Downloaded 33 times
![Hadoop Scalability at Facebook Dmytro Molkov ( [email_address] ) YaC, Moscow, September 19, 2011](https://image.slidesharecdn.com/molkovyacfinal-111009082009-phpapp01/85/Hadoop-Facebook-Facebook-1-320.jpg)
![Hadoop Scalability at Facebook Dmytro Molkov ( [email_address] ) YaC, Moscow, September 19, 2011](https://image.slidesharecdn.com/molkovyacfinal-111009082009-phpapp01/75/Hadoop-Facebook-Facebook-1-2048.jpg)















![facebook.com/dms [email_address] [email_address]](https://image.slidesharecdn.com/molkovyacfinal-111009082009-phpapp01/85/Hadoop-Facebook-Facebook-22-320.jpg)


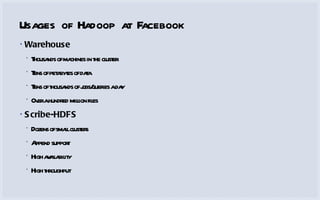
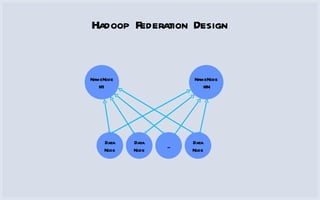
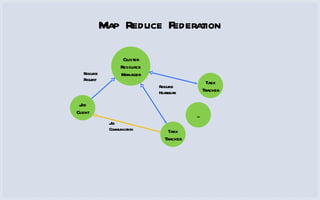
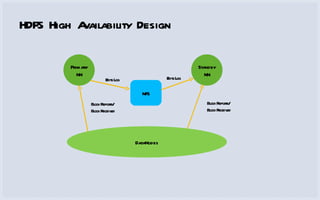
The document discusses how Facebook utilizes Hadoop for scalability and high availability, managing thousands of machines, petabytes of data, and numerous daily queries. It outlines various Hadoop applications, including real-time analytics and storage, while addressing challenges like bottlenecks in the namenode and jobtracker. Additionally, it describes HDFS federation and RAID strategies for efficient data replication and availability.































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
