Kafka Lambda architecture with mirroring
•Download as PPTX, PDF•
1 like•1,075 views

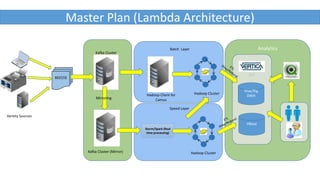
This document outlines a master plan for a lambda architecture that involves mirroring data from multiple Kafka clusters into a Hadoop cluster for batch processing and analytics, as well as real-time processing using Storm/Spark on the mirrored data in the Kafka clusters, with data from various sources integrated into the Kafka clusters with the topic name "Data".

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Kafka Lambda architecture with mirroring
- 1. Hadoop Cluster Hadoop Cluster Speed Layer Storm/Spark (Real time processing) Batch Layer Analytics ELT Kafka Cluster (Mirror) Mirroring Kafka Cluster Hadoop Client for Camus Hive/Pig DWH HBase Master Plan (Lambda Architecture) Variety Sources REST/IS
- 2. Kafka Cluster A REST/IS REST/IS Kafka Cluster B Mirroring Kafka Cluster C Kafka Cluster D Topic : “Data” Topic : “Data” Kafka (Mirroring) Configuration Integration of all the sources coming to cluster A and B with topic Name “Data” Integration of all the sources coming to cluster A and B with topic Name “Data” Host Configuration -Quad-Core AMD Opteron(TM) Processor -8GB RAM -320Gb Batch Layer (Writing the data into hadoop cluster) Speed Layer (Feeding data from Kafka to Storm )