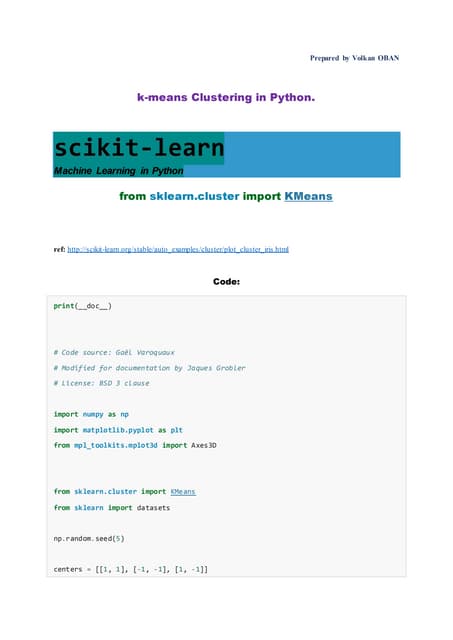
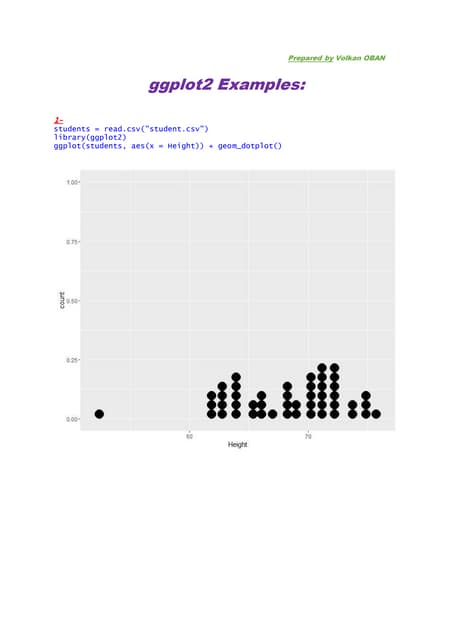
Downloaded 31 times




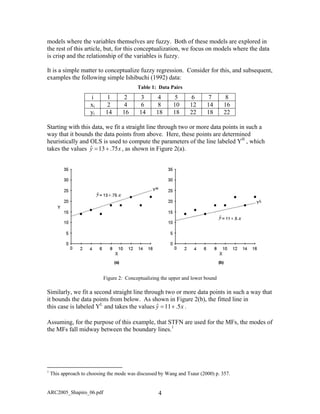
![For any given data pair, (xi, yi), the foregoing conceptualizations can be summarized by
the fuzzy regression interval [Y shown in Figure 3.]Y, U
i
L
i
2
Figure 3: Fuzzy Regression Interval
1h
iY =
is the mode of the MF and if a SFTN is assumed, )/2Y(YY L
i
U
ii
1h
i +===
)Y,Y, 1h
i
L
i
U
i
=
L
iY
Y . Given
the parameters, (YU
,YL
, Yh=1
), which characterize the fuzzy regression model, the i-th
data pair (xi,yi), is associated with the model parameters (Y . From a
regression perspective, we can view - yU
iY
U
iY -
i and yi - as components of the SST, yL
iY
1h
i
=
i -
as a component of SSE, and and - as components of the SSR, as
discussed by Wang and Tsaur (2000).
1h
iY = 1h
iY =
Y
In possibilistic regression based on STFN, only the data points involved in determining
the upper and lower bounds determine the structure of the model, as depicted in Figure 2.
The rest of the data points have no impact on the structure. This problem is resolved by
using asymmetric TFNs.
2.3 The Fuzzy Coefficients
Combining Equation (1) and Figure 1, and, for the present, restricting the discussion to
STFNs, the MF of the j-th coefficient, may be defined as:
−
−= 0,
||
1max)(
j
j
A
c
aa
aj
µ (3)
where aj is the mode and cj is the spread, and represented as shown in Figure 4.
ARC2005_Shapiro_06.pdf 5
2
Adapted from Wang and Tsaur (2000), Figure 1.](https://image.slidesharecdn.com/arch06v40n1-ii-160614164740/85/Fuzzy-Regression-Model-5-320.jpg)



![3.1 Criticisms of the Possibilistic Regression Model
There are a number of criticisms of the possibilistic regression model. Some of the major
ones are the following:
• Tanaka et al "used linear programming techniques to develop a model superficially
resembling linear regression, but it is unclear what the relation is to a least-squares
concept, or that any measure of best fit by residuals is present." [Diamond (1988:
141-2)]
• The original Tanaka model was extremely sensitive to the outliers. [Peters (1994)].
• There is no proper interpretation about the fuzzy regression interval [Wang and
Tsaur (2000)]
• Issue of forecasting have to be addressed [Savic and Pedrycz (1991)]
• The fuzzy linear regression may tend to become multicollinear as more independent
variables are collected [Kim et al (1996)].
• The solution is xj point-of-reference dependent, in the sense that the predicted
function will be very different if we first subtract the mean of the independent
variables, using (xj - ix ) instead of xj. [Hojati (2004), Bardossy (1990) and Bardossy
et al (1990)]
4 The Fuzzy Least-Squares Regression (FLSR) Model
An obvious way to bring the FR more in line with statistical regression is to model the
fuzzy regression along the same lines. In the case of a single explanatory variable, we
start with the standard linear regression model: [Kao and Chyu (2003)]
(8)m1,2,...,i,εxββy ii10i =++=
which in a comparable fuzzy model might take the form:
m1,2,...,i,ε~X
~
ββY
~
ii10i =++= (9)
Conceptually, the relationship between the fuzzy i-th response and explanatory variables
in (9) can be represented as shown in Figure 10.
ARC2005_Shapiro_06.pdf 11](https://image.slidesharecdn.com/arch06v40n1-ii-160614164740/85/Fuzzy-Regression-Model-11-320.jpg)
![Figure 10: Fuzzy i-th response and explanatory variables
Rearranging the terms in (9),
m1,2,...,i,X
~
ββY
~
ε~
i10ii =−−= (10)
From a least-squares perspective, the problem then becomes
2
10
1
)
~~
(min i
n
i
i XbbY −−∑
=
(11)
There are a number of ways to implement FLSR, but the two basic approaches are FLSR
using distance measures and FLSR using compatibility measures. A description of these
methods follows.
4.1 FLSR using Distance Measures (Diamond's Approach)
Diamond (1988) was the first to implement the FLSR using distance measures and his
methodology is the most commonly used. Essentially, he defined an L2
- metric d(.,.)2
between two TFNs by [Diamond (1988: 143) equation (2)]
(12)( ) ( )
( )2
2211
2
2211
2
21
2
222111
)()(
)()()(,,,,,
rmrm
lmlmmmrlmrlmd
+−++
−−−+−=
Given TFNs, it provides a measure of the distance between two fuzzy numbers based on
their modes, left spread and right spread.7
7
The methods of Diamond's paper are rigorously justified by a projection-type theorem for cones on a
Banach space containing the cone of triangular fuzzy numbers, where a Banach space is a normed vector
space that is complete as a metric space under the metric d(x, y) = ||x-y|| induced by the norm.
ARC2005_Shapiro_06.pdf 12](https://image.slidesharecdn.com/arch06v40n1-ii-160614164740/85/Fuzzy-Regression-Model-12-320.jpg)

![4.2 FLSR using compatibility measures
An alternate least-squares approach is based on the Celmiņš (1987) compatibility
(18)
As indicated, when the
odes of the MFs coincide.
elmiņš compatibility model, which involved maximizing the compatibility between the
(19)
Thus, for example, when there is a single crisp expla
(2001: 190)]
(20)
m1 are determined using weighted LS regression, and c0, c1, and c01 are
determined using iteration and the desired compatibility measure.
measure
(),(min{max)
~
,
~
( XBA µµγ =
representative examples of which are shown in Figure 11.8
Figure 11: Celmiņš Compatibility Measure
γ ranges from 0, when the MFs are mutually exclusive, to 1,
m
C
data and the fitted model, follows from this measure. The objective function is
natory variable, [Chang and Ayyub
1=
−
m
iγ
i
)}XBA
x
2
)1(∑
22
101010
10
2
~~ˆ
xcxccxmm
xAAY
++±+=
+=
where m0 and
8
Adapted from Chang and Ayyub (2001), Figure 2.
ARC2005_Shapiro_06.pdf 14](https://image.slidesharecdn.com/arch06v40n1-ii-160614164740/85/Fuzzy-Regression-Model-14-320.jpg)




This document discusses fuzzy regression models. It begins by introducing fuzzy regression and its motivation for addressing situations where classical regression is problematic, such as small data sets or vagueness in relationships. It then defines the components of fuzzy regression models, including fuzzy coefficients represented by triangular membership functions. Two approaches to fuzzy regression are explored: Tanaka's possibilistic regression which minimizes coefficient fuzziness, and fuzzy least squares regression. The document uses a sample data set to illustrate key concepts throughout.




































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)







![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)





