Downloaded 36 times













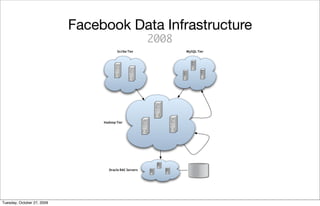
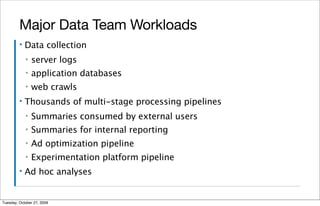






The document is a presentation about Hadoop and how it can be used to manage large amounts of data. It provides an overview of Hadoop, including what it is, how it works, and some of its main components like HDFS and MapReduce. It also discusses examples of how Hadoop has been implemented at large companies like Facebook and Yahoo to handle petabytes of data and power applications for tasks like analytics, search, and optimization. The presentation aims to explain the benefits of Hadoop for solving "big data" problems.





























![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































