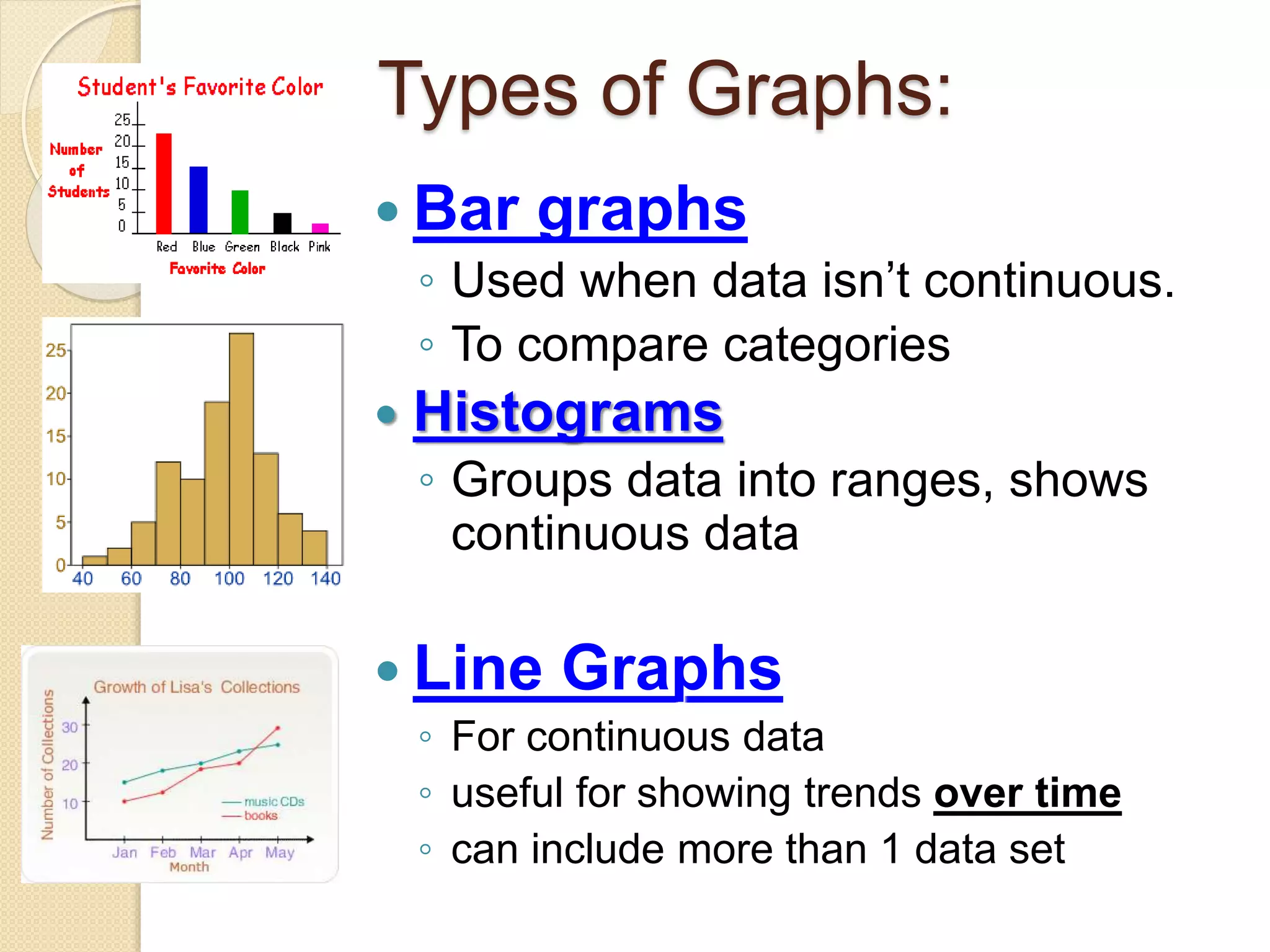
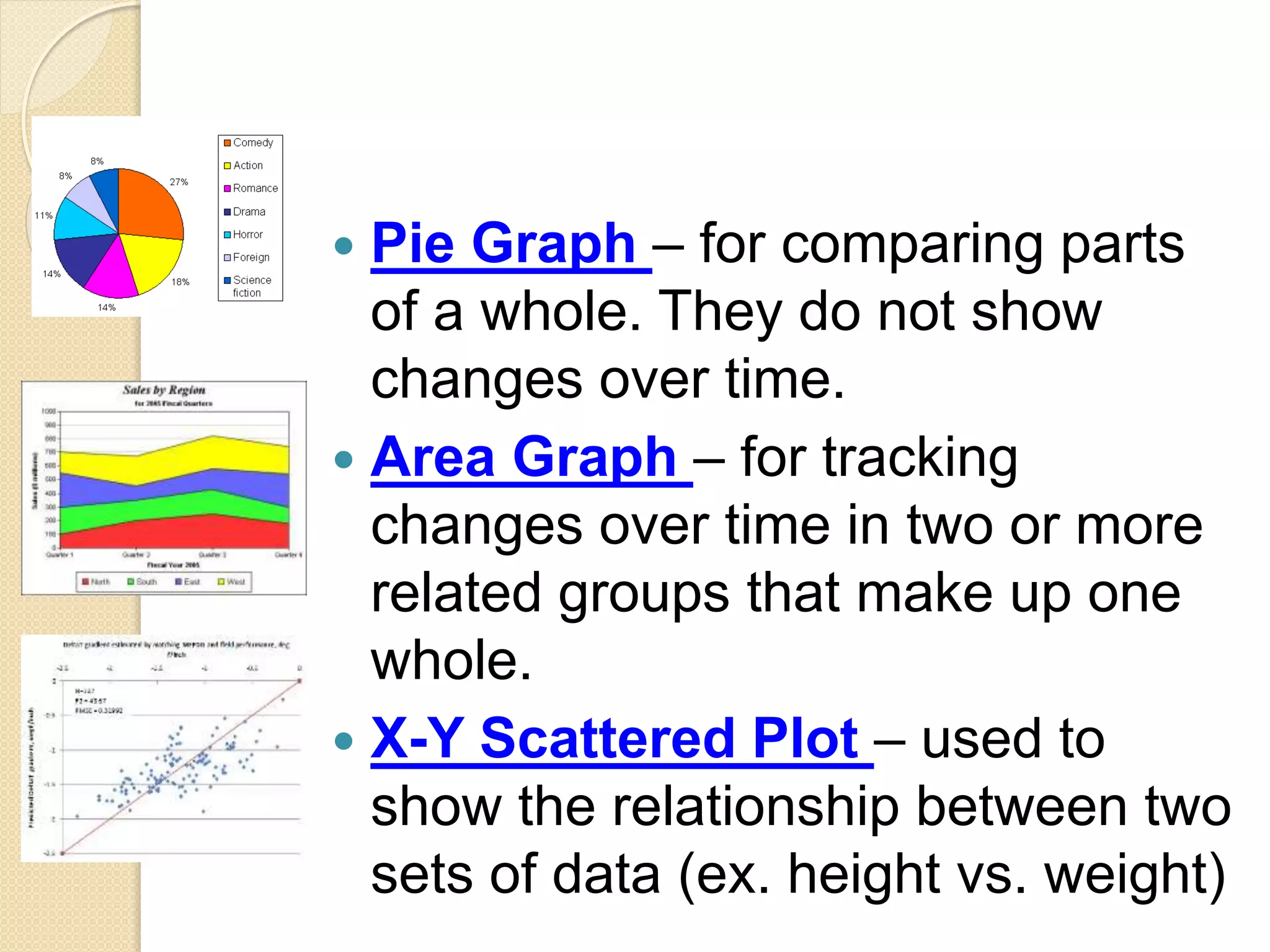
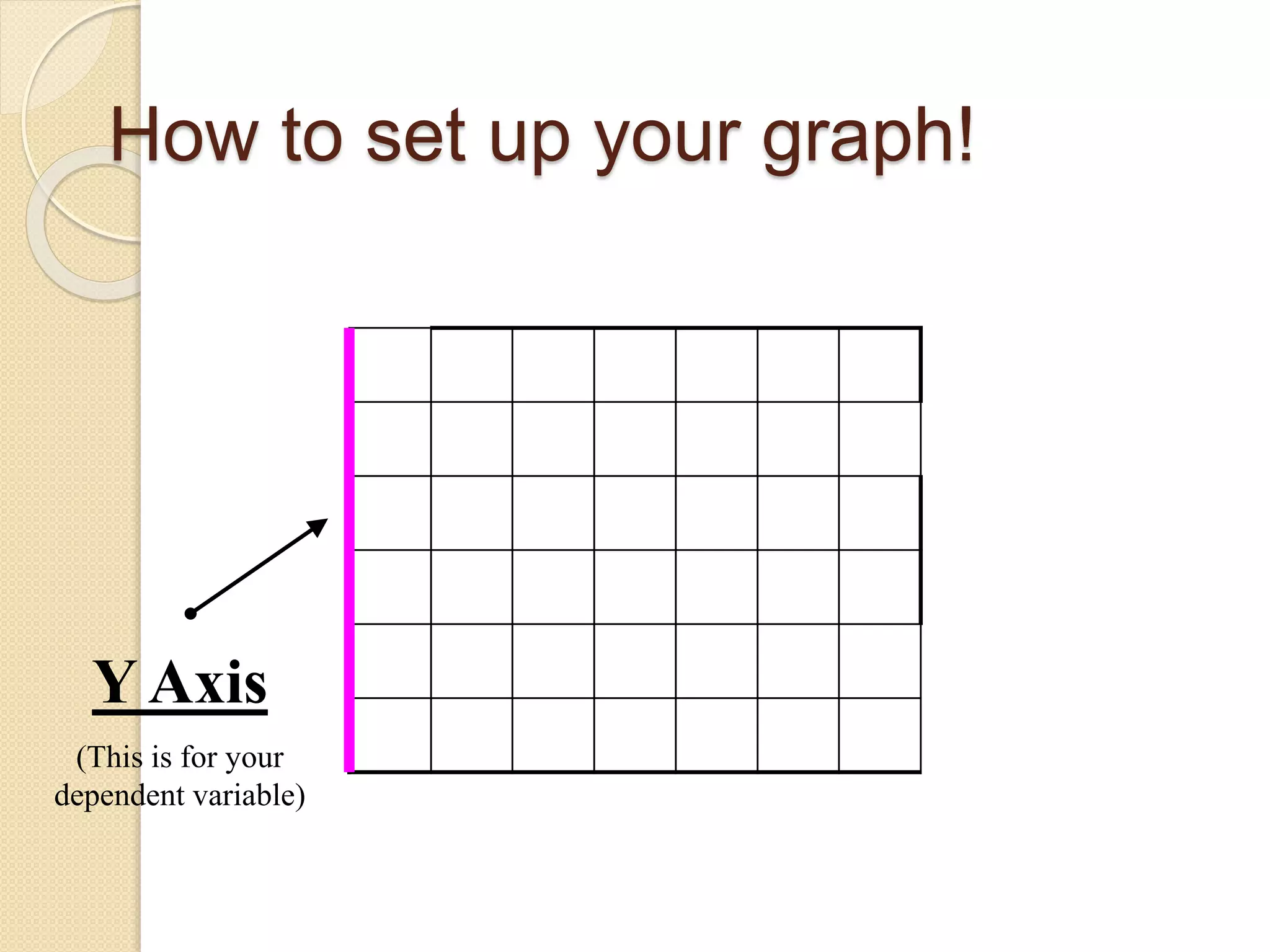
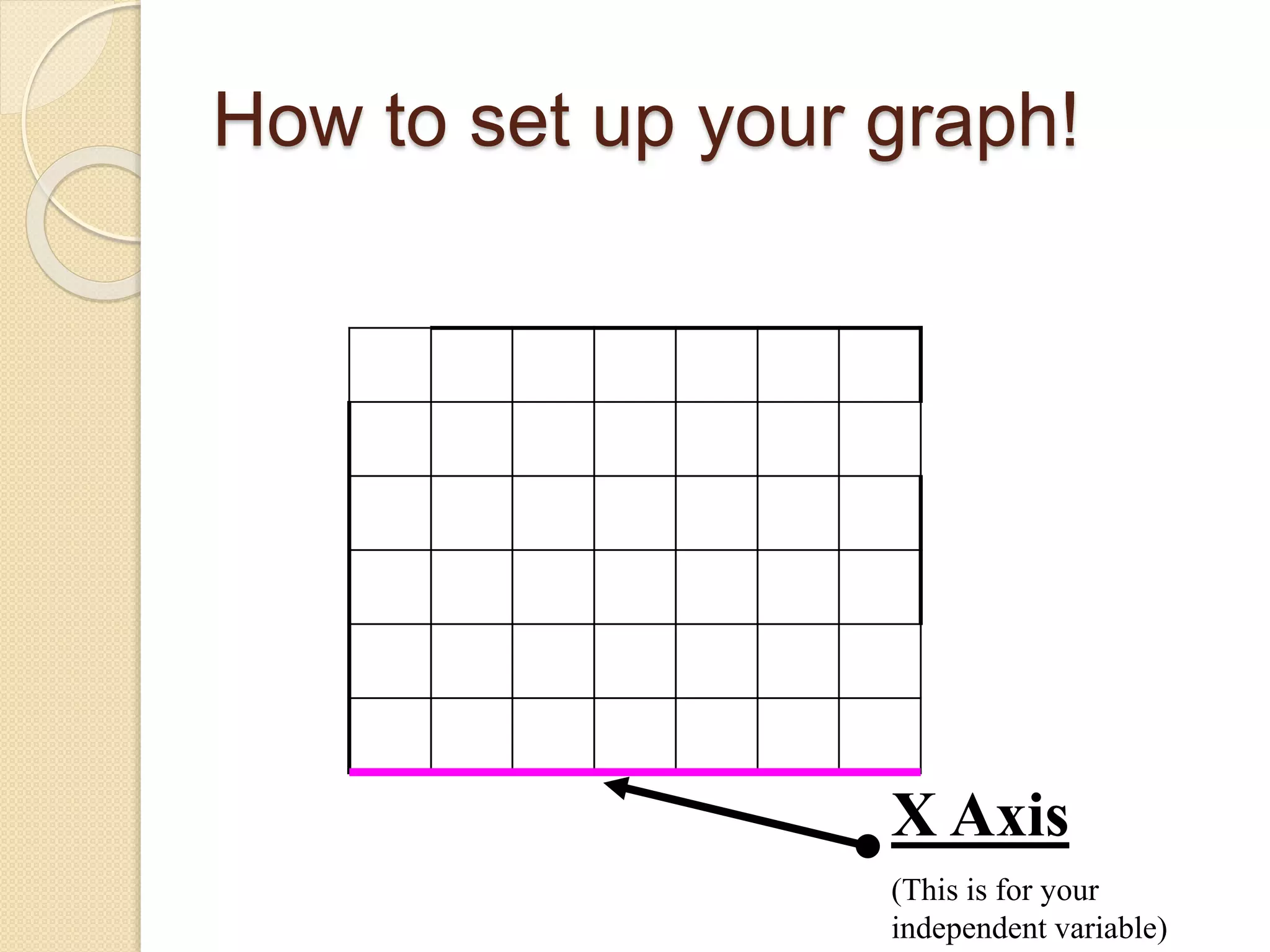
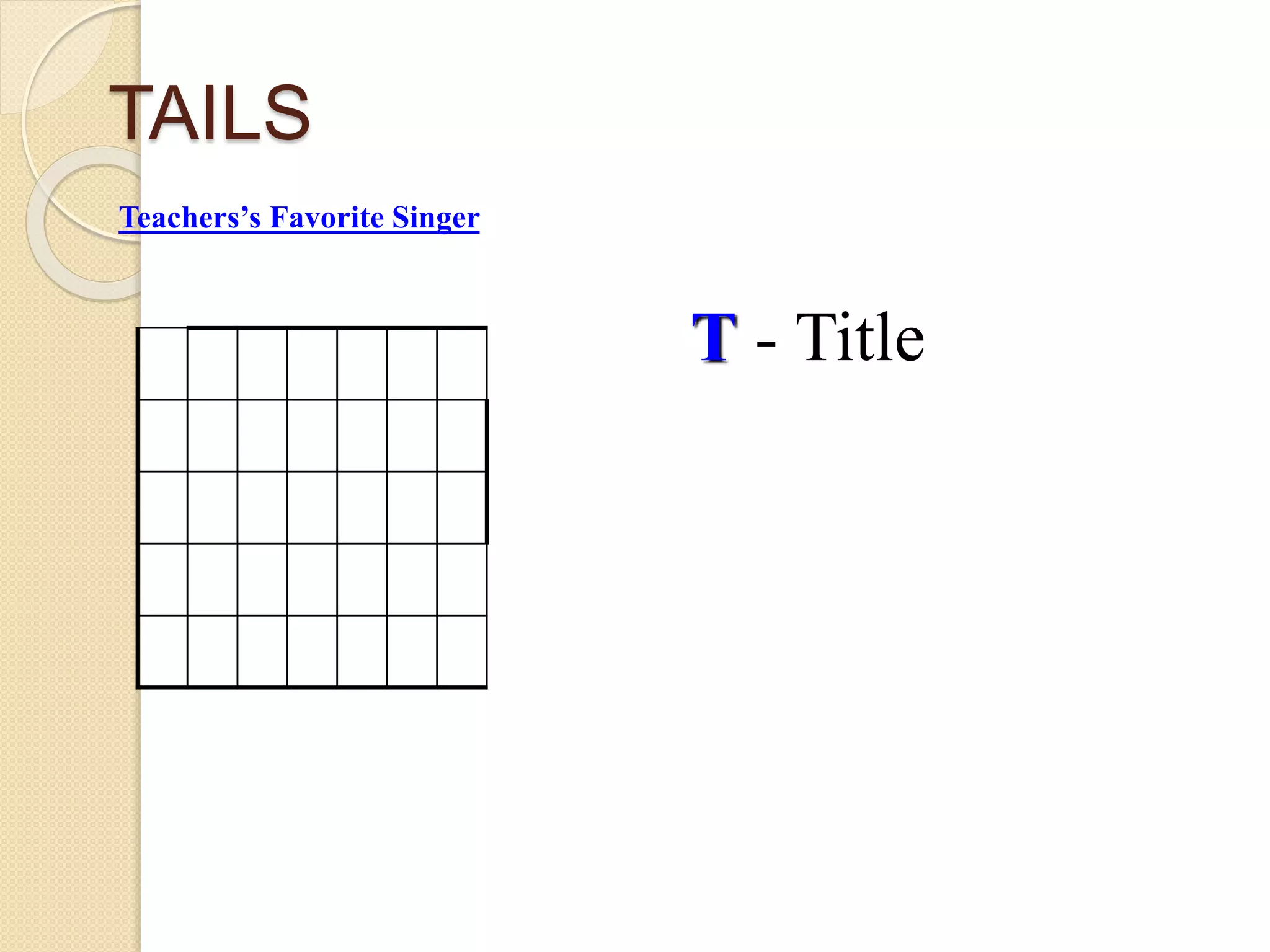
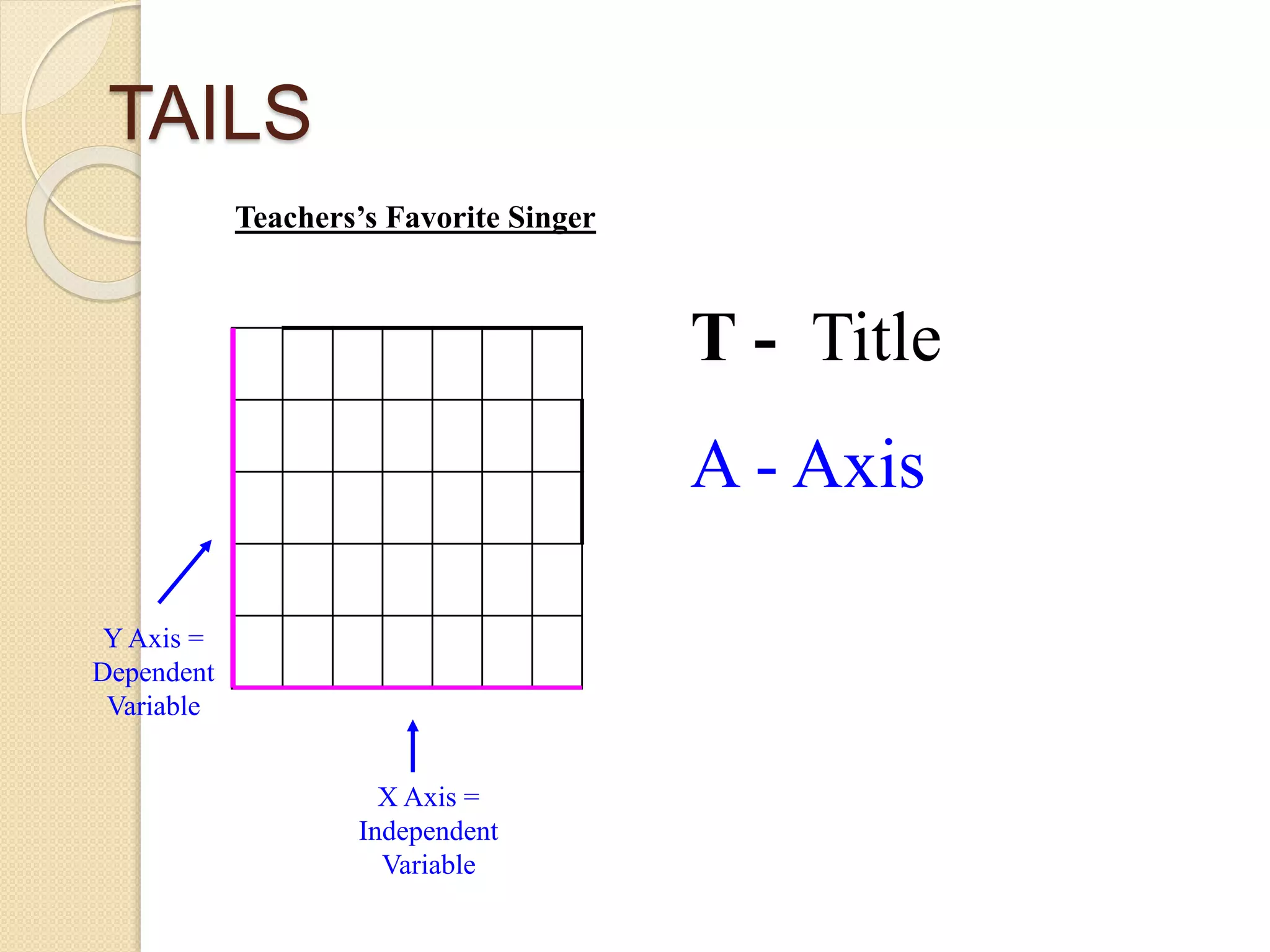
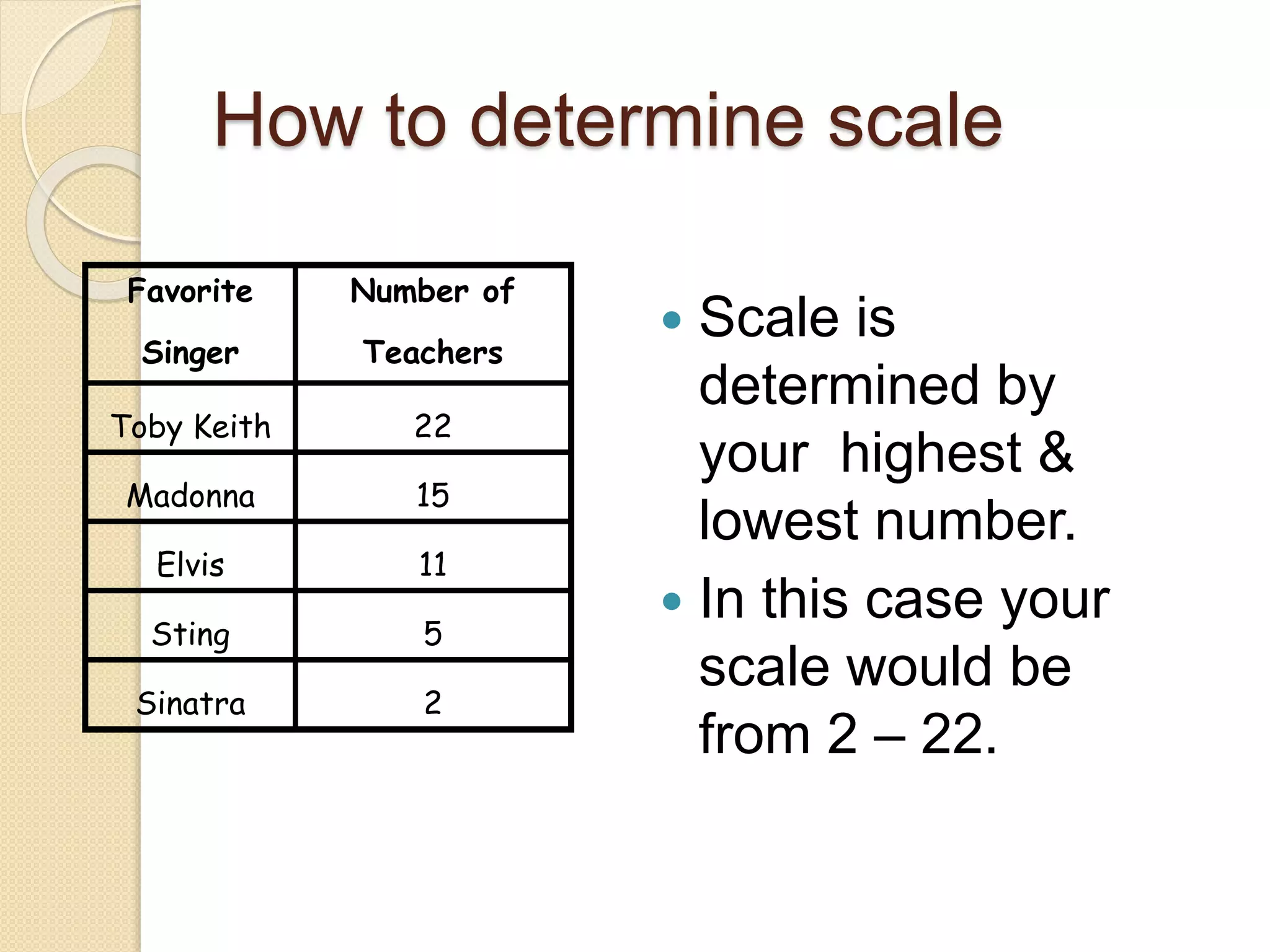
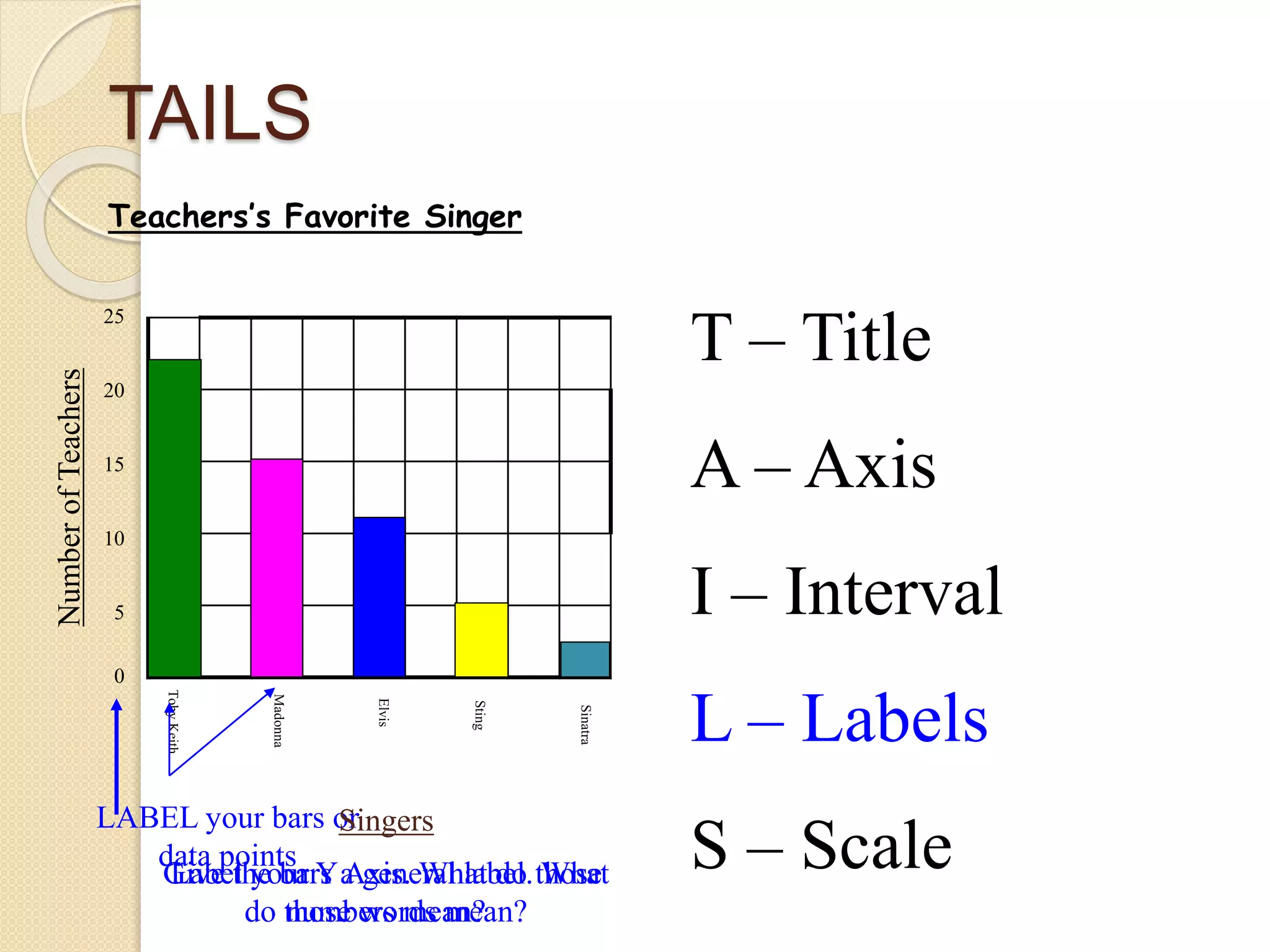
This document provides instruction on different types of graphs, including bar graphs, histograms, line graphs, pie charts, area graphs, and scatter plots. It discusses the key components of setting up a graph, including the title, axes, scale, intervals, and labels. Examples are given of experiments with identified dependent and independent variables and how they would be graphed. The document concludes with sample problems asking students to identify the appropriate graph, variables, and title and draw the graph to display the given data.