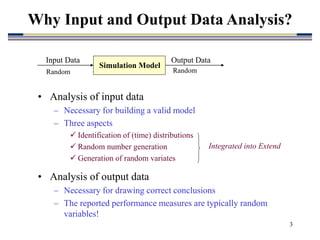
1. Input and output data analysis is necessary for building a valid simulation model and drawing correct conclusions from the model.
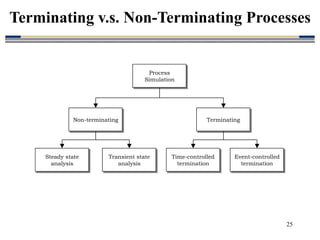
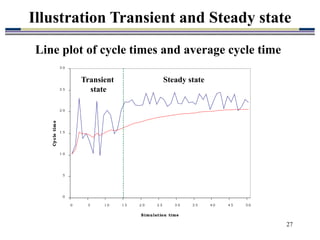
2. Key aspects of input data analysis include identifying appropriate time distributions from field data, generating random numbers, and producing random variates. Output data analysis considers non-terminating vs terminating processes, confidence intervals, and hypothesis testing for model comparisons.
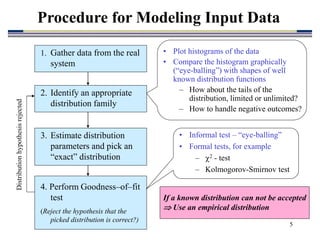
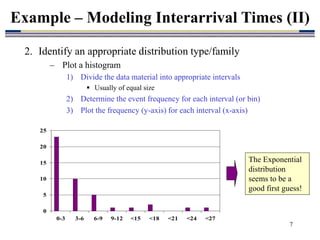
3. Common procedures for modeling input data include collecting field data, identifying a plausible distribution, estimating distribution parameters, and performing goodness-of-fit tests to validate the chosen distribution. Artificial data can also be generated if real data is unavailable or limited.









![12
2. Define r random variables Oi, i=1, 2, …r
– Oi=number of observations in bin i (= the interval (ai-1, ai])
– If H0 is true the expected value of Oi = n*pi
• Oi is Binomially distributed with parameters n and pi
3. Define the test variable T
Performing a 2-Test (III)
r
1
i i
2
i
i
p
n
p
n
O
T
– If H0 is true T follows a 2(r-k-1) distribution
– T = The critical value of T corresponding to a significance level
obtained from a 2(r-k-1) distribution table
– Tobs = The value of T computed from the data material
If Tobs > T H0 can be rejected on the significance level ](https://image.slidesharecdn.com/ch09-simulation-230115070819-5e03670d/85/ch09-Simulation-ppt-12-320.jpg)









![23
• Assume random numbers, r, from a Uniform (0, 1) distribution
are available
Random numbers from any distribution can be obtained by applying the
“inverse transformation technique”
The inverse Transformation Technique
1. Generate a U[0, 1] distributed random number r
2. T is a random variable with a CDF FT(t) from which we would
like to obtain a sequence of random numbers
– Note: 0 FT(t) 1 for all values of t
Generating Random Variates
)
r
(
F
t
t
for
solve
and
r
)
t
(
F
Let 1
T
T
t is a random number from the distribution of T, i.e., a realization of T](https://image.slidesharecdn.com/ch09-simulation-230115070819-5e03670d/85/ch09-Simulation-ppt-23-320.jpg)





![31
Characteristics of the point estimate for the population mean
– Xi = Random variable representing the value of the ith observation in a
sample of size n, (i=1, 2, …, n)
– Assume that all observations Xi are independent random variables
– The population mean = E[Xi]=
– The population standard deviation=(Var[Xi])0.5=
– Point estimate of the population mean=
– Mean and Std. Dev. of the point estimate for the population mean
Confidence Interval for Population Means (I)
n
X
X
X
X n
2
1
n
n
n
X
E
X
E
X
E
X
E n
2
1
n
n
n
n
)
X
(
Var
)
X
(
Var
)
X
(
Var 2
2
2
2
1
x
](https://image.slidesharecdn.com/ch09-simulation-230115070819-5e03670d/85/ch09-Simulation-ppt-31-320.jpg)

































































