Download as PDF, PPTX








![R- Import Data
> is.na(SOC)
Id UpperDepth LowerDepth SOC Lambda tsme Region
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[4,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[5,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[6,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[7,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[8,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[9,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[10,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
...](https://image.slidesharecdn.com/d3-1-esp-rdata-import-data-export-171020070115/85/9-R-data-import-data-export-8-320.jpg)
![R- Import Data
> anyNA(SOC)
[1] TRUE
> sum(is.na(SOC$SOC))
[1] 1](https://image.slidesharecdn.com/d3-1-esp-rdata-import-data-export-171020070115/85/9-R-data-import-data-export-9-320.jpg)









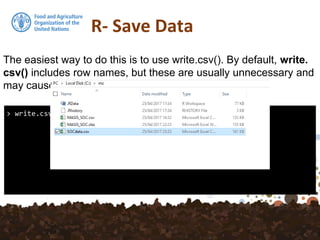



The document discusses various methods for importing and exporting data in R, focusing on functions such as read.table, read.csv, and other specialized functions for different file formats. It also covers how to interface with databases like PostgreSQL and handle spatial data using PostGIS. Furthermore, it includes details on saving data in various formats, emphasizing the importance of preserving data attributes.



































































