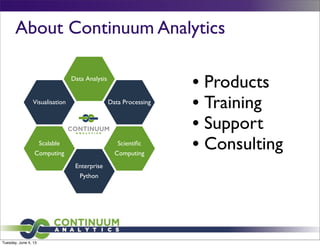
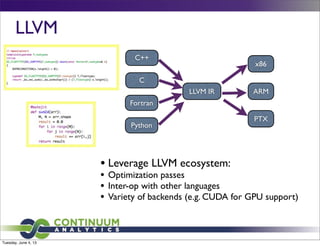
Numba is an open source just-in-time compiler for Python that uses the LLVM compiler infrastructure to generate optimized machine code from Python syntax. It allows Python code to be accelerated by running on multicore CPUs or GPUs. Numba can compile NumPy array expressions and ufuncs, parallel for loops, and user-defined Python functions to run at native speeds without rewriting in a different language. It provides an easy to use interface and can achieve large speedups of over 1000x compared to Python.





![Simple API
#@jit('void(double[:,:], double, double)')
@autojit
def numba_update(u, dx2, dy2):
nx, ny = u.shape
for i in xrange(1,nx-1):
for j in xrange(1, ny-1):
u[i,j] = ((u[i+1,j] + u[i-1,j]) * dy2 +
(u[i,j+1] + u[i,j-1]) * dx2) /
(2*(dx2+dy2))
Comment out one of jit or autojit (don’t use together)
• jit --- provide type information (fastest to call at run-time)
• autojit --- detects input types, infers output, generates code
if needed, and dispatches (a little more run-time call
overhead)
Tuesday, June 4, 13](https://image.slidesharecdn.com/buzzwordspresentation-130604161408-phpapp02/85/Buzzwords-Numba-Presentation-8-320.jpg)

![Compile NumPy array expressions
from numba import autojit
@autojit
def formula(a, b, c):
a[1:,1:] = a[1:,1:] + b[1:,:-1] + c[1:,:-1]
@autojit
def express(m1, m2):
m2[1:-1:2,0,...,::2] = (m1[1:-1:2,...,::2]
* m1[-2:1:-2,...,::2])
return m2
Tuesday, June 4, 13](https://image.slidesharecdn.com/buzzwordspresentation-130604161408-phpapp02/85/Buzzwords-Numba-Presentation-10-320.jpg)
![Fast vectorize
NumPy’s ufuncs take “kernels” and
apply the kernel element-by-element
over entire arrays Write kernels in
Python!
from numbapro import vectorize
from math import sin
@vectorize([‘f8(f8)’, ‘f4(f4)’])
def sinc(x):
if x==0.0:
return 1.0
else:
return sin(x*pi)/(pi*x)
Tuesday, June 4, 13](https://image.slidesharecdn.com/buzzwordspresentation-130604161408-phpapp02/85/Buzzwords-Numba-Presentation-11-320.jpg)
![Create parallel-for loops
“prange” directive that spawns compiled tasks
in threads (like Open-MP parallel-for pragma)
import numbapro
from numba import autojit, prange
@autojit
def parallel_sum2d(a):
sum = 0.0
for i in prange(a.shape[0]):
for j in range(a.shape[1]):
sum += a[i,j]
Tuesday, June 4, 13](https://image.slidesharecdn.com/buzzwordspresentation-130604161408-phpapp02/85/Buzzwords-Numba-Presentation-12-320.jpg)
![Example: MandelbrotVectorized
from numbapro import vectorize
sig = 'uint8(uint32, f4, f4, f4, f4, uint32, uint32,
uint32)'
@vectorize([sig], target='gpu')
def mandel(tid, min_x, max_x, min_y, max_y, width,
height, iters):
pixel_size_x = (max_x - min_x) / width
pixel_size_y = (max_y - min_y) / height
x = tid % width
y = tid / width
real = min_x + x * pixel_size_x
imag = min_y + y * pixel_size_y
c = complex(real, imag)
z = 0.0j
for i in range(iters):
z = z * z + c
if (z.real * z.real + z.imag * z.imag) >= 4:
return i
return 255
Kind Time Speed-up
Python 263.6 1.0x
CPU 2.639 100x
GPU 0.1676 1573x
Tesla S2050
Tuesday, June 4, 13](https://image.slidesharecdn.com/buzzwordspresentation-130604161408-phpapp02/85/Buzzwords-Numba-Presentation-13-320.jpg)













































