


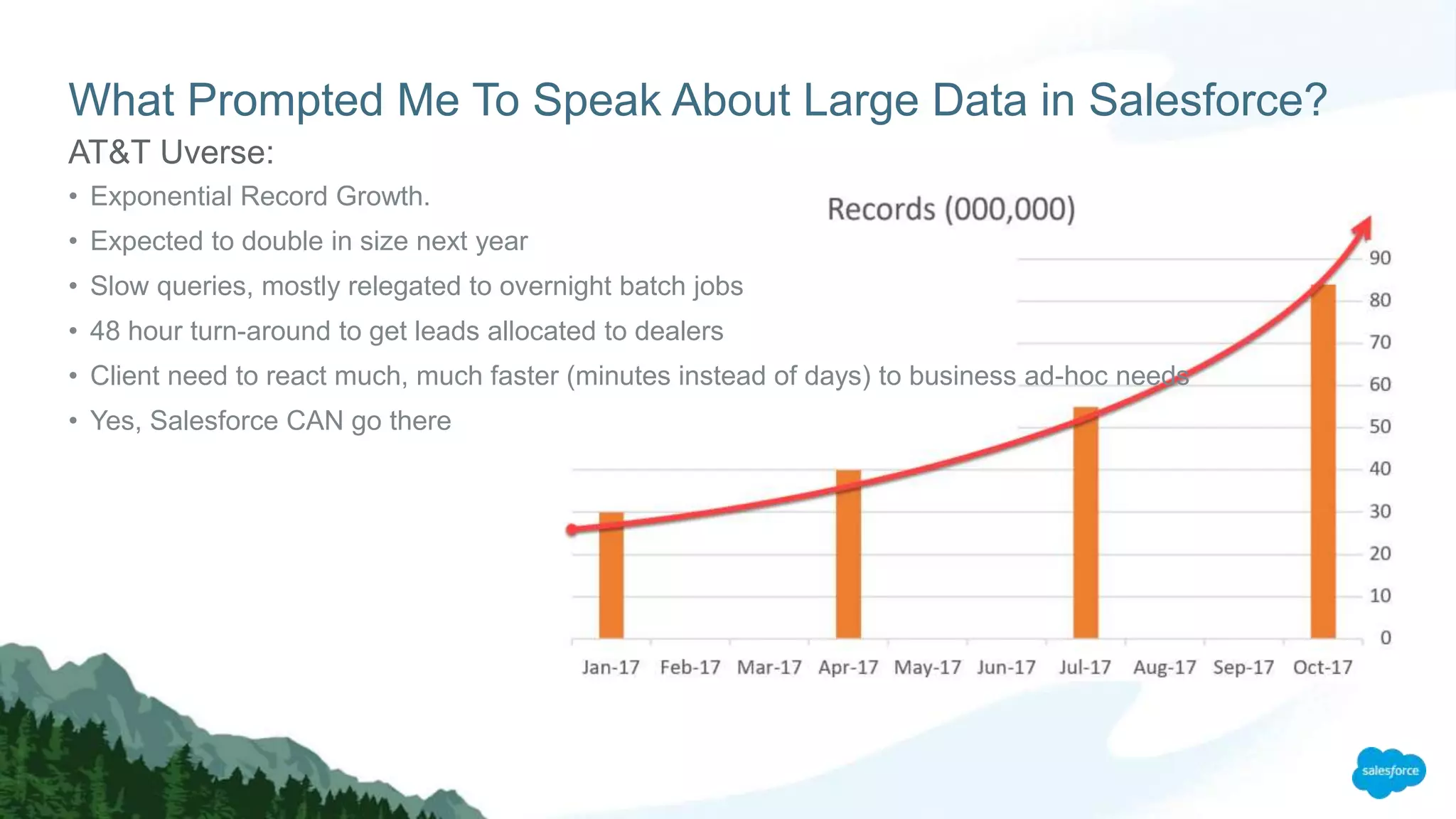
![By [2020], our accumulated digital universe of data will grow from
4.4 zettabyets today to around 44 zettabytes, or
44 trillion gigabytes.
Even on a logarithmic scale, data is growing at an exponential rate…](https://image.slidesharecdn.com/moyezdreamforcepresentationldv-171113212109/75/Moyez-Dreamforce-2017-presentation-on-Large-Data-Volumes-in-Salesforce-5-2048.jpg)
![By [2020], our accumulated digital universe of data will grow from
4.4 zettabyets today to around 44 zettabytes, or
44 trillion gigabytes.
Even on a logarithmic scale, data is growing at an exponential rate…](https://image.slidesharecdn.com/moyezdreamforcepresentationldv-171113212109/75/Moyez-Dreamforce-2017-presentation-on-Large-Data-Volumes-in-Salesforce-6-2048.jpg)



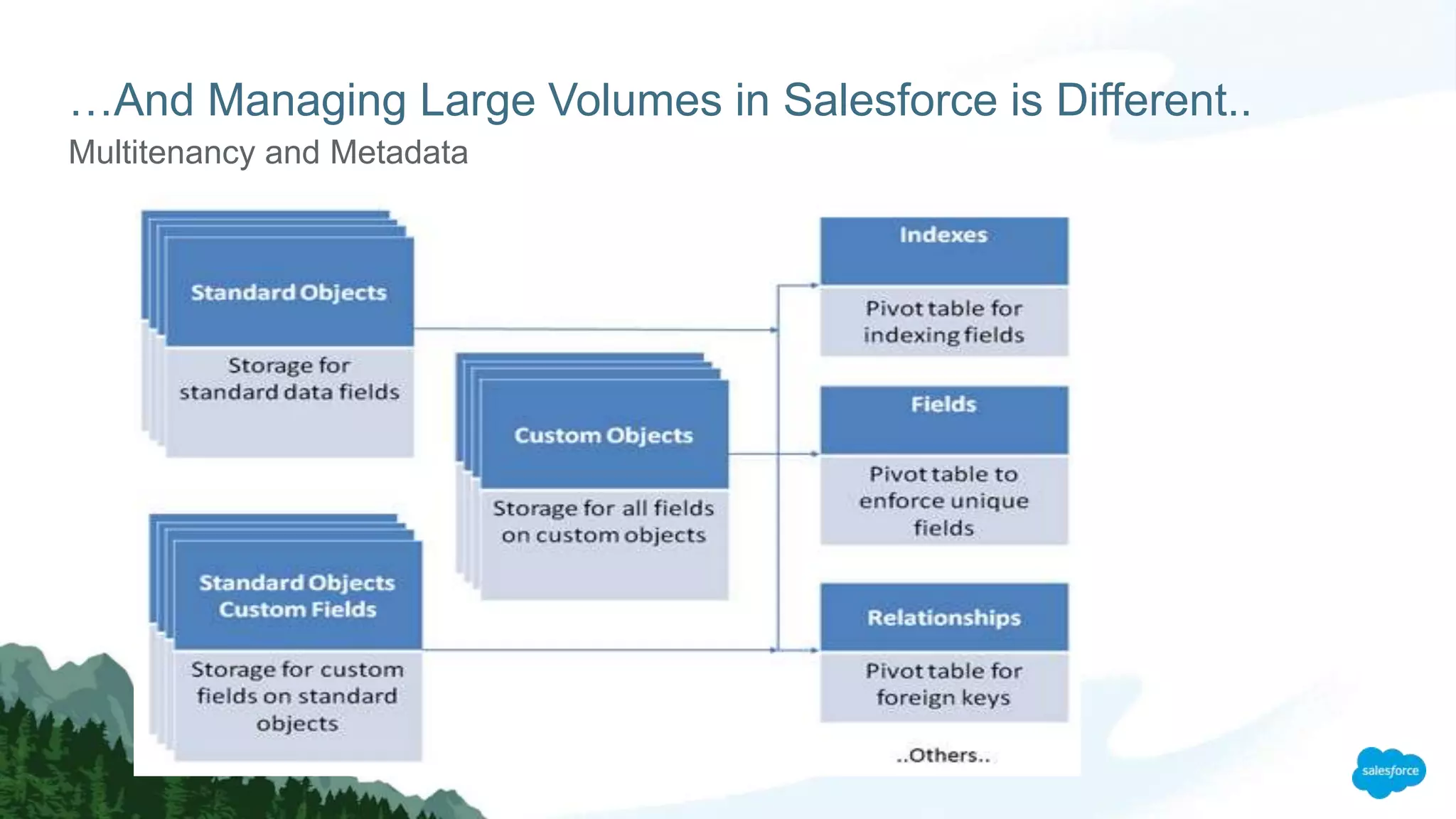

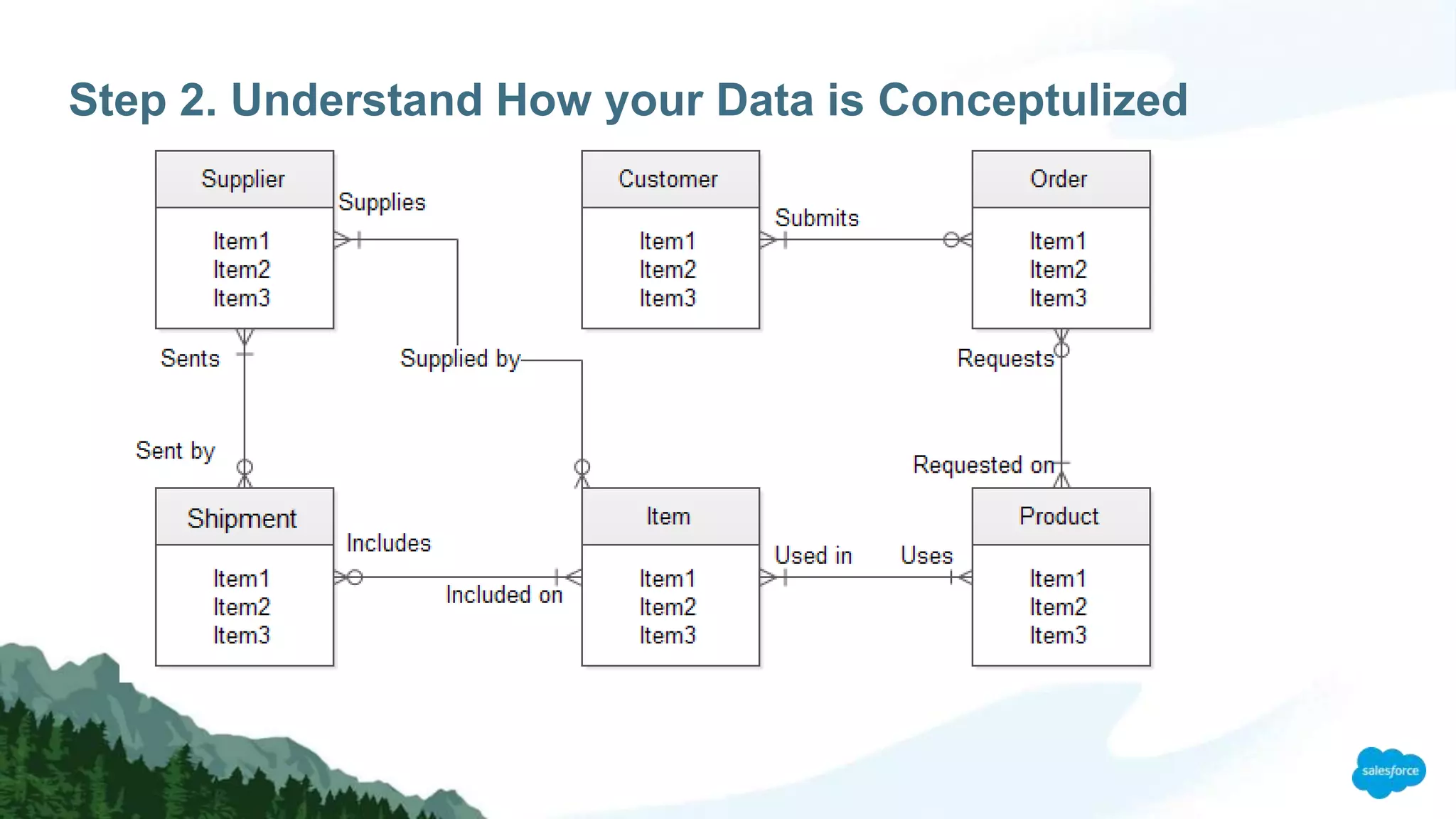




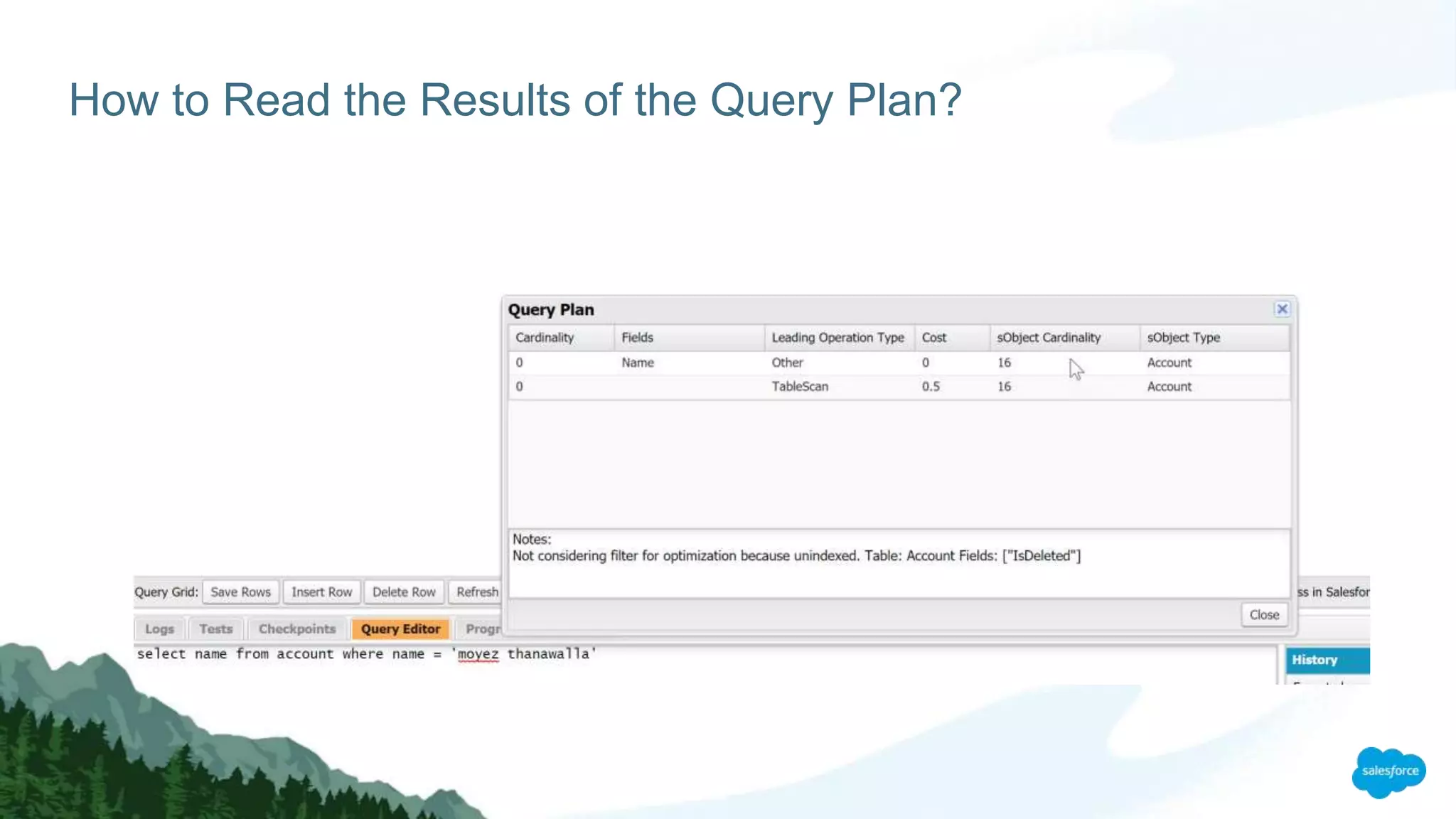
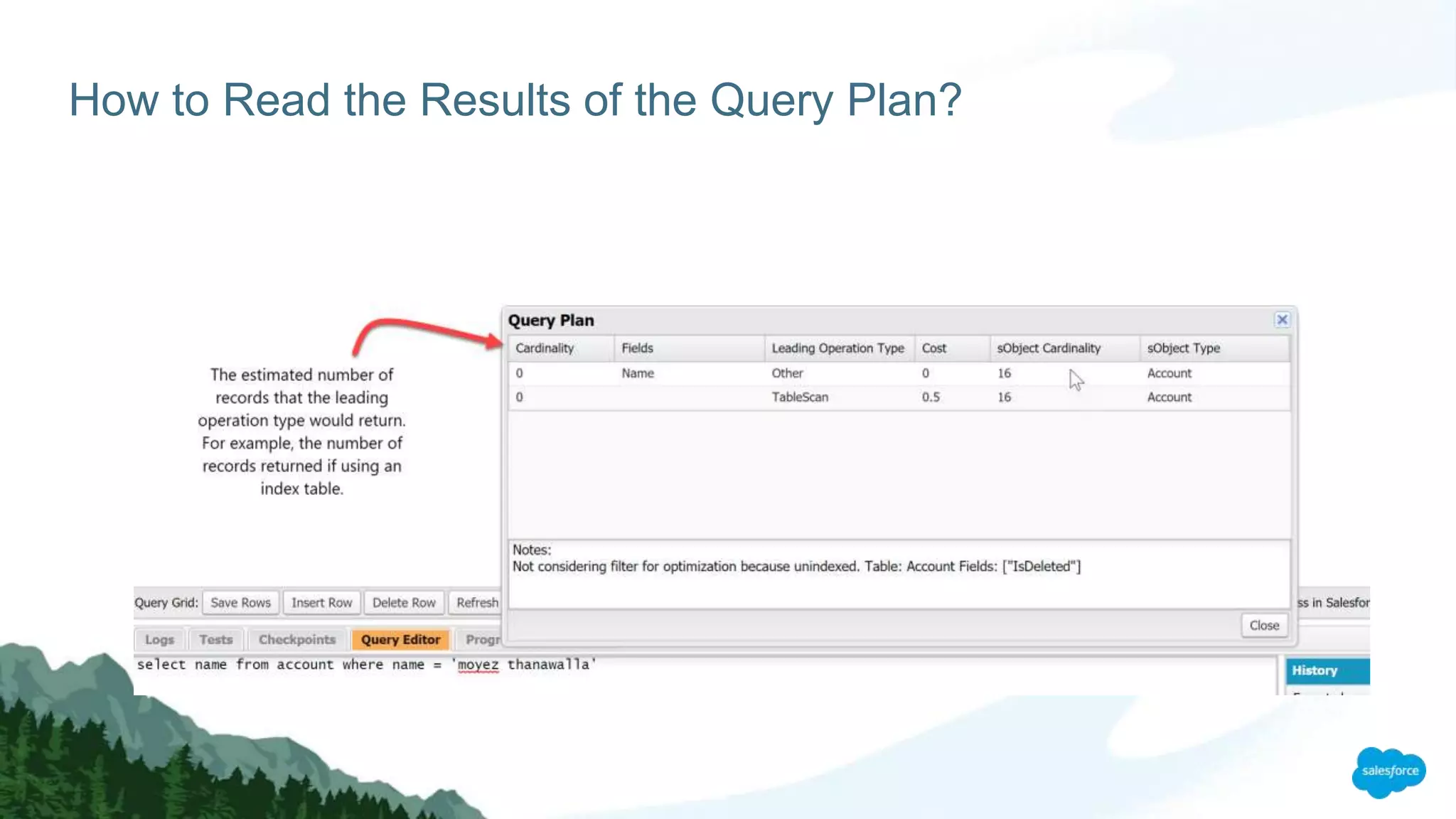






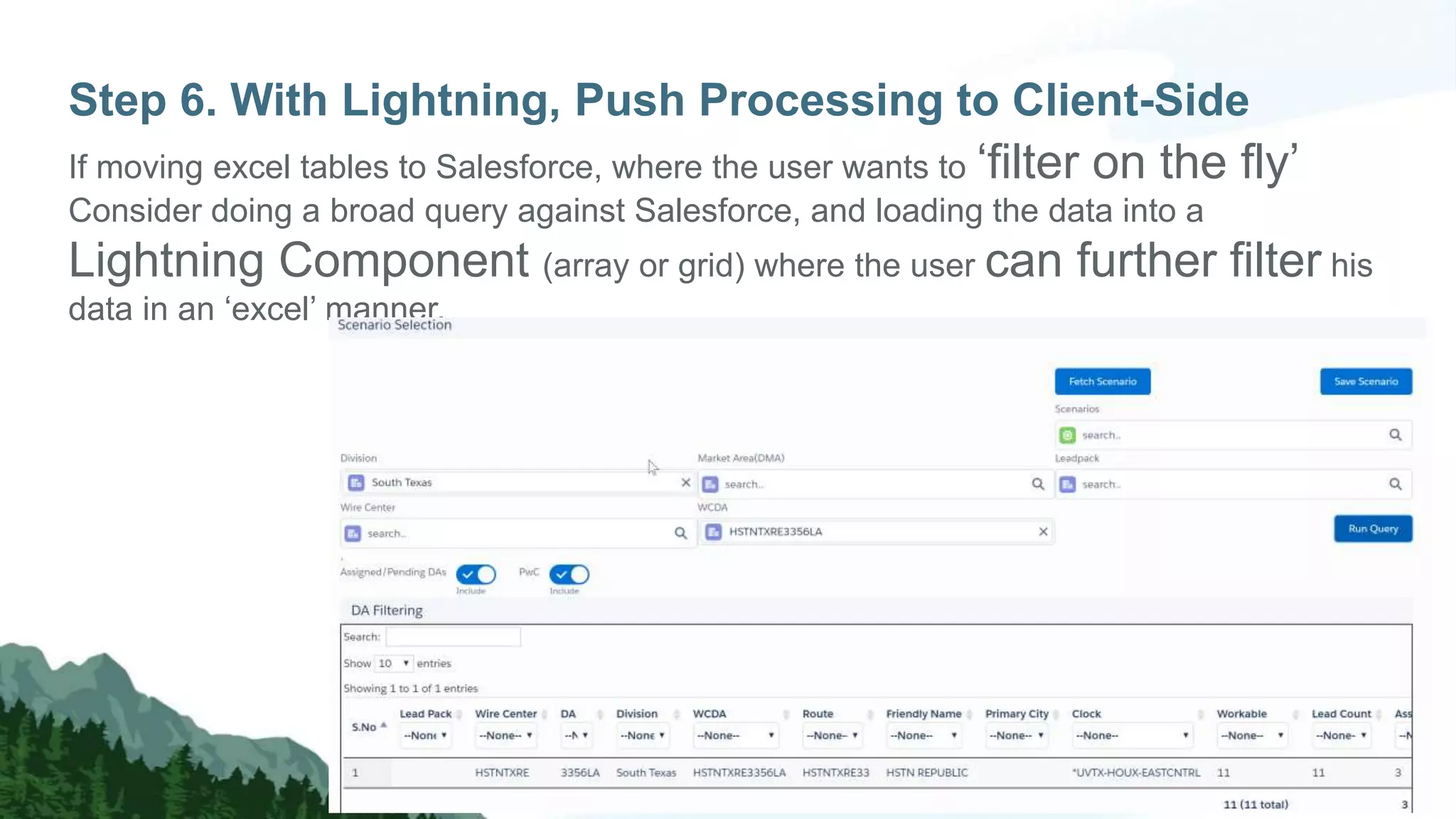




The document discusses strategies for managing large data volumes in Salesforce, highlighting the importance of efficient data processing and database optimization. Key steps include understanding data control, leveraging indexes, using skinny tables, and employing client-side processing with Lightning. It emphasizes the exponential growth of data and the need for organizations to adapt their data handling techniques accordingly.












































































