Downloaded 21 times







![ff package
8Cdiscount.com - Commark
library(ffbase)
system.time(hhp <- read.table.ffdf(file="airlines.csv",
FUN = "read.csv", na.strings = "NA",
nrows=10000000))
#takes 1min40sec
#with no nrows arguement, message error,
# ffbase does not support char type
class(hhp)
dim(hhp)
str(hhp[1:10,])
result <- list()
## Some basic showoff
result$UniqueCarrier <- unique(hhp$UniqueCarrier)
#15 sec
## Basic example of operators is.na.ff, the ! operator and sum.ff
sum(!is.na(hhp$ArrDelay ))
## all and any
any(is.na(hhp$ArrDelay))
all(!is.na(hhp$ArrDelay))](https://image.slidesharecdn.com/gur1009-130910052936-phpapp01/85/Gur1009-8-320.jpg)





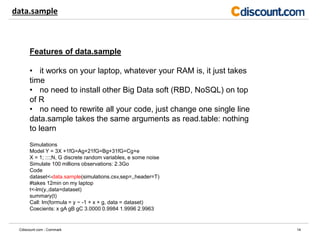

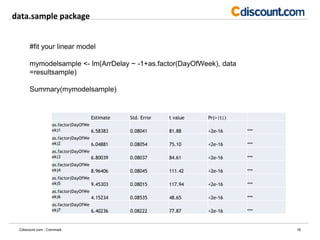

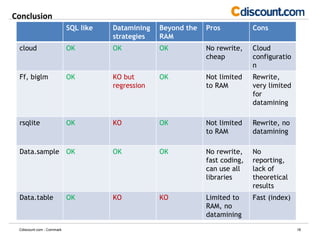

- The document discusses strategies for analyzing large datasets that are too big to fit into memory, including using cloud computing, the ff and rsqlite packages in R, and sampling with the data.sample package. - The ff and rsqlite packages allow working with data beyond RAM limits but require rewriting code, while data.sample provides sampling without rewriting code but introduces sampling error. - Cloud computing avoids rewriting code and has no memory limits but requires setup, and sampling is good for analysis but not reporting exact values.






































































































