1
Python - RandomForest Parametreleri ve Bias-Varyans
Hazırlayan: VOLKAN OBAN
n_estimators-(integer)- Default=10
Tahminleri için, bir Rasgele Orman içinde inşa etmek istediğiniz ağaç sayısı. Sayı ne kadar
yüksekse, kodunuzun çalışması için daha uzun süreceğini bilmek önemlidir. Bilgisayarınızın
işlem hızıyla ilgili önceki bilgilere dayanarak, bu hıza orantılı bir n_estimator oluşturmak
gerekli.
criterion-(string)-Default =”gini”
Bölünmede kullanılan ölçüt. Gini, Entropy.
max_features-(integer,float,string,ya da None) -
Default=”auto”
En iyi bölünme bulunurken göz önüne alınan maksimum özellik sayısı. Bu, her bir ağacın her
düğümü artık daha fazla sayıda seçenek göz önüne alındığında, modelin performansını
2.
2
geliştirir. Bir kezdaha, özellik sayısını artırarak işlem hızınız azalacaktır. max_features, daha
karmaşık parametrelerden biridir çünkü bu, sizin ayarladığınız türe bağlıdır.
Eğer bir tamsayı ise o zaman, her bir bölümdeki max_features hakkında dikkatlice
düşünmelidir, çünkü sayı temelde size kalmıştır. Otomatik veya sqrt olarak ayarlanırsa, özellik
sayısının kareköküne ayarlanır (sqrt (n_features)). Eğer log2'ye ayarlarsanız log2'ye eşittir
(n_features). Beklenmedikçe, hiçbiri özelliklerin sayısını veya n_feature kullanmaz.
n_features : Verideki özelliklerin sayısı.
Not:
İyi değer olarak max_features=sqrt(n_features) (default case) bulunmuştur.
Bir düğümü ayırırken göz önünde bulundurulması gereken özelliklerin rastgele alt kümelerinin
boyutudur. Ne kadar düşük olursa, varyans o kadar azalır.
max_depth-(integer or none)- Default=None
Bu, ağaçlarınızı ne kadar derin yapmak istediğinizi seçer. Max_depth'inizi ayarlamanızı
önerilir, çünkü overfitting baş etmek için önerilir.
- Ağacın kökü ve yapraklar arasındaki maksimum bağlantı sayısı. Küçük olmalı.
min_samples_split-(integer, float)-Default=2
Bir bölünmenin gerçekleşmesi için verilerinizde bulunması gereken minimum örnek
sayısını ayarlar. Eğer bir float ise o zaman min_samples_split * n_samples ile
hesaplanır.
NOT: İyi sonuçlar genellikle max_depth = None ayarında min_samples_split = 1 ile
birlikte yapılır. Bununla birlikte, bu değerleri kullanmanın çok fazla belleği işgal eden
modellerle sonuçlanabileceğini unutmayın.
min_samples_leaf-(integer,float)-Default=1
Bu parametre, her karar ağacının son düğümünün minimum boyutunu belirlemenize
yardımcı olur. Uç düğüm ayrıca yaprak olarak bilinir.
Bir yaprak düğümünde olması gereken minimum örnek sayısı, varsayılan olarak 1'e
ayarlanır. Bazı durumlarda artırılması halinde, overfitting i önlemede yardımcı olabilir.
3.
3
min_weight_fraction_leaf-(float)-Default=0
Bu, min_samples_leafile oldukça benzerdir, ancak bunun yerine toplam gözlem
sayısının bölümü kullanır.
max_leaf_nodes-(integer, None)-Default=None
Bu parametre ağacı en iyi şekilde büyütür ve bu da impurity(saflığı, düzeni bozan)
nispi bir azalmaya neden olur
min_impurity_decrease-(float)-Default=0
Bir bölünme, bu değere eşit olan impurity azalmasına neden olursa, bir düğüm
bölünecektir.
Node impurity, ağaçların özellikleri (verileri ) nasıl böldüğünü gösterir.
n_jobs-(integer)-Default=1
Bu, bilgisayarın kaç işlemcinin kullanılmasına izin verdiğini bilmesini sağlar. Varsayılan 1
değeri sadece bir işlemci kullanabileceği anlamına gelir. -1 kullanırsanız, kodun ne kadar
işlem gücü kullanabileceğine dair bir kısıtlama olmadığı anlamına gelir. N_jobs öğenizi -1
olarak ayarlamak genellikle daha hızlı işlemeye neden olur
Boostrap: Var olan veri seti üzerinden, rastgele örneklem seçimi ile ilgili yöntem.
random_state-(integer, RandomState instance, None)-
Default=None
Boostrap işlemi rastgele örnekler oluşturduğundan, sonuçların çoğaltılması genellikle
zordur. Bu parametre, aynı eğitim verileri ve parametreleri verildiğinde diğerlerinin
sonuçlarınızı çoğaltmasını kolaylaştırır.
verbose-(integer)-Default=0
Verbose, modelin işlendiği gibi ne yaptığına dair sürekli güncellemeler sağlayan logging
output ayarladığınız anlamına gelir. Bu parametre ağacın yapım sürecinin ayrıntılarını
ayarlar. Her zaman kullanışlı değildir.
warm_start-(boolean)-Default=False
Regresyon modelindeki Backward Elimination a benzer olarak kullanılır. Yanlış
olduğunda, doğru olduğu durumdakinin aksine, yeni bir tahminleyici kullanmak, önceki
uygun çözümü yeniden kullanmak yerine, yeni bir orman oluşturur.
4.
4
Yinelemeli özellik seçimi(recursive feature selection) için genellikle kullanılmaktadır.
class_weight-(dictionary, list of dictionaries, “balanced”)
oob_score = True
Bu rasgele bir orman çapraz doğrulama(cross valiadation) yöntemidir.
Örnek: RandomForestClassifier(n_estimators=10000, criterion='entropy', max_depth=10000,
max_leaf_nodes=None, bootstrap=True, oob_score=False,
n_jobs=1, random_state=None, verbose=0)
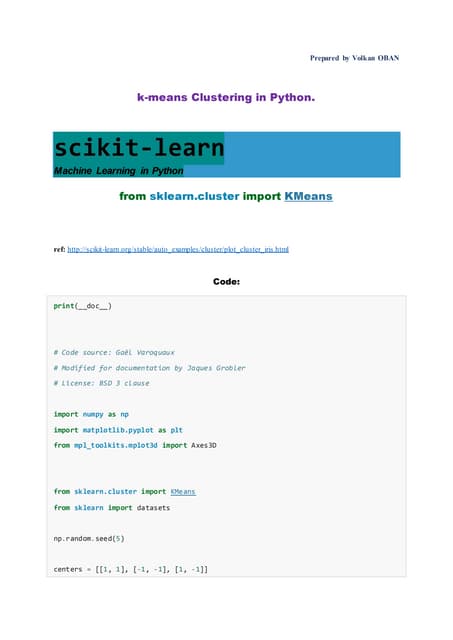
Bias, amaç(target) fonksiyonun öğrenilmesini kolaylaştırmak için, model tarafından
yapılan basitleştirici varsayımlardır. Modelinizin beklenen tahminleri ile gerçek değerler
arasındaki farktır.
Eğitim verilerinin zayıf bir şekilde uydurulması modeline atıfta bulunur, ancak eğitim
verilerinin dışındaki verilerde benzer sonuçlar üretebilir. Bu underfitting ile ilgilidir.
Bias nedeniyle oluşan hata, modelimizin beklenen (veya ortalama) tahmini ile tahmin
etmeye çalıştığımız doğru değer arasındaki fark olarak alınır.
Bias=underfitting
Low(Düşük) Bias: Amaç fonksiyonu hakkında daha az varsayım önerir.
Örnek: Decision Trees, k-Nearest Neighbors and Support Vector Machine
High(Yüksek) Bias: Amaç fonksiyonu hakkında daha fazla varsayım önerir.
High bias high training error
Örnek: Linear Regression, Linear Discriminant Analysis and Logistic Regression
Varyans, farklı eğitim verilerinin kullanılması durumunda amaç fonksiyonun tahmininin
değişme miktardır.
Yöntemin seçilen giriş verilerine ne kadar duyarlı olduğunu göstermek için 'varyans'
kullanılır.
Varyanstan kaynaklanan hata, belirli bir veri noktası için model tahmininin değişkenliği
olarak alınır.
Low(Düşük) Variance: Eğitim veri kümesindeki değişikler, amaç fonksiyonu üzerinde
küçük değişimlere neden olmaktadır.
Örnek: Linear Regression, Linear Discriminant Analysis and Logistic Regression.
High(Yüksek) Variance: Eğitim veri kümesindeki değişikler, amaç fonksiyonu üzerinde
büyük değişimlere neden olmaktadır.
Örnek: Decision Trees, k-Nearest Neighbors and Support Vector Machines
5.
5
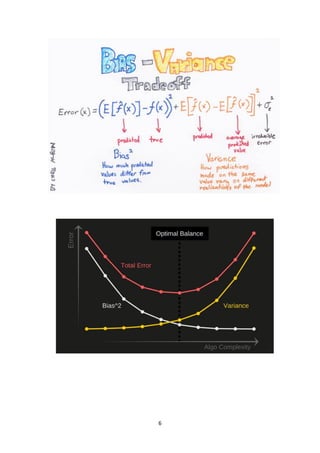
Bias-Variance Trade-Off
Supervised (denetimli)bir makine öğrenme algoritmasının amacı, düşük bias ve düşük
varyans elde etmektir.
Parametrik veya doğrusal makine öğrenimi algoritmaları genellikle yüksek bir
biasa sahiptir, ancak düşük bir varyansa sahiptir. (Lojistik Regresyon)
Parametrik olmayan veya doğrusal olmayan makine öğrenimi algoritmaları
genellikle bias sahiptir, ancak yüksek bir varyansa sahiptir. (Karar Destek
Makinaları)
7
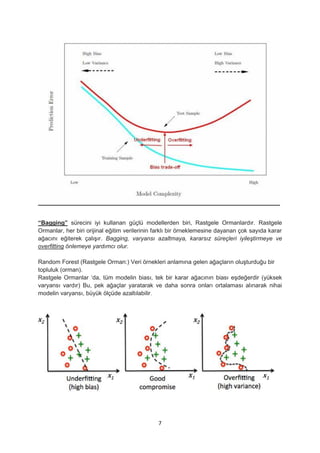
“Bagging” sürecini iyikullanan güçlü modellerden biri, Rastgele Ormanlardır. Rastgele
Ormanlar, her biri orijinal eğitim verilerinin farklı bir örneklemesine dayanan çok sayıda karar
ağacını eğiterek çalışır. Bagging, varyansı azaltmaya, kararsız süreçleri iyileştirmeye ve
overfitting önlemeye yardımcı olur.
Random Forest (Rastgele Orman:) Veri örnekleri anlamına gelen ağaçların oluşturduğu bir
topluluk (orman).
Rastgele Ormanlar ‘da, tüm modelin biası, tek bir karar ağacının biası eşdeğerdir (yüksek
varyansı vardır) Bu, pek ağaçlar yaratarak ve daha sonra onları ortalaması alınarak nihai
modelin varyansı, büyük ölçüde azaltılabilir.
8.
8
Decision Tree: DüşükBias - Yüksek Variance
Karar ağaçlarında, ağaç budama(pruning) varyansı azaltmak için bir yöntemdir
Yüksek varyansınız olduğunda, daha fazla eğitim verisi alın.
Metrikler:
Accuracy=(tp+tn)/total
Precision=tp/(tp+fp)
Recall=Sensitivity=tp/(tp+fn)
Specificity=tn/(fp+tn)
F1=2∗(precision∗recall)/(precision+recall)
Total: Total number of observations
Ensemble yöntemi, çeşitli makine öğrenme tekniklerini kullanarak, varyansı, biası
azaltmak veya tahminleri geliştirmek için, tek bir tahmin modelini kullanan tekniktir.
Ensemble modeller: Bagging Yöntemi ve Boosting yöntemi, birleşik tahmin edicinin
biasını azaltmaya çalışır. Örneğin, AdaBoost ve Gradient Tree Boosting
9.
9
Python içerisinde, RandomForest benzer tekniklerden bir tanesi de, ExtraTreesClassifier
yöntemidir.Daha gelişmiş Ensemble tekniklerden biri, Stochastic Gradient Boosting
[GradientBoostingClassifier]






![9
Python içerisinde, Random Forest benzer tekniklerden bir tanesi de, ExtraTreesClassifier
yöntemidir.Daha gelişmiş Ensemble tekniklerden biri, Stochastic Gradient Boosting
[GradientBoostingClassifier]](https://image.slidesharecdn.com/randomforestparameters-180720101720/85/Python-Rastgele-Orman-Random-Forest-Parametreleri-9-320.jpg)
![10
Örnek Kod:
import pandas as pd
df = pd.read_csv('….')
X=df []
Y=df []
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=500, max_depth=10,
random_state=1)
random_forest.fit(X_train, y_train)
output:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=10, max_features='auto', max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=500, n_jobs=1, oob_score=False, random_state=1,
verbose=0, warm_start=False)
from sklearn.metrics import accuracy_score
y_predict = random_forest.predict(X_test)
accuracy_score(y_test, y_predict)
from sklearn.metrics import confusion_matrix
pd.DataFrame(confusion_matrix(y_test, y_predict),columns=['X', 'Y'],index=[‘GERCEK
X', 'GERCEK Y' )](https://image.slidesharecdn.com/randomforestparameters-180720101720/85/Python-Rastgele-Orman-Random-Forest-Parametreleri-10-320.jpg)