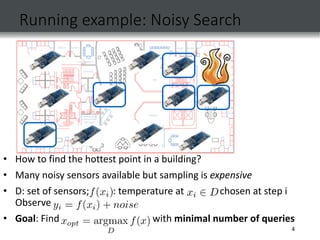
This document discusses Gaussian process bandit optimization, which is a method for adaptively sampling an unknown function to maximize its value. It proposes using an upper confidence bound (UCB) approach, where samples are selected to maximize an upper bound on the function value while also exploring uncertain regions. The key points are:
1) It proves regret bounds for UCB in this setting that depend on how quickly information can be gained about the function from samples, known as the maximal information gain.
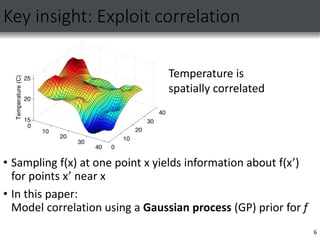
2) This connects Gaussian process bandit optimization to Bayesian experimental design, which aims to maximize information gain.
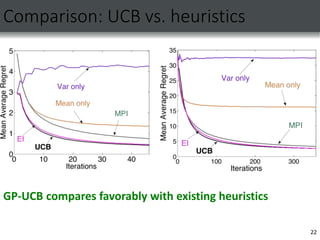
3) Experiments on temperature and traffic data show the UCB approach performs comparably to existing heuristics while providing the
![1
Multi-armed bandits
• At each time t pick arm i;
• get independent payoff ft with mean ui
• Classic model for exploration – exploitation tradeoff
• Extensively studied (Robbins ’52, Gittins ’79)
• Typically assume each arm is tried multiple times
• Goal: minimize regret
…
u1 u2 u3 uK
1
[ ]
t
T opt t
i
T E f
R
](https://image.slidesharecdn.com/gaussianpresentation-221214151217-cf773937/85/GAUSSIAN-PRESENTATION-ppt-1-320.jpg)

![Optimizing Noisy, Unknown Functions
• Given: Set of possible inputs D;
black-box access to unknown function f
• Want: Adaptive choice of inputs
from D maximizing
• Many applications: robotic control [Lizotte
et al. ’07], sponsored search [Pande &
Olston, ’07], clinical trials, …
• Sampling is expensive
• Algorithms evaluated using regret
Goal: minimize](https://image.slidesharecdn.com/gaussianpresentation-221214151217-cf773937/85/GAUSSIAN-PRESENTATION-ppt-3-320.jpg)

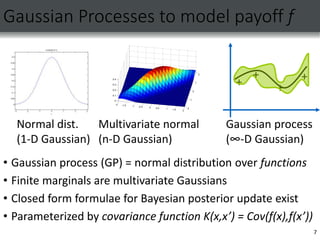
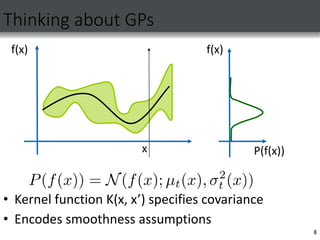

![Gaussian process optimization
[e.g., Jones et al ’98]
10
x
f(x)
Goal: Adaptively pick
inputs such that
Key question: how should we pick samples?
So far, only heuristics:
Expected Improvement [Močkus et al. ‘78]
Most Probable Improvement [Močkus ‘89]
Used successfully in machine learning [Ginsbourger et al. ‘08,
Jones ‘01, Lizotte et al. ’07]
No theoretical guarantees on their regret!](https://image.slidesharecdn.com/gaussianpresentation-221214151217-cf773937/85/GAUSSIAN-PRESENTATION-ppt-10-320.jpg)

![14
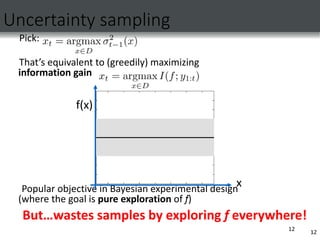
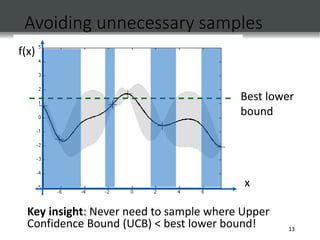
Upper Confidence Bound (UCB) Algorithm
Naturally trades off explore and exploit; no samples wasted
Regret bounds: classic [Auer ’02] & linear f [Dani et al. ‘07]
But none in the GP optimization setting! (popular heuristic)
x
f(x)
Pick input that maximizes Upper Confidence Bound (UCB):
How should
we choose ¯t?
Need theory!](https://image.slidesharecdn.com/gaussianpresentation-221214151217-cf773937/85/GAUSSIAN-PRESENTATION-ppt-14-320.jpg)
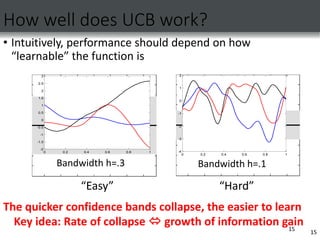

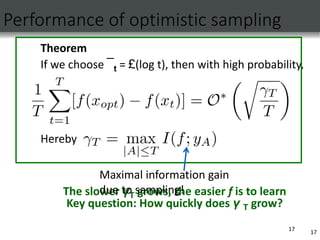
![Learnability and information gain
• Information gain exhibits diminishing returns (submodularity)
[Krause & Guestrin ’05]
• Our bounds depend on “rate” of diminishment
18
Little diminishing returns
Returns diminish fast](https://image.slidesharecdn.com/gaussianpresentation-221214151217-cf773937/85/GAUSSIAN-PRESENTATION-ppt-18-320.jpg)



![23
Assumptions on f
Linear?
[Dani et al, ’07]
Lipschitz-continuous
(bounded slope)
[Kleinberg ‘08]
Fast convergence;
But strong assumption
Very flexible, but](https://image.slidesharecdn.com/gaussianpresentation-221214151217-cf773937/85/GAUSSIAN-PRESENTATION-ppt-23-320.jpg)
















































