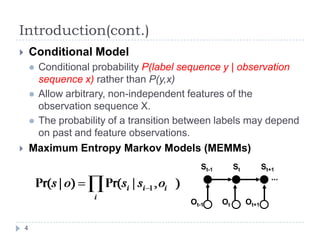
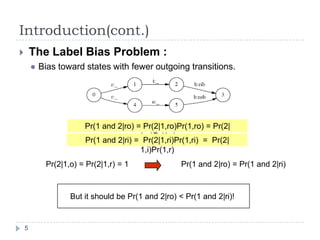
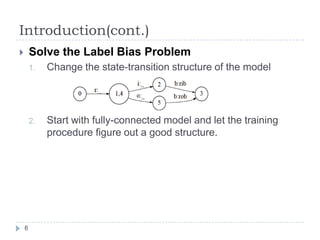
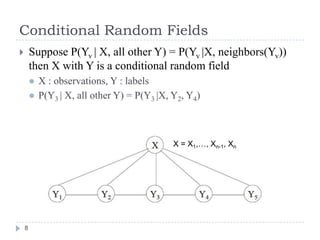
Conditional random fields (CRFs) are probabilistic models for segmenting and labeling sequence data. CRFs address limitations of previous models like hidden Markov models (HMMs) and maximum entropy Markov models (MEMMs). CRFs allow incorporation of arbitrary, overlapping features of the observation sequence and label dependencies. Parameters are estimated to maximize the conditional log-likelihood using iterative scaling or tracking partial feature expectations. Experiments show CRFs outperform HMMs and MEMMs on synthetic and real-world tasks by addressing label bias problems and modeling dependencies beyond the previous label.









![Conditional Random Fields9Conditional Distribution[2]tj(yi−1, yi, x, i) is a transition feature function of the entire observation sequence and the labels at positions i and i−1 in the label sequence](https://image.slidesharecdn.com/conditionalrandomfields-091116015256-phpapp02/85/Conditional-Random-Fields-14-320.jpg)

![λkand μkare parameters to be estimated from training data.Conditional Distribution[1]x : data sequence](https://image.slidesharecdn.com/conditionalrandomfields-091116015256-phpapp02/85/Conditional-Random-Fields-16-320.jpg)