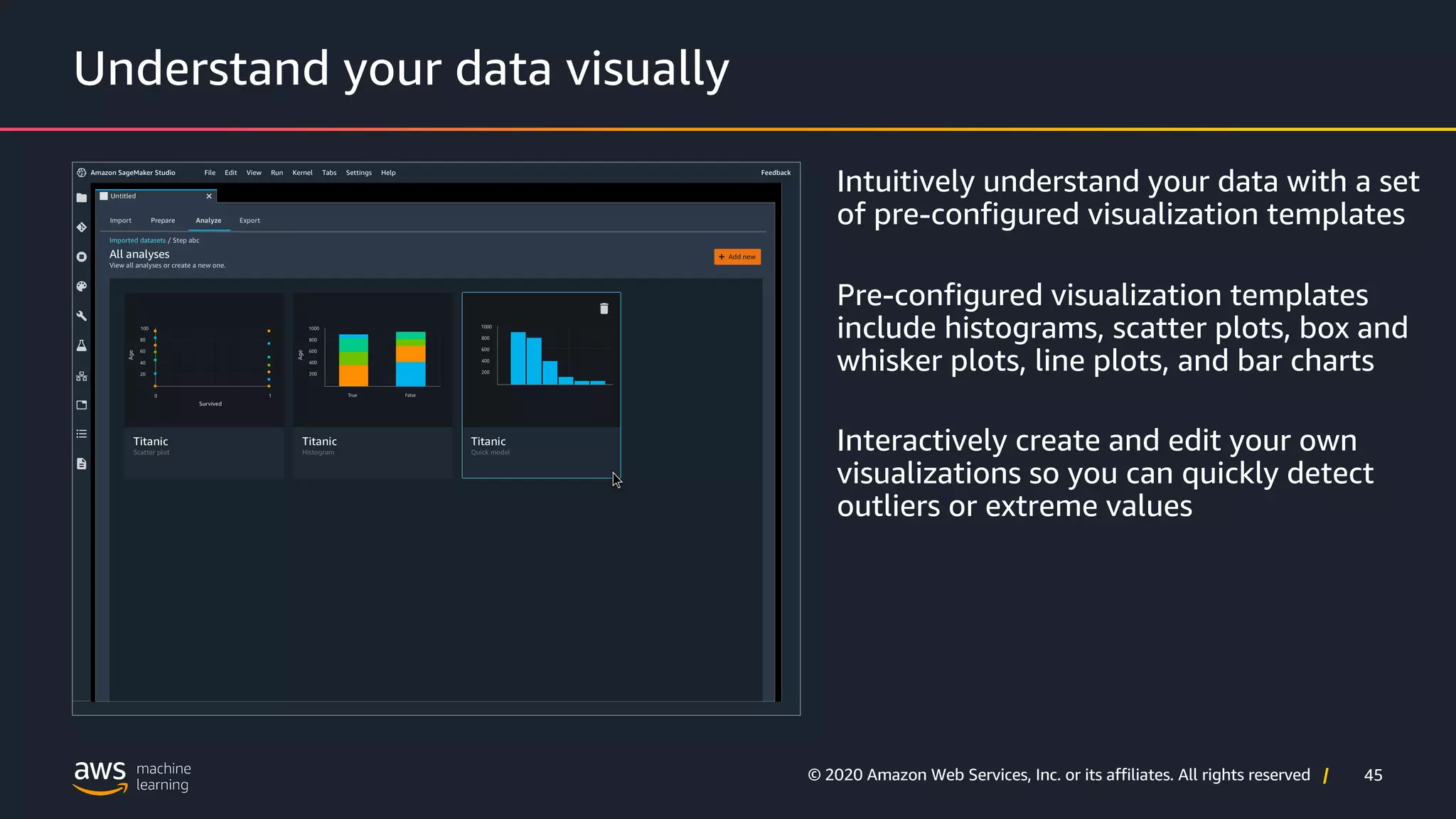
How AWS Data Wrangler helps in visualizing data for better insights.
Assessing potential data issues and estimating model accuracy with AWS Data Wrangler.
AWS Data Wrangler facilitates the deployment of data preparation workflows into production environments.
Details on the pricing structure and availability of AWS Data Wrangler.
Summary and acknowledgment of the presentation by Francesco Marelli.



















![[IBM 김상훈] 오브젝트스토리지 | 늘어만 가는 데이터 저장문제로 골 아프신가요? (자료를 다운로드하시면 고화질로 보실 수 있습니다.)](https://cdn.slidesharecdn.com/ss_thumbnails/2-181031090033-thumbnail.jpg?width=640&height=640&fit=bounds)











![Data & Analytics ReInvent Recap [AWS Basel Meetup - Jan 2023]](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalyticsreinventrecapawsbaselmeetup-jan2023-230117084518-26107394-thumbnail.jpg?width=640&height=640&fit=bounds)























































