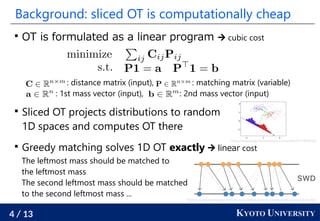
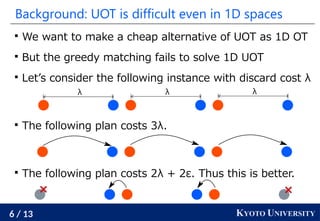
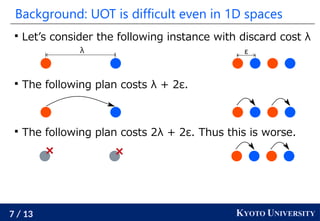
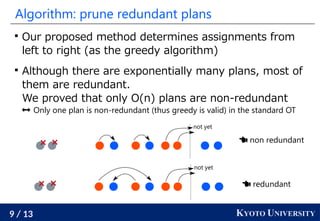
This document presents research by Ryoma Sato of Kyoto University on fast unbalanced optimal transport (UOT) algorithms that efficiently handle the transport of distribution masses while being robust to outliers. It discusses the challenges of UOT in one-dimensional spaces and introduces a new algorithm that reduces the computational complexity to O(n log² n), which is significantly faster than traditional methods. The proposed method extends to tree spaces and demonstrates empirical effectiveness, computing UOT with one million masses in under one second.
















![[DL輪読会]“Highly accurate protein structure prediction with AlphaFold”](https://cdn.slidesharecdn.com/ss_thumbnails/210910dlver11-210910034033-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20180528-180528084124-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)



























![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)













