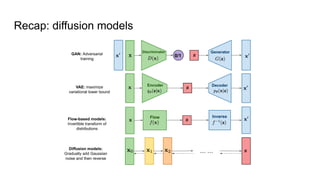
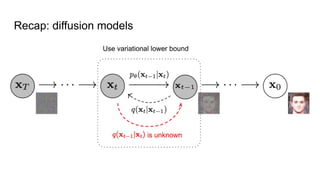
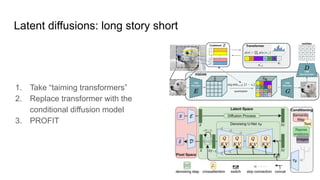
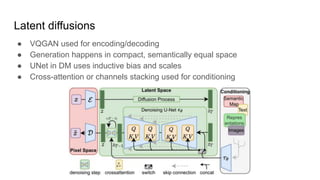
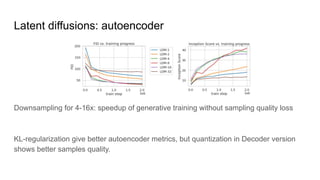
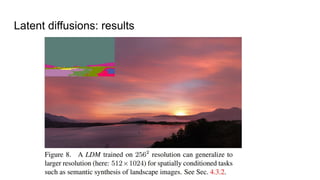
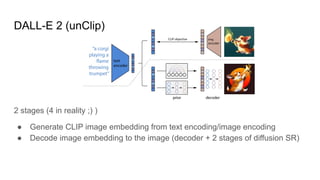
The document compares latent diffusion models and DALL-E 2, highlighting the methodologies and results of both. Latent diffusion models utilize autoencoders for image generation in a compact space, while DALL-E 2 employs a two-stage process for generating high-quality images from text using modified decoding techniques. It concludes that while latent diffusions offer open-source benefits and quick generation, DALL-E 2 delivers impressive results but remains proprietary and lacks transparency regarding its dataset and operational speed.