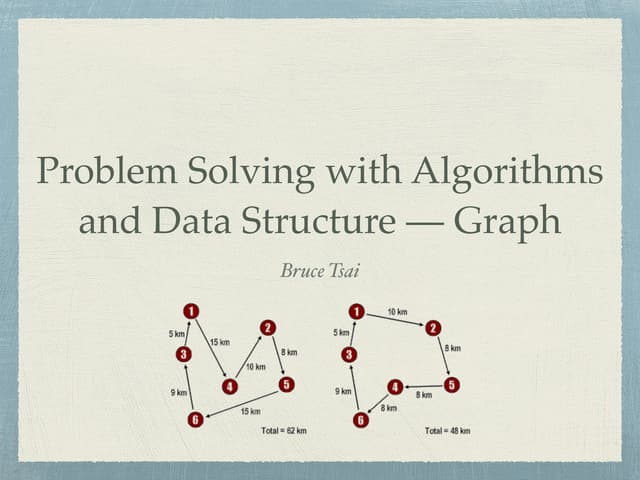
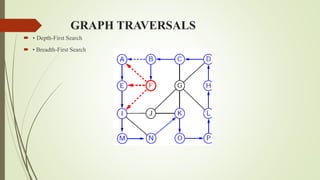
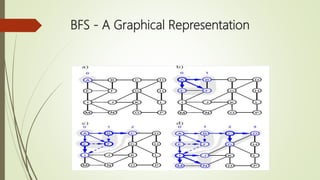
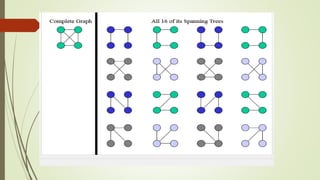
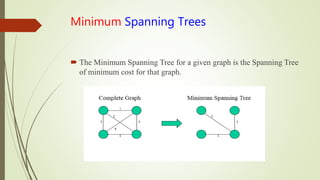
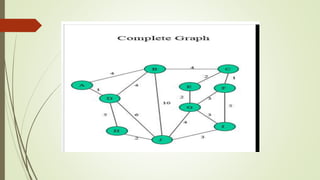
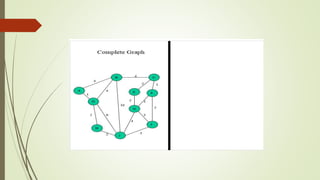
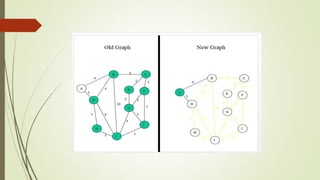
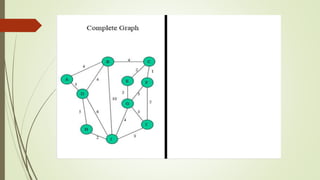
This document discusses different graph traversal algorithms including depth-first search (DFS) and breadth-first search (BFS). It provides descriptions of how DFS and BFS work by exploring edges and vertices in different orders. It also discusses minimum spanning trees and algorithms for finding minimum spanning trees, including Kruskal's algorithm, Prim's algorithm, and Boruvka's algorithm.
























![Data Structures - Lecture 10 [Graphs]](https://cdn.slidesharecdn.com/ss_thumbnails/datastructures-lecture10graphs-150305004608-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)