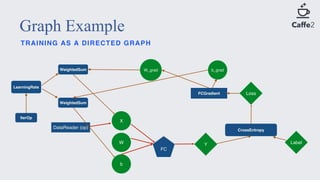
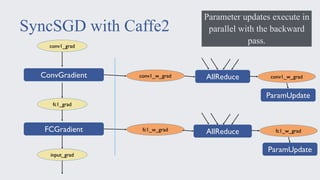
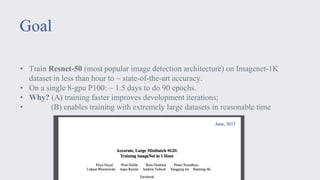
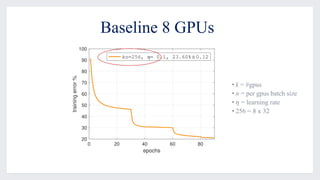
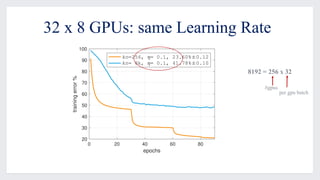
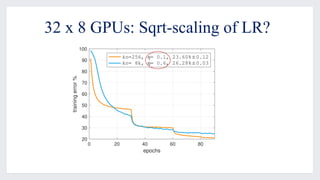
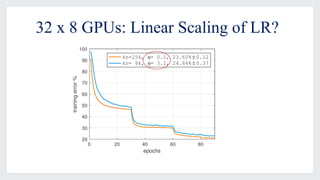
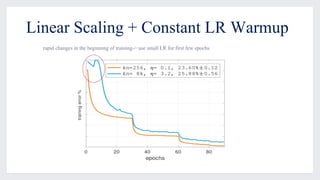
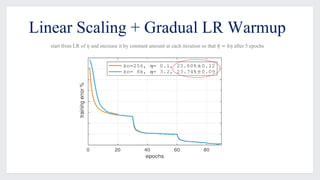
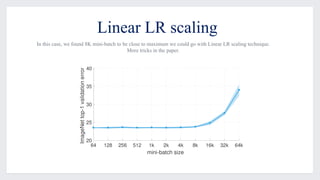
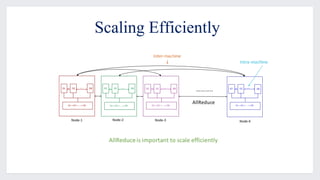
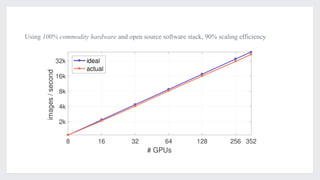
This document discusses large-scale distributed training with GPUs at Facebook using their Caffe2 framework. It describes how Facebook was able to train the ResNet-50 model on the ImageNet dataset in just 1 hour using 32 GPUs with 8 GPUs each. It explains how synchronous SGD was implemented in Caffe2 using Gloo for efficient all-reduce operations. Linear scaling of the learning rate with increased batch size was found to work best when gradually warming up the learning rate over the first few epochs. Nearly linear speedup was achieved using this approach on commodity hardware.













































![[Container X mas Party with flexy] Machine Learning Lifecycle with Kubeflow o...](https://cdn.slidesharecdn.com/ss_thumbnails/20181218kubeflowazurepublic-181218060359-thumbnail.jpg?width=640&height=640&fit=bounds)

















































