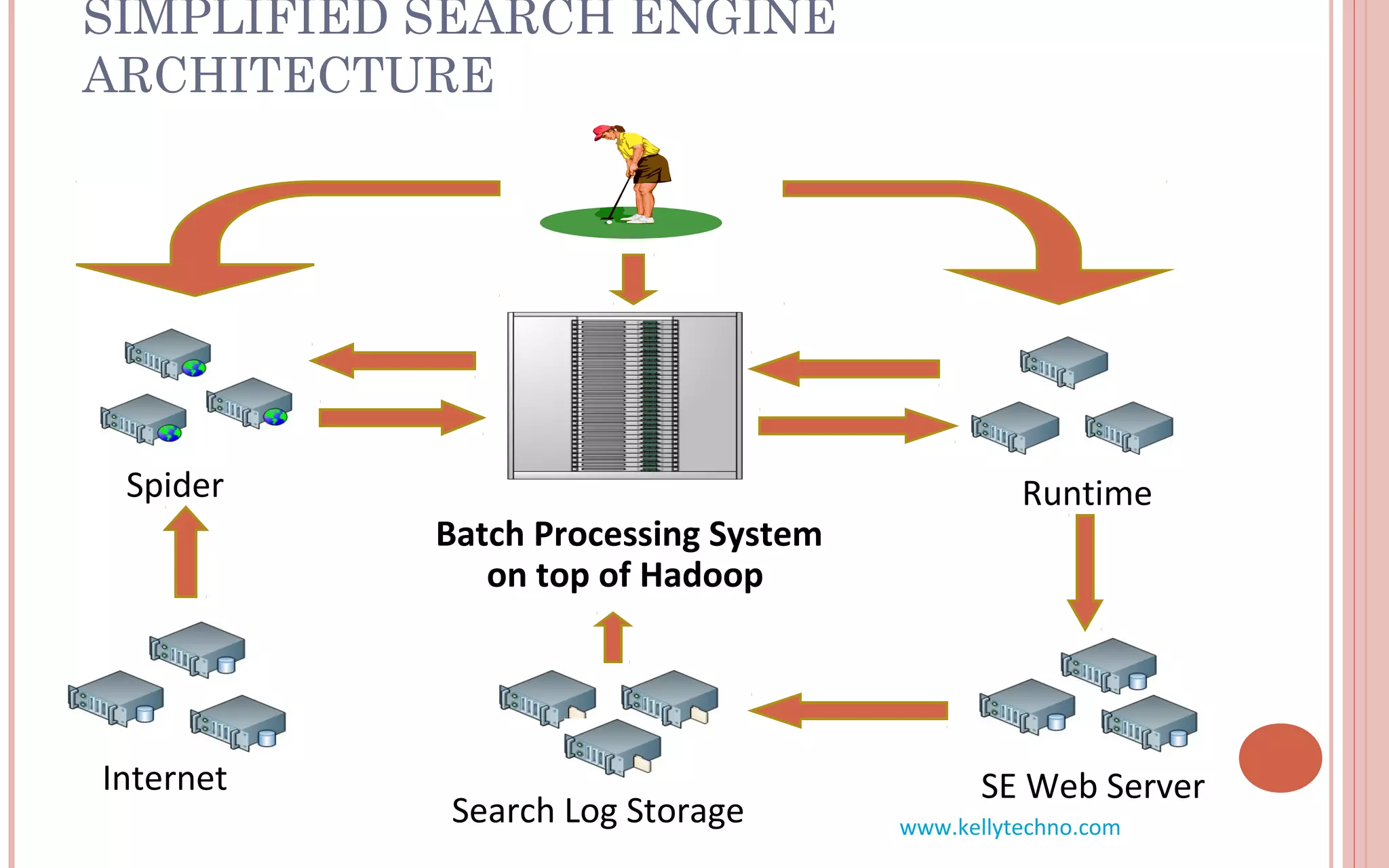
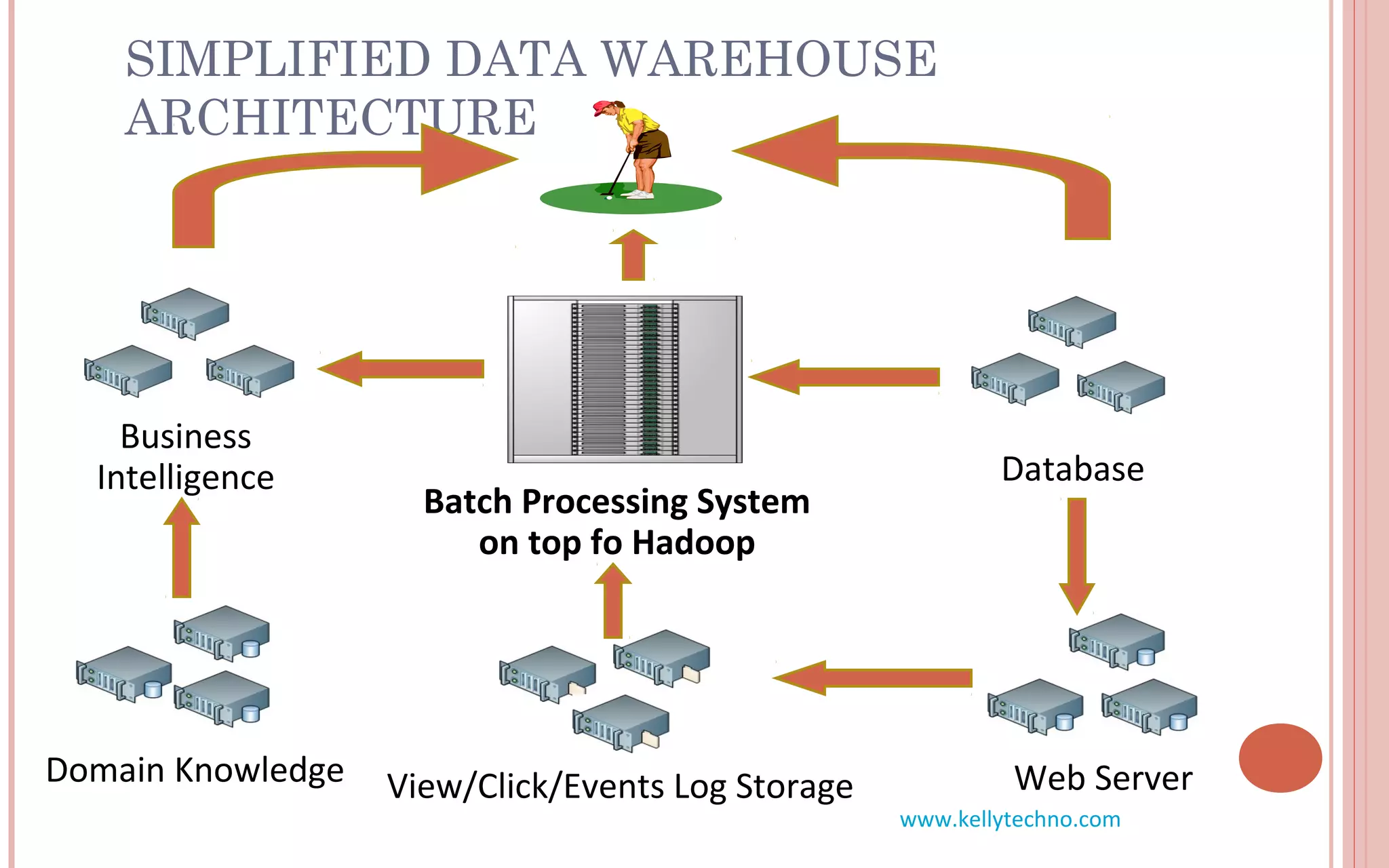
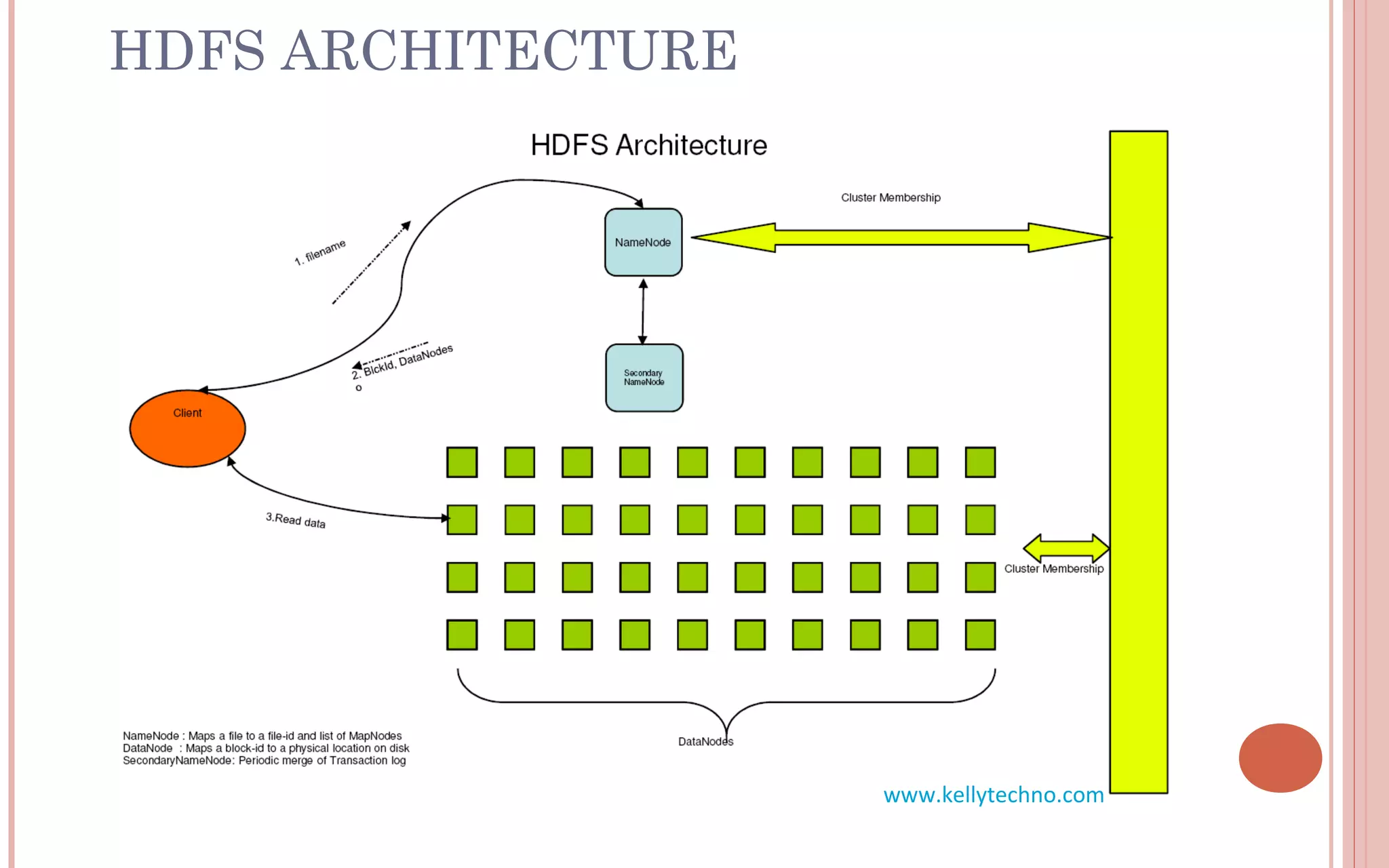
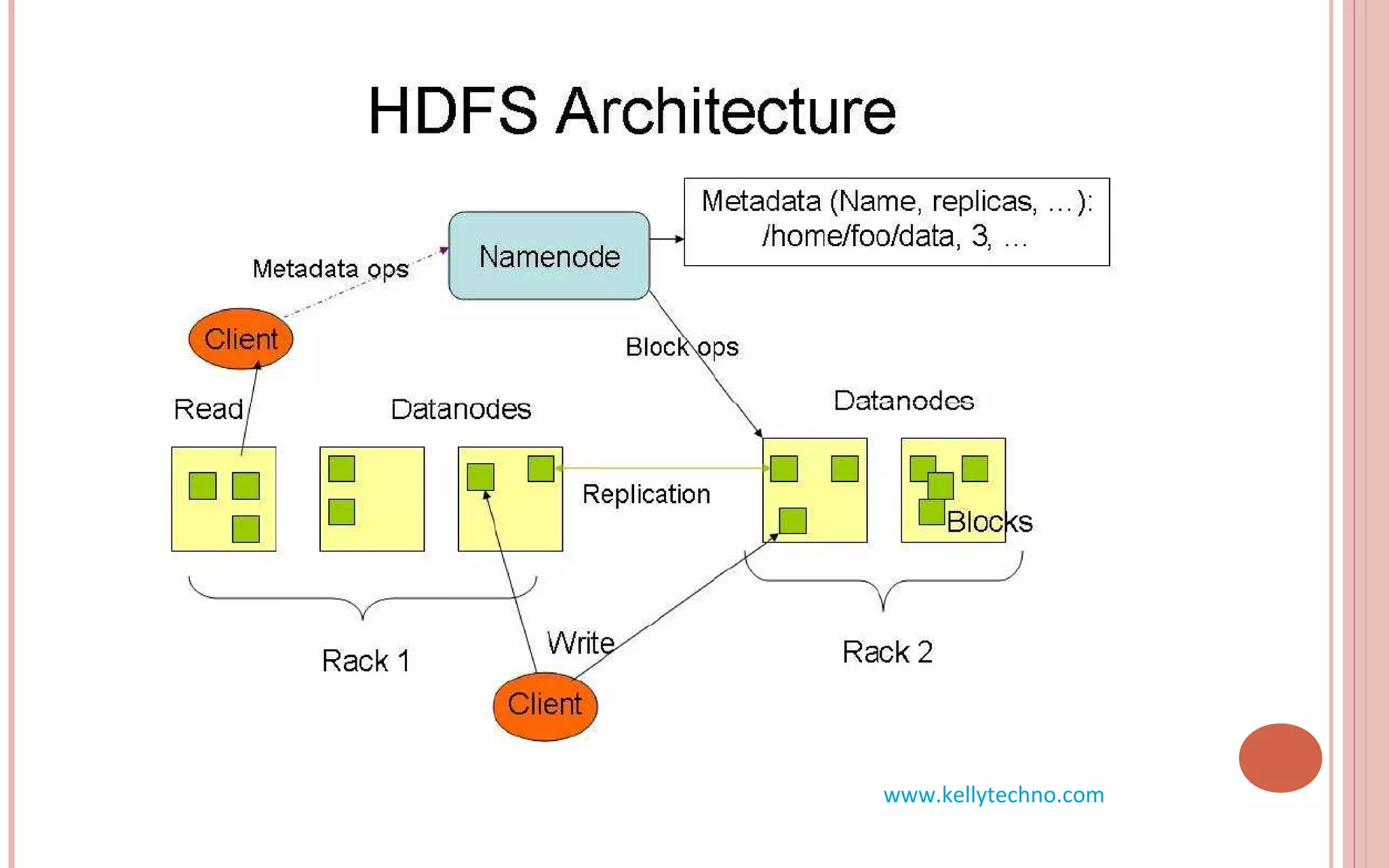
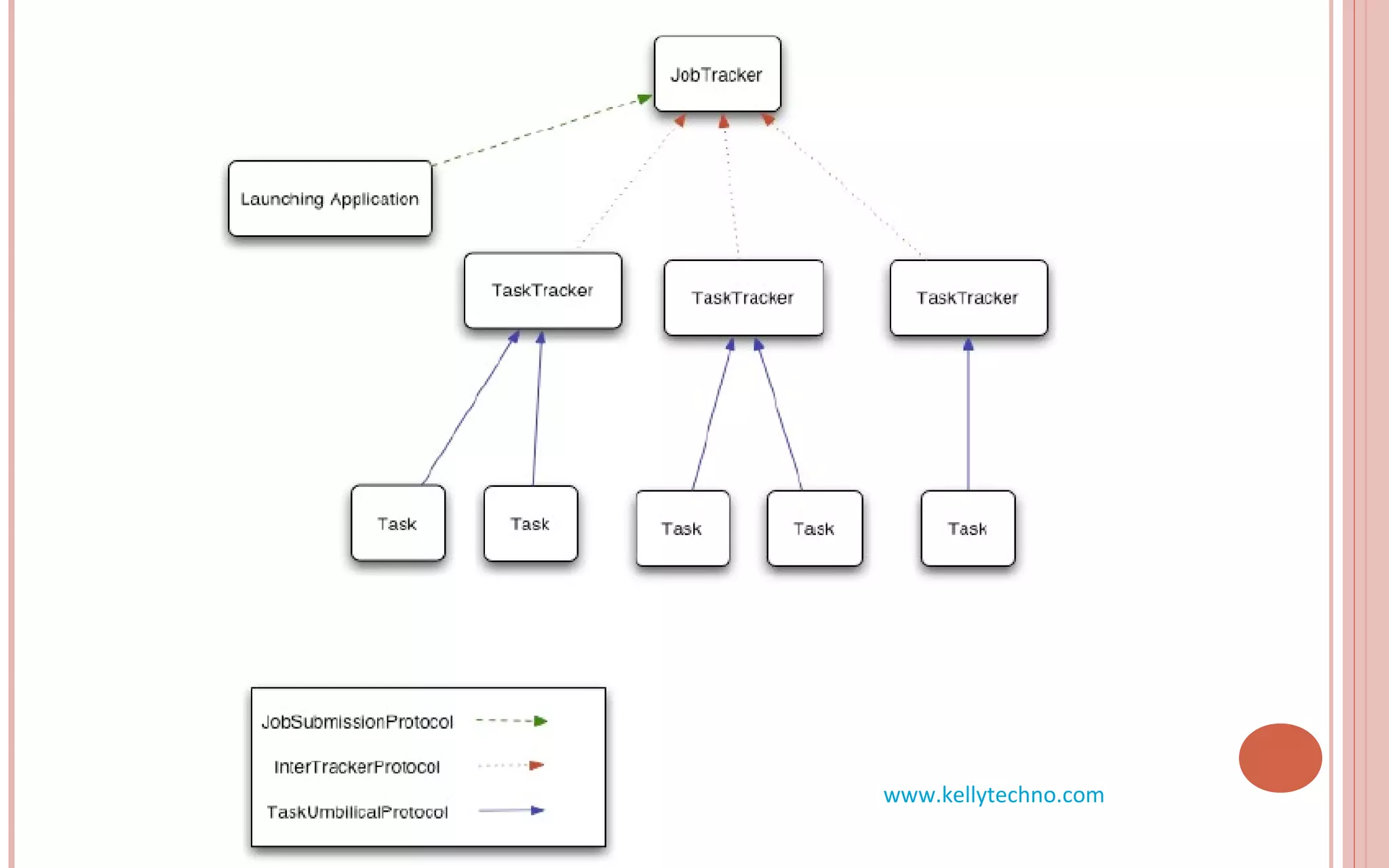
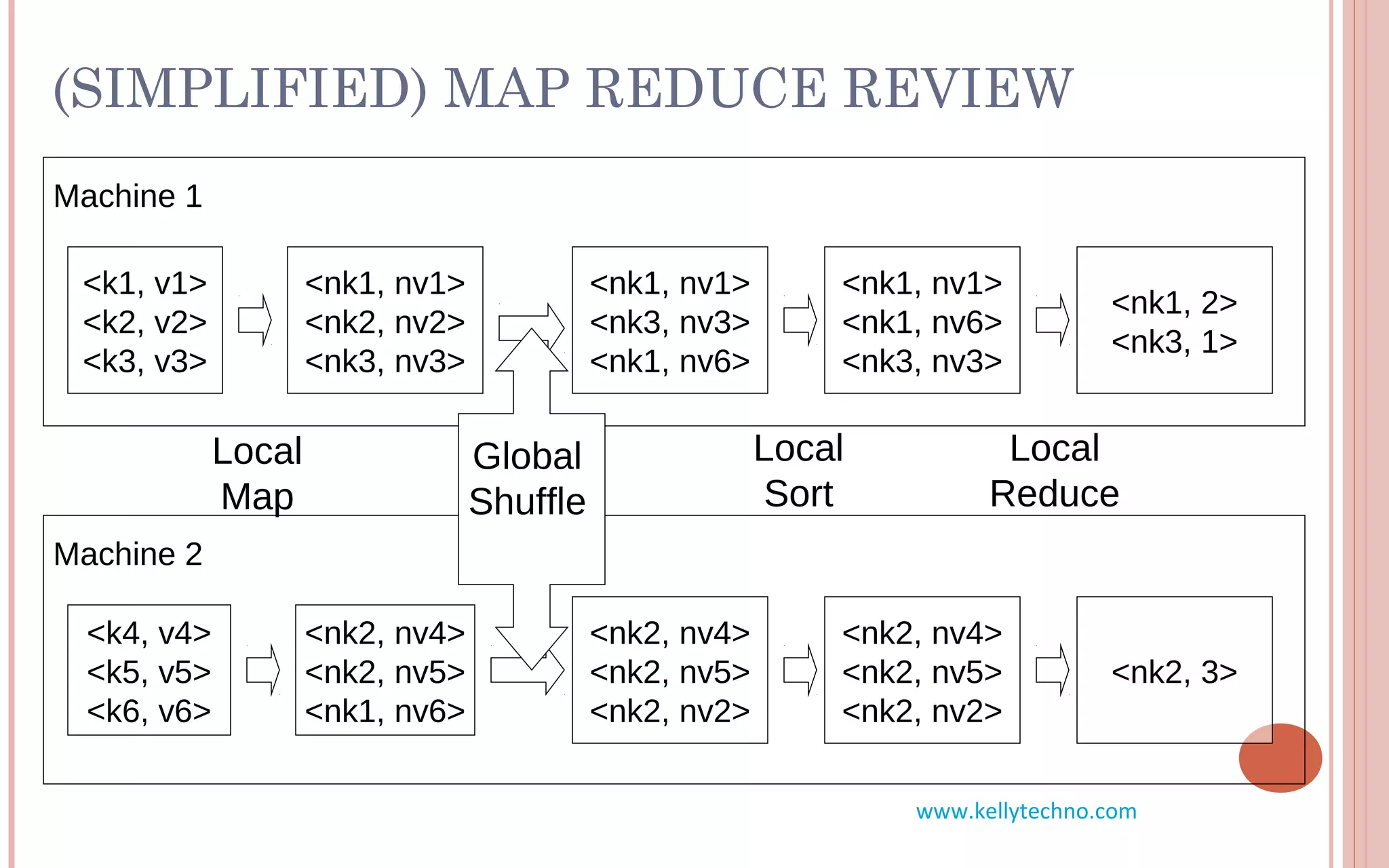
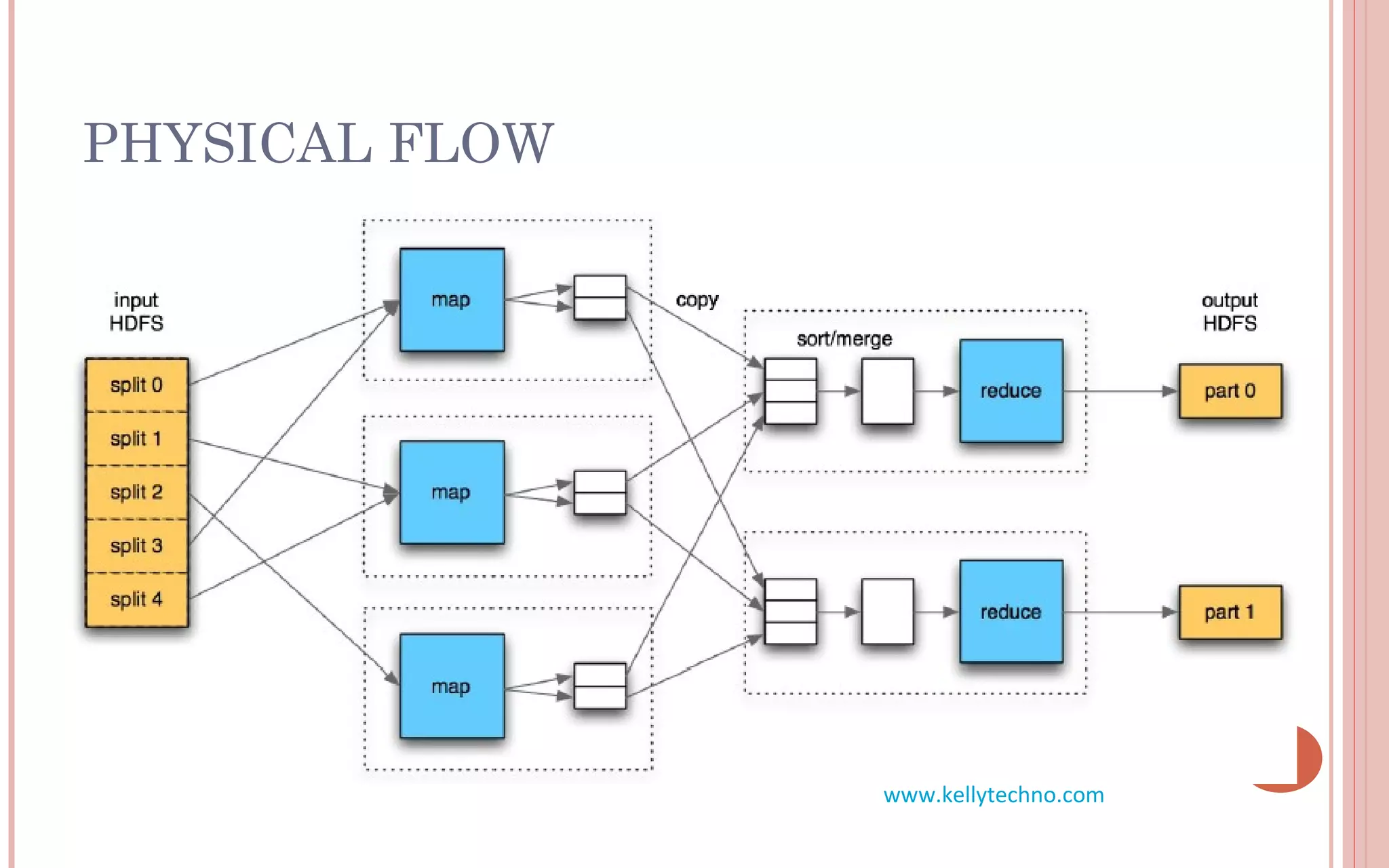
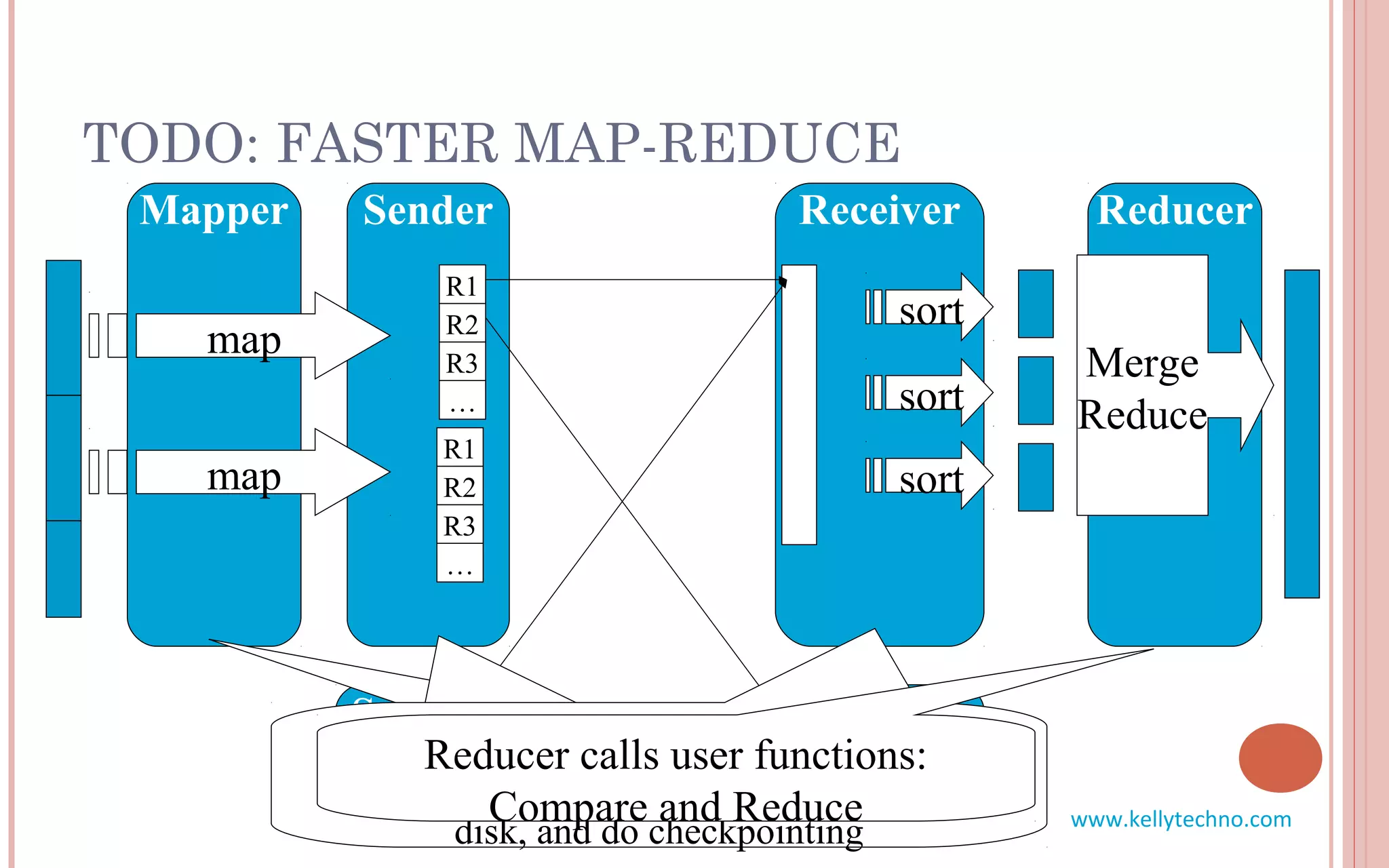
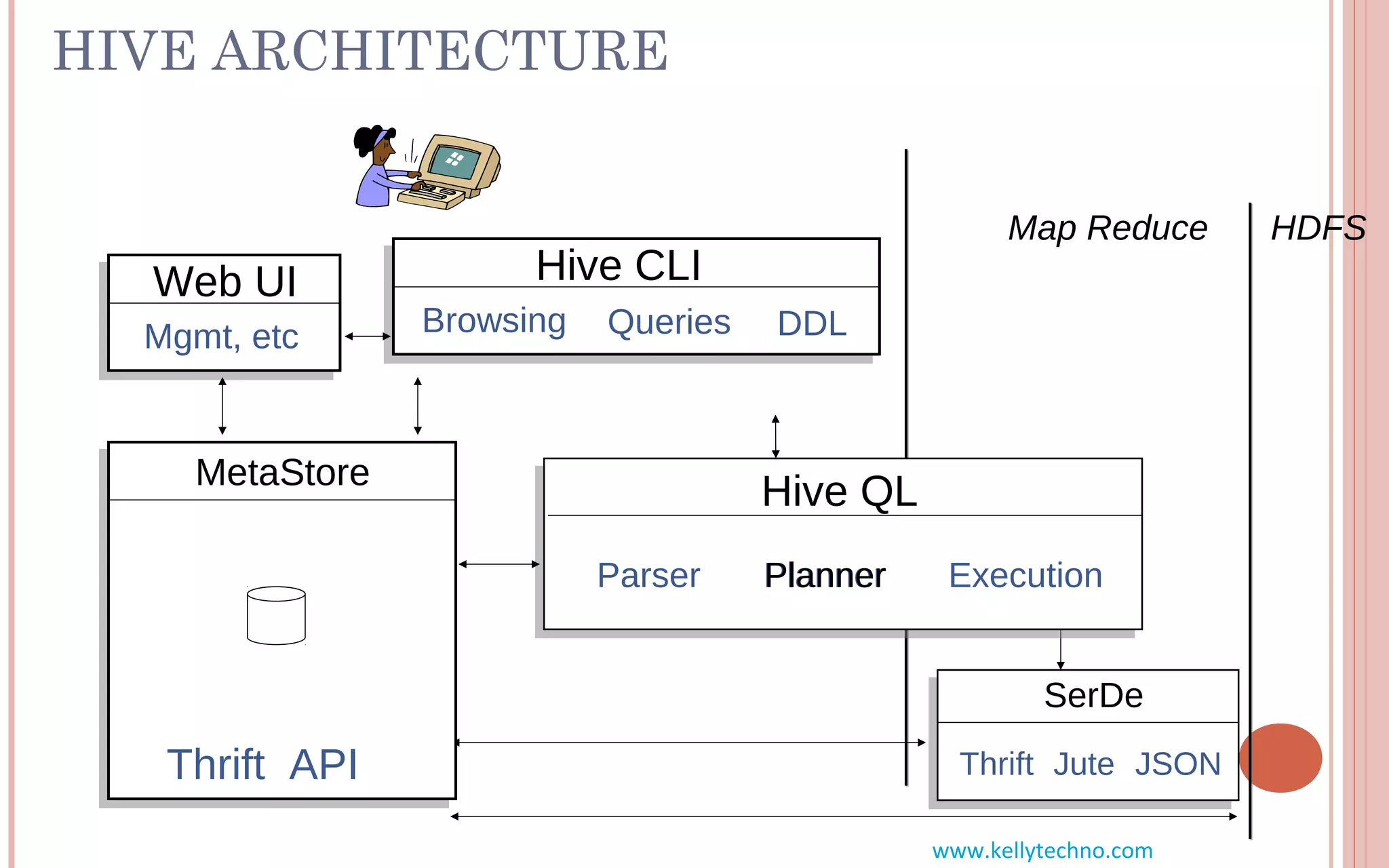
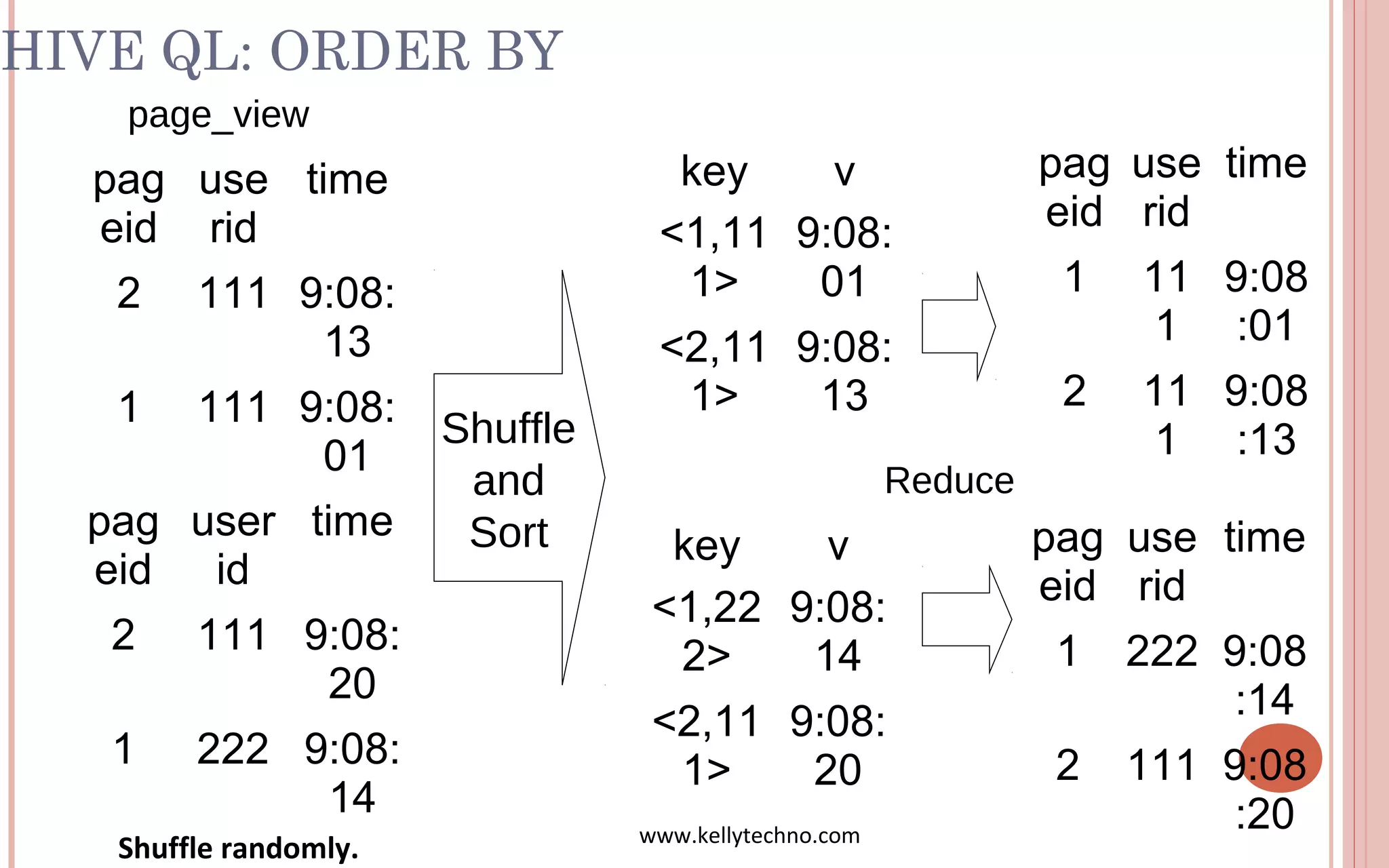
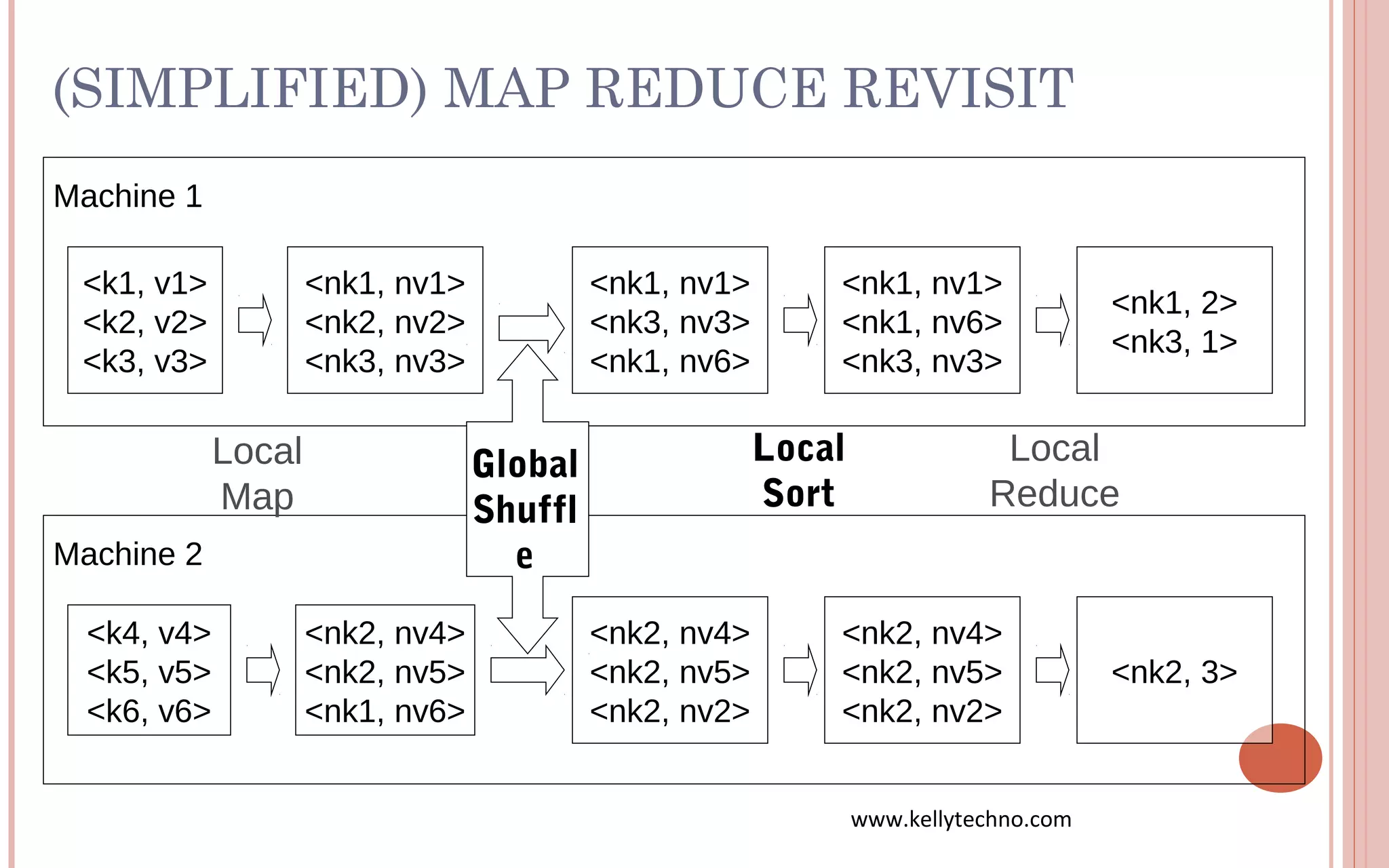
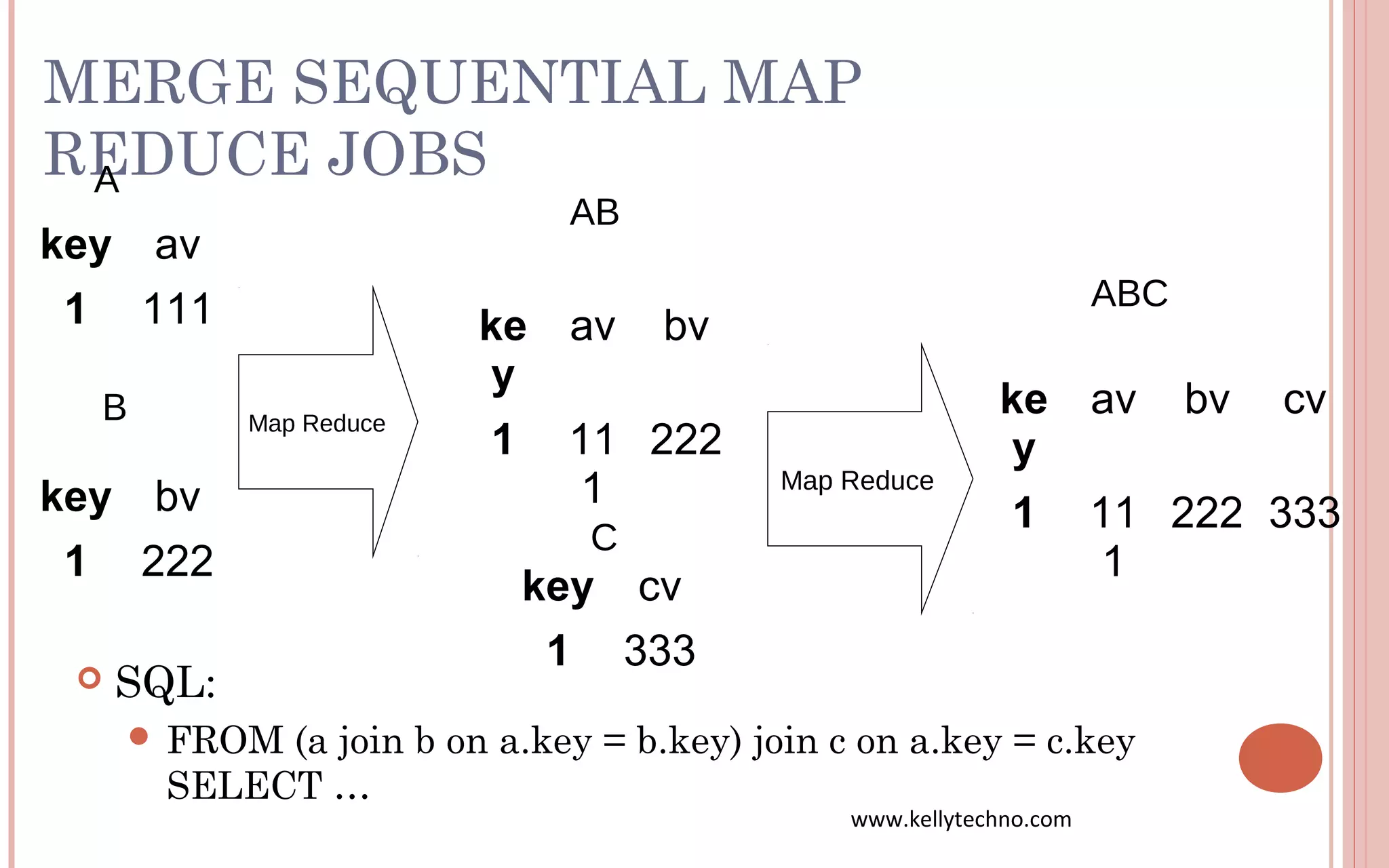
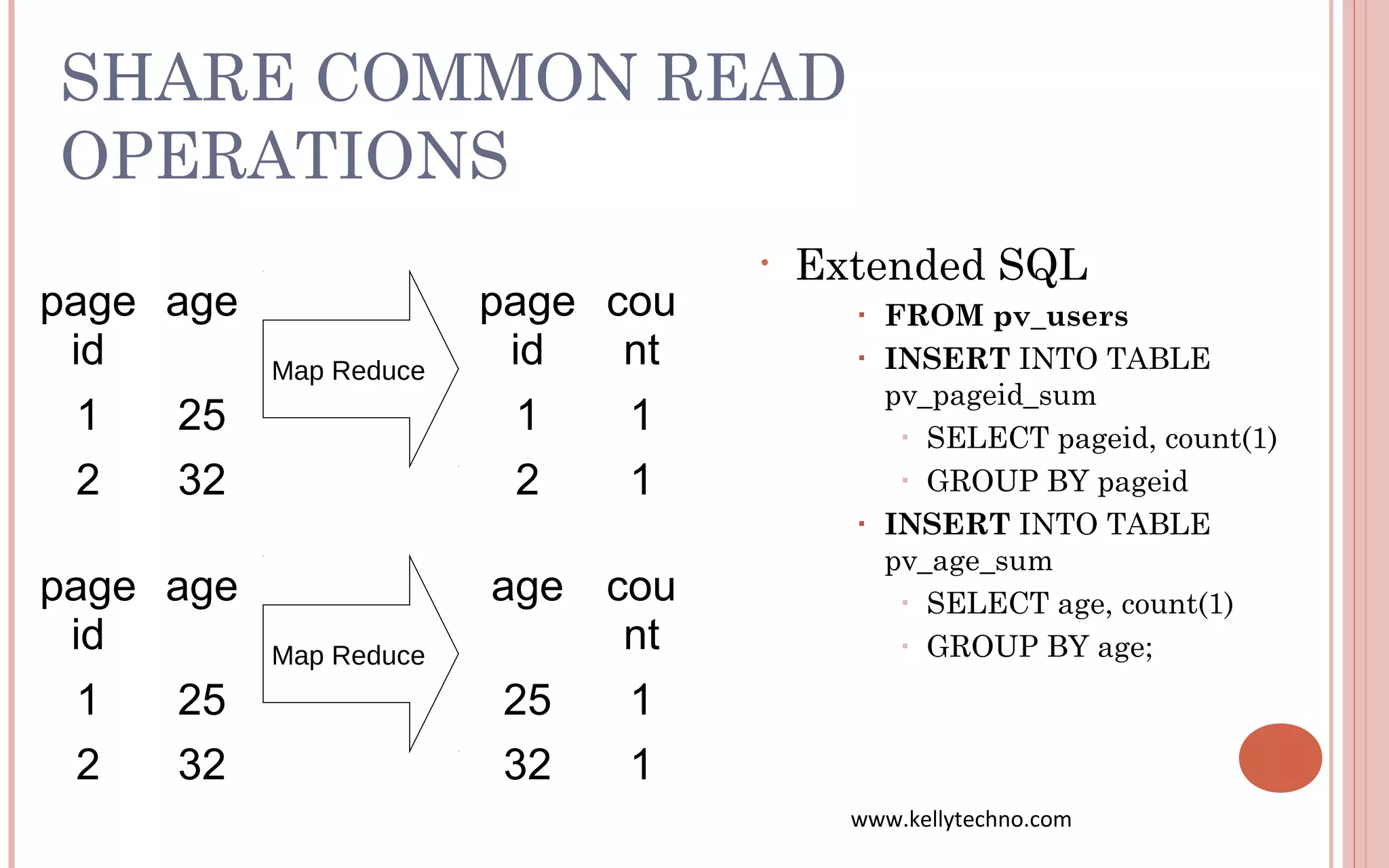
The document provides an in-depth overview of Hadoop and its components, highlighting its scalability solutions for large data handling and batch processing. It discusses the history and evolution of Hadoop, including technologies like HDFS, MapReduce, and Hive, while comparing Google's solutions with open-source counterparts. Additionally, it illustrates the architecture and functionalities of Hive, along with examples of query execution and optimizations in a distributed data processing context.