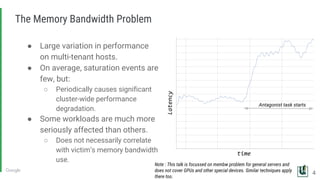
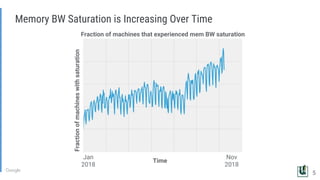
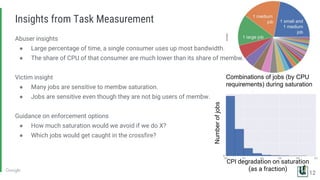
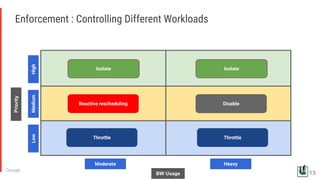
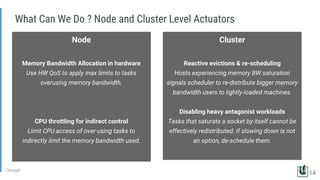
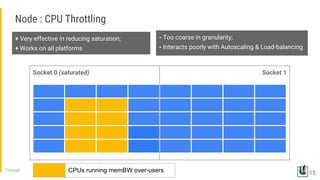
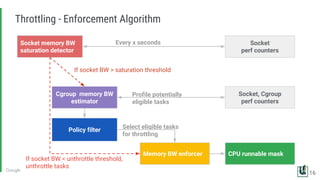
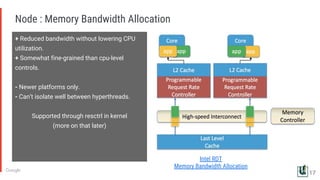
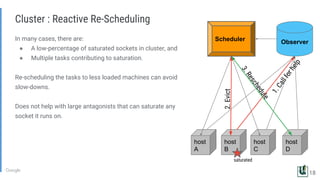
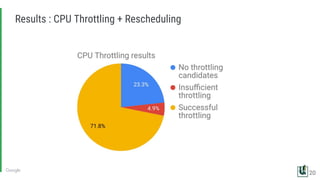
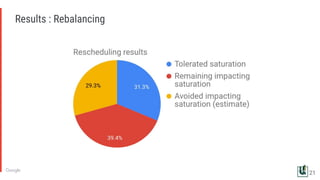
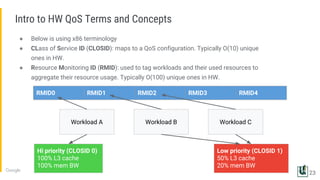
The document discusses the challenges of managing memory bandwidth in large multi-tenant clusters, focusing on monitoring and isolating workloads to prevent performance degradation. It examines strategies for identifying 'abuser' and 'victim' tasks, and proposes enforcement mechanisms like throttling and rescheduling to address memory bandwidth saturation. The use of hardware quality-of-service (QoS) interfaces such as resctrl is highlighted as a key innovation for improving memory bandwidth management across different platforms.




















![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Thu 430pm solarflare_tolley_v1[1]](https://cdn.slidesharecdn.com/ss_thumbnails/thu430pmsolarflaretolleyv11-130618183538-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























