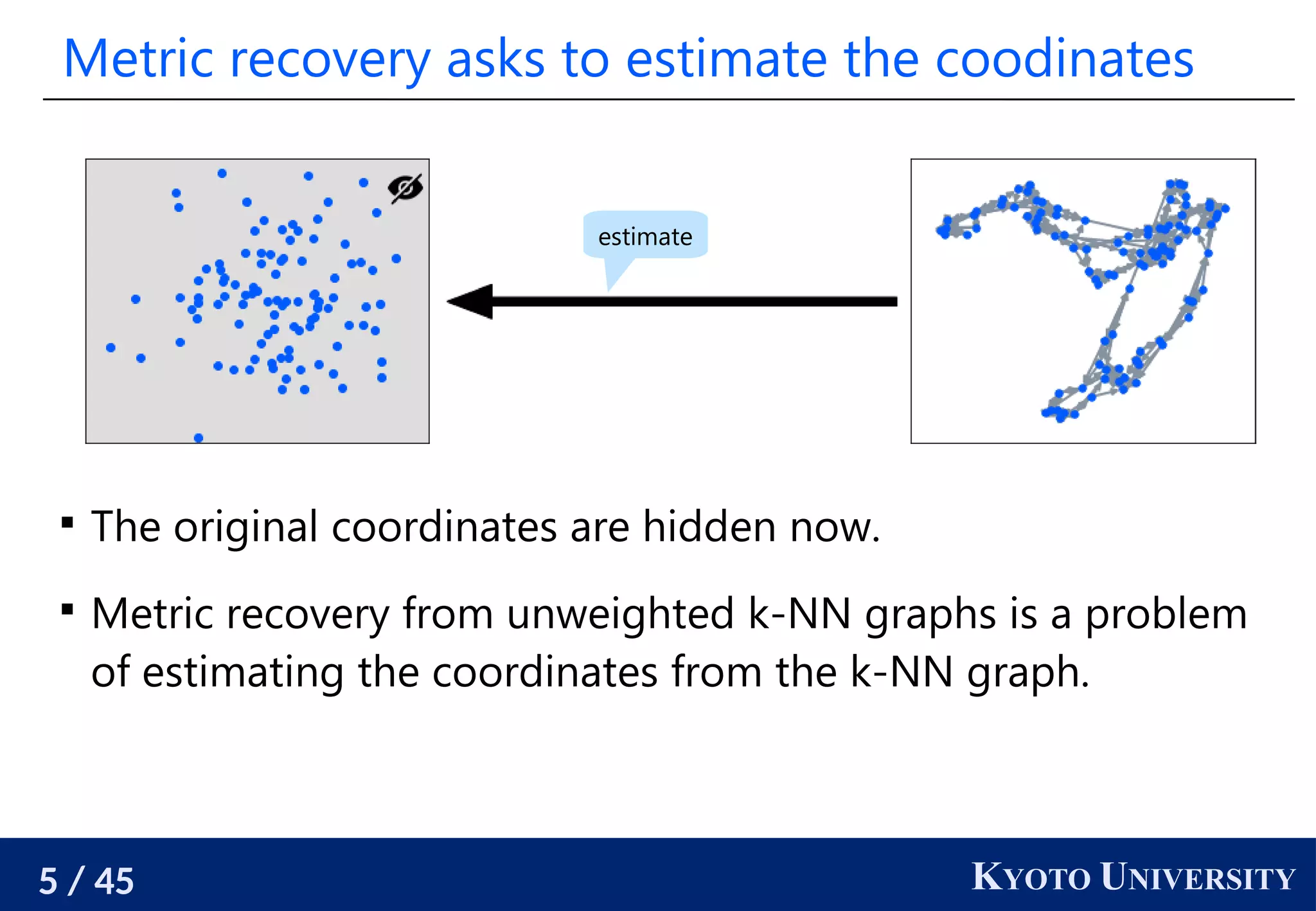
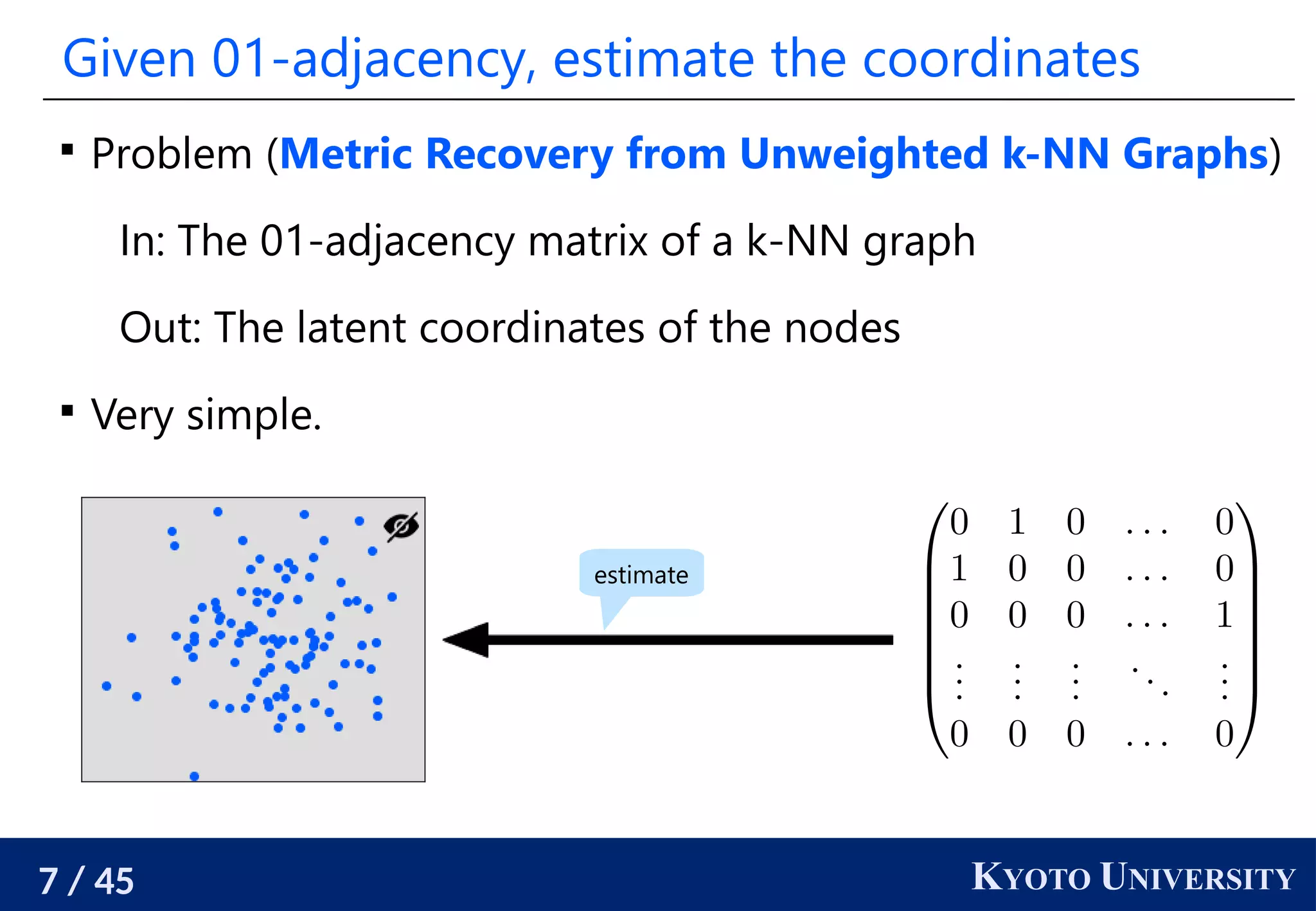
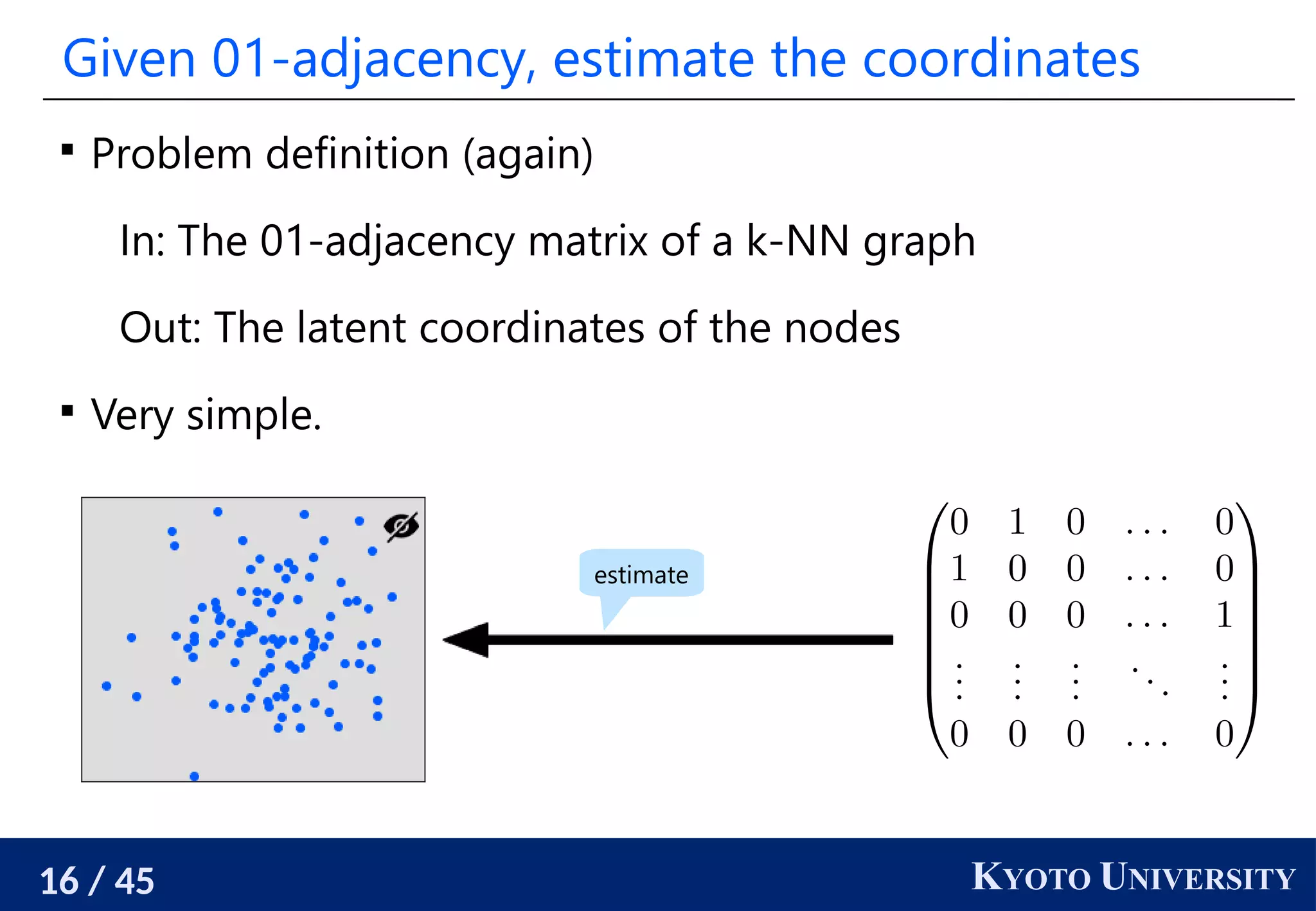
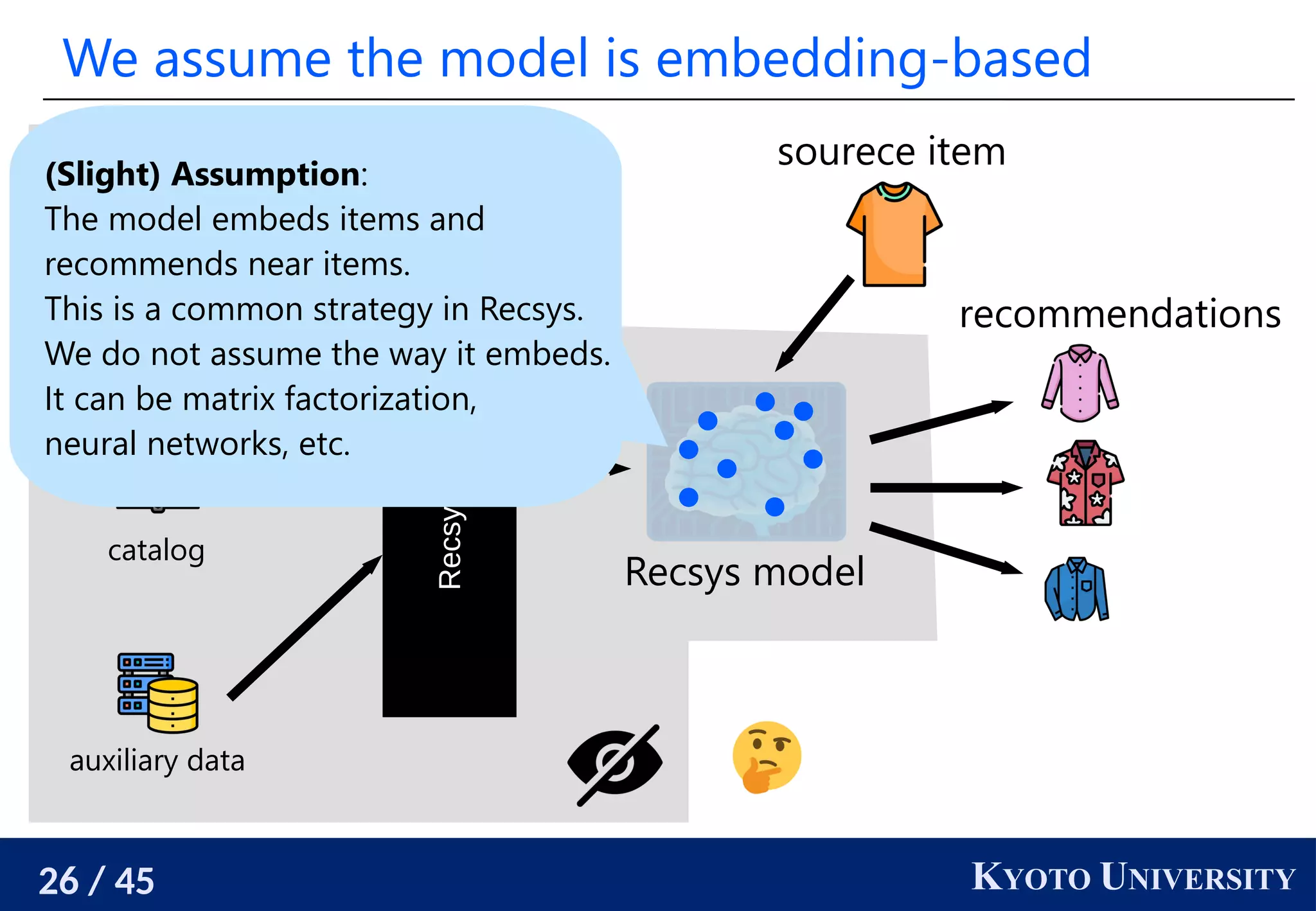
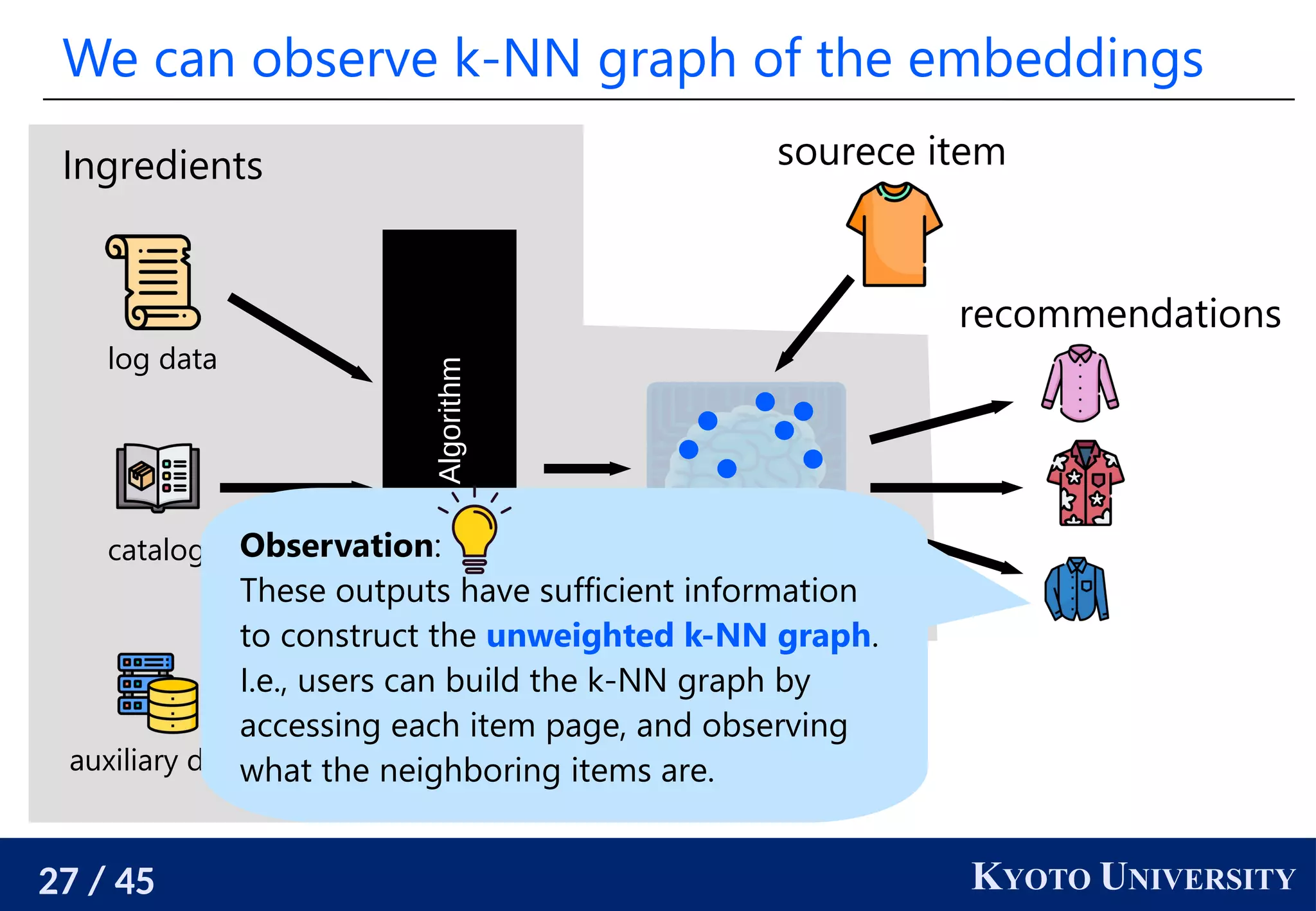
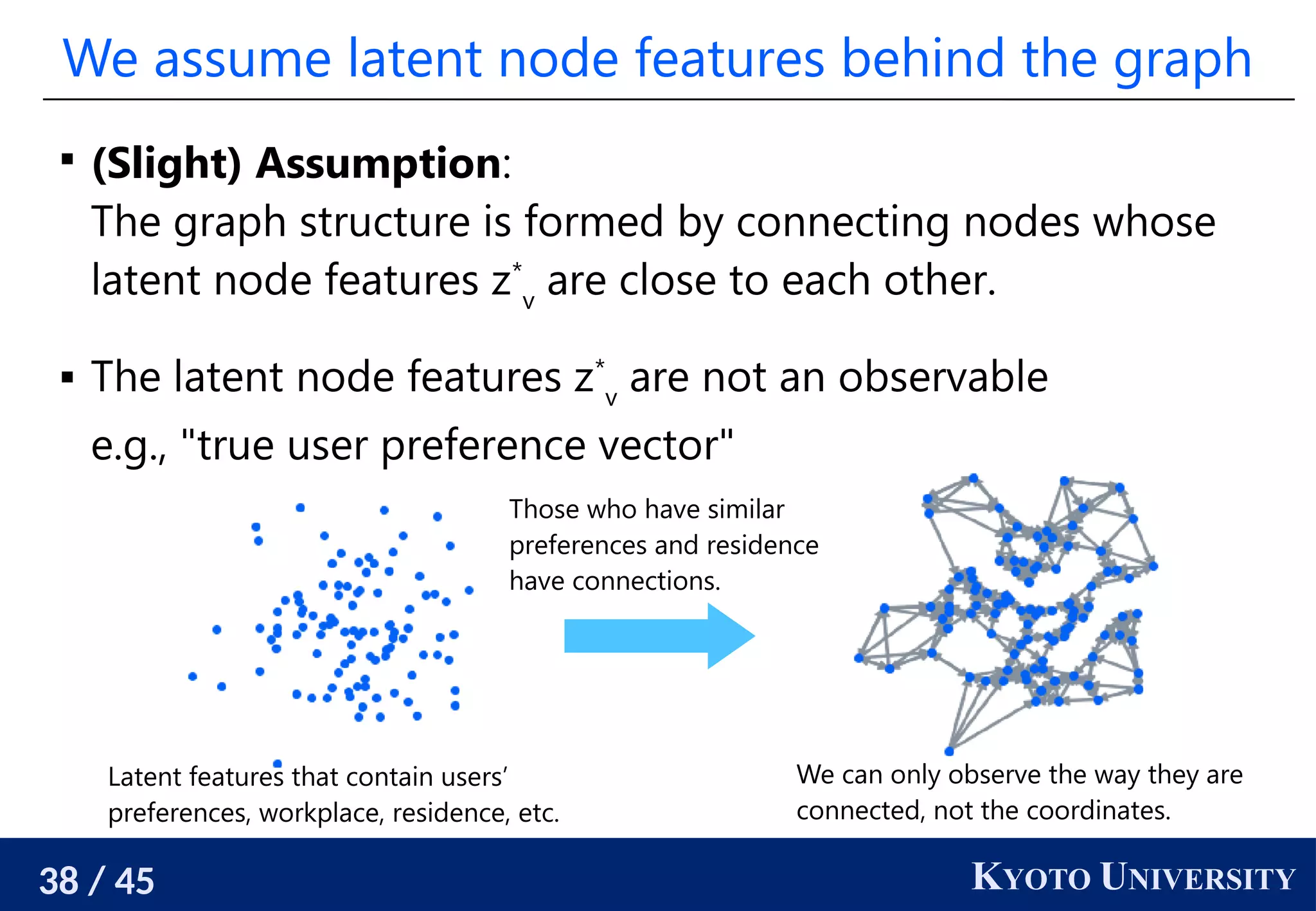
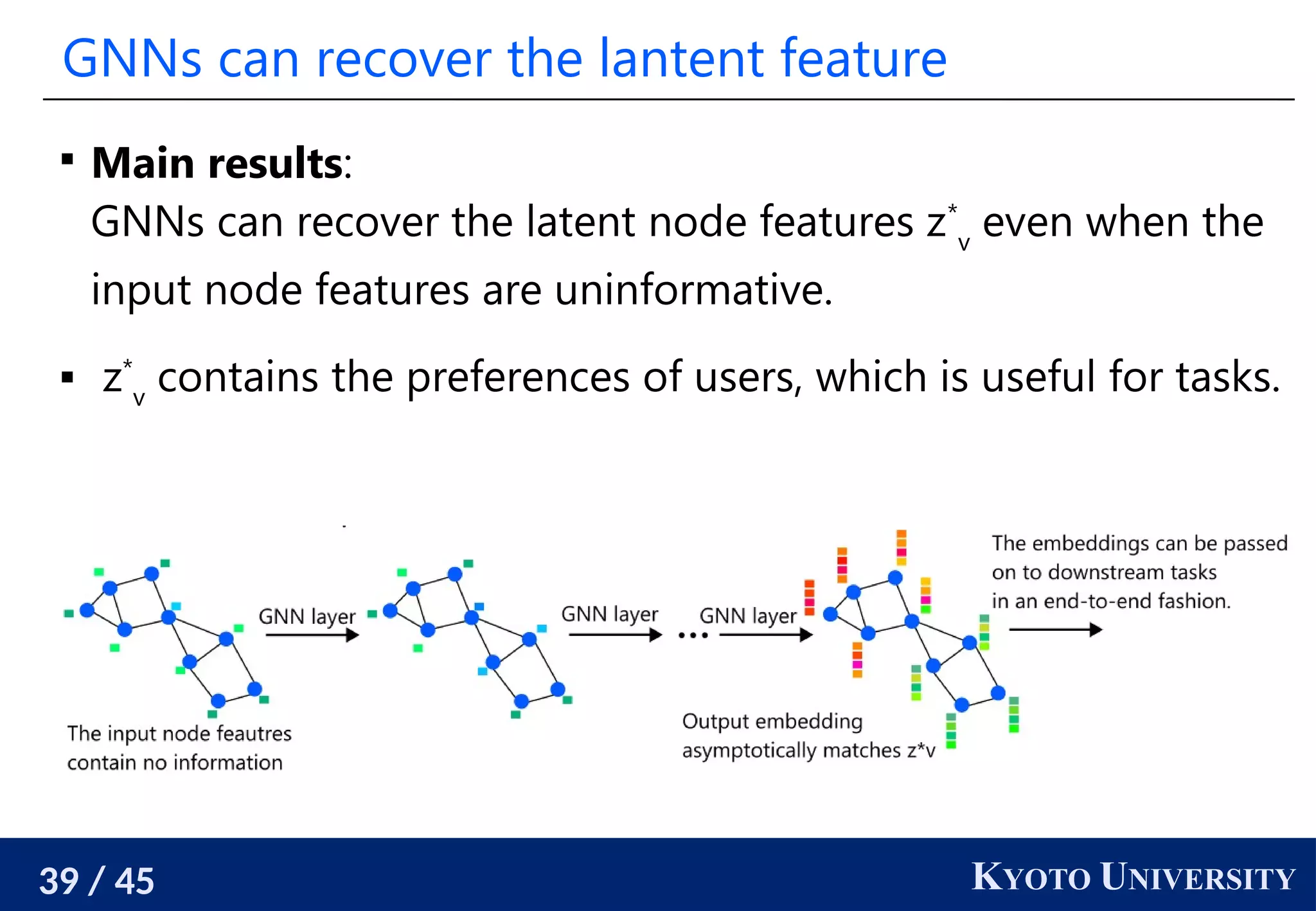
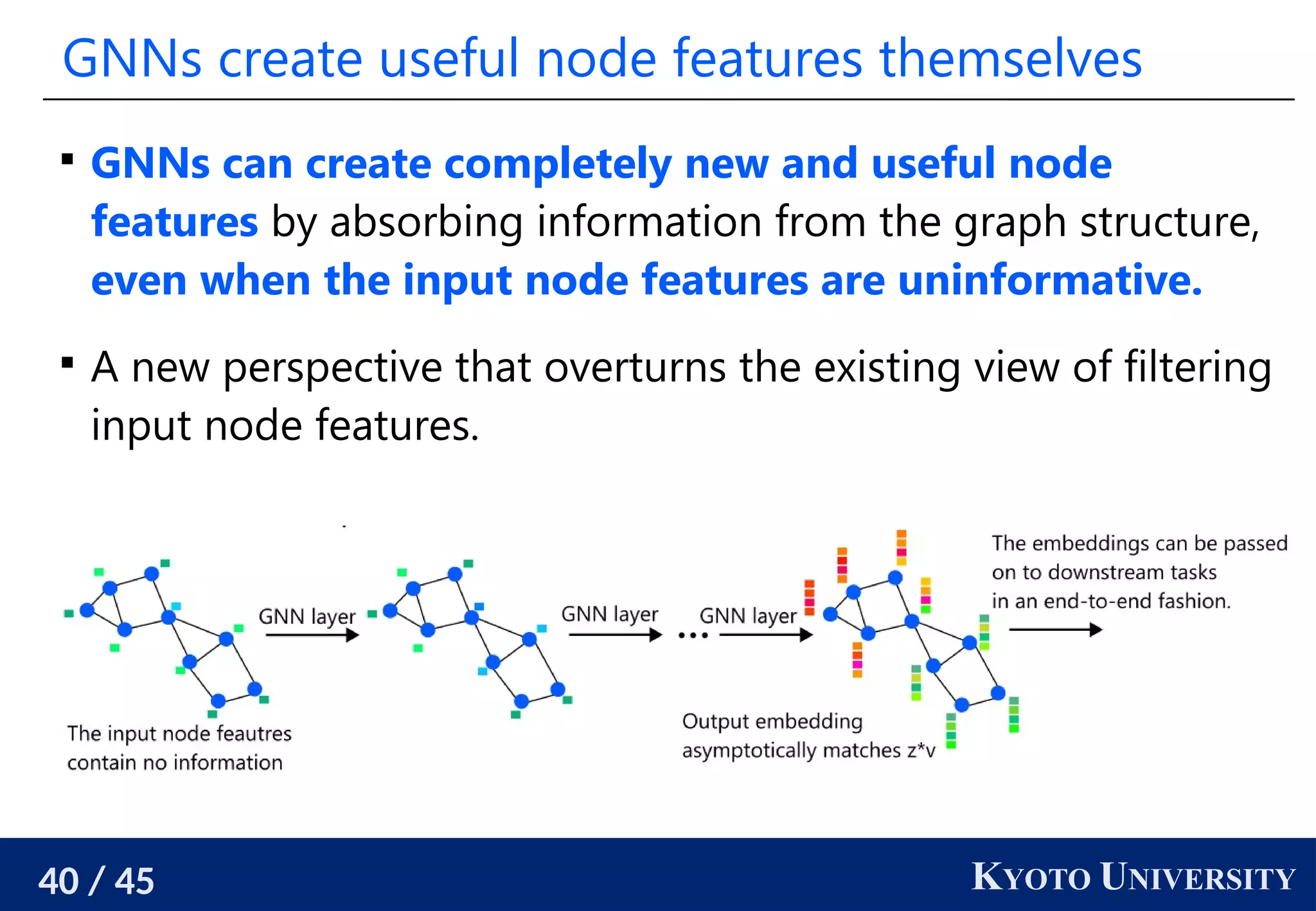
The document discusses metric recovery from unweighted k-nearest neighbor (k-nn) graphs, highlighting its applications in user-side recommender systems and graph neural networks (GNNs). It outlines the challenges in estimating the latent coordinates from the k-nn graphs and presents a systematic approach to address these difficulties, including the importance of edge lengths and densities. The findings suggest that GNNs can successfully recover hidden features from graph structures, even with uninformative input features.












![17 / 45 KYOTO UNIVERSITY
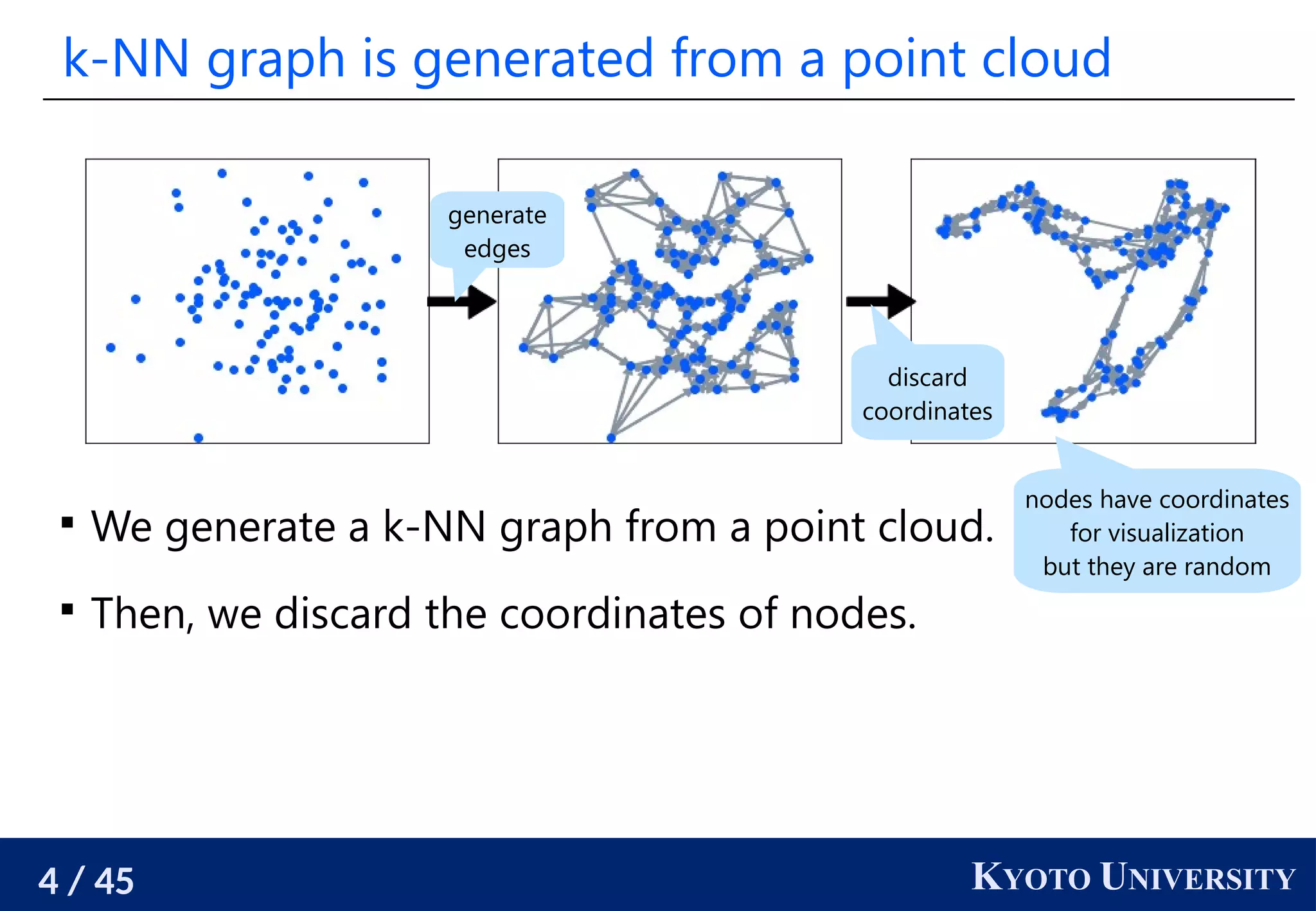
Procedure to estimate the coordinates
1. Compute the stationary distribution of random walks.
2. Estimate the density around each node.
3. Estimate the edge lengths using the estimated densities.
4. Compute the shortest path distances using the estimated
edge lengths and compute the distance matrix.
5. Estimate the coordinates from the distance matrix
by, e.g., multidimentional scaling.
This is a consistent estimator [Hashimoto+ AISTATS 2015].
Tatsunori Hashimoto, Yi Sun, Tommi Jaakkola. Metric recovery from directed unweighted graphs. AISTATS 2015.
(up to rigid transform)](https://image.slidesharecdn.com/slides-230601083149-2d57737b/75/Metric-Recovery-from-Unweighted-k-NN-Graphs-17-2048.jpg)



![21 / 45 KYOTO UNIVERSITY
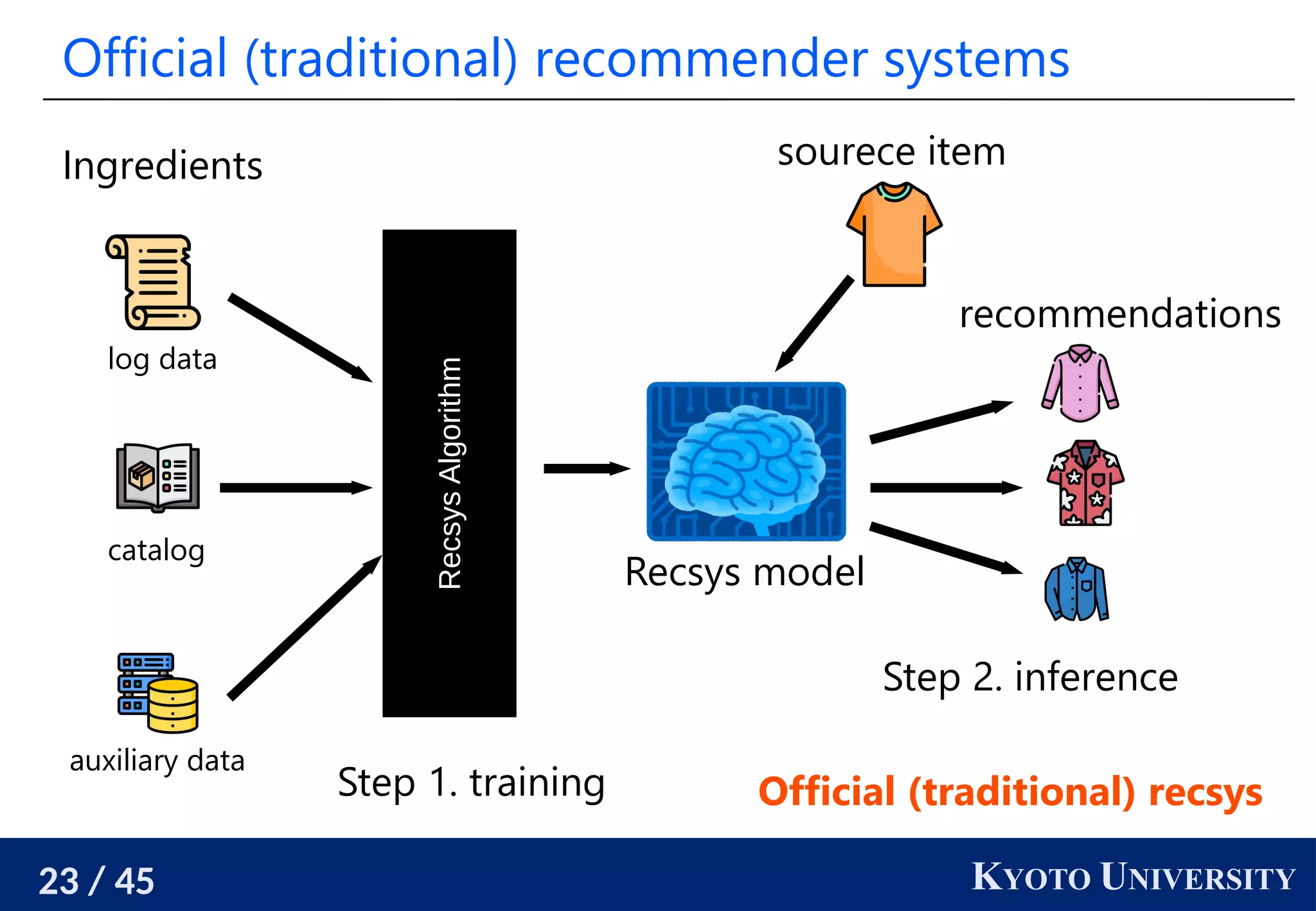
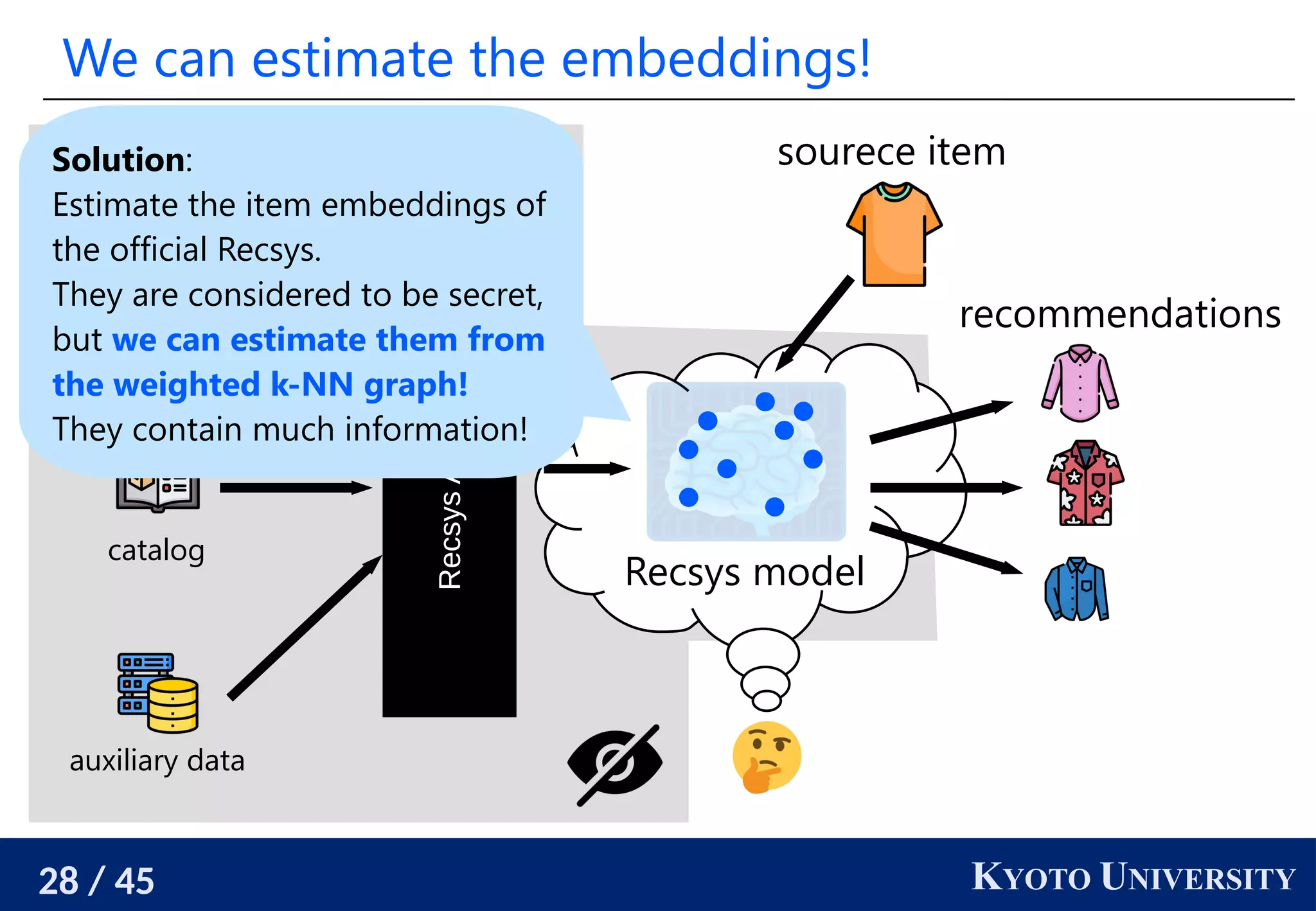
User-side recsys realizes user’s desiderata
Problem: We are unsatisfactory with the official recommender
system.
It provides monotone recommendations.
We need serendipity.
It provides recommendations biased towards specific
companies or countries.
User-side recommender systems [Sato 2022] enable users
to build their own recommender systems that satisfy their
desiderata even when the official one does not support them.
Ryoma Sato. Private Recommender Systems: How Can Users Build Their Own Fair Recommender Systems without
Log Data? SDM 2022.](https://image.slidesharecdn.com/slides-230601083149-2d57737b/75/Metric-Recovery-from-Unweighted-k-NN-Graphs-21-2048.jpg)
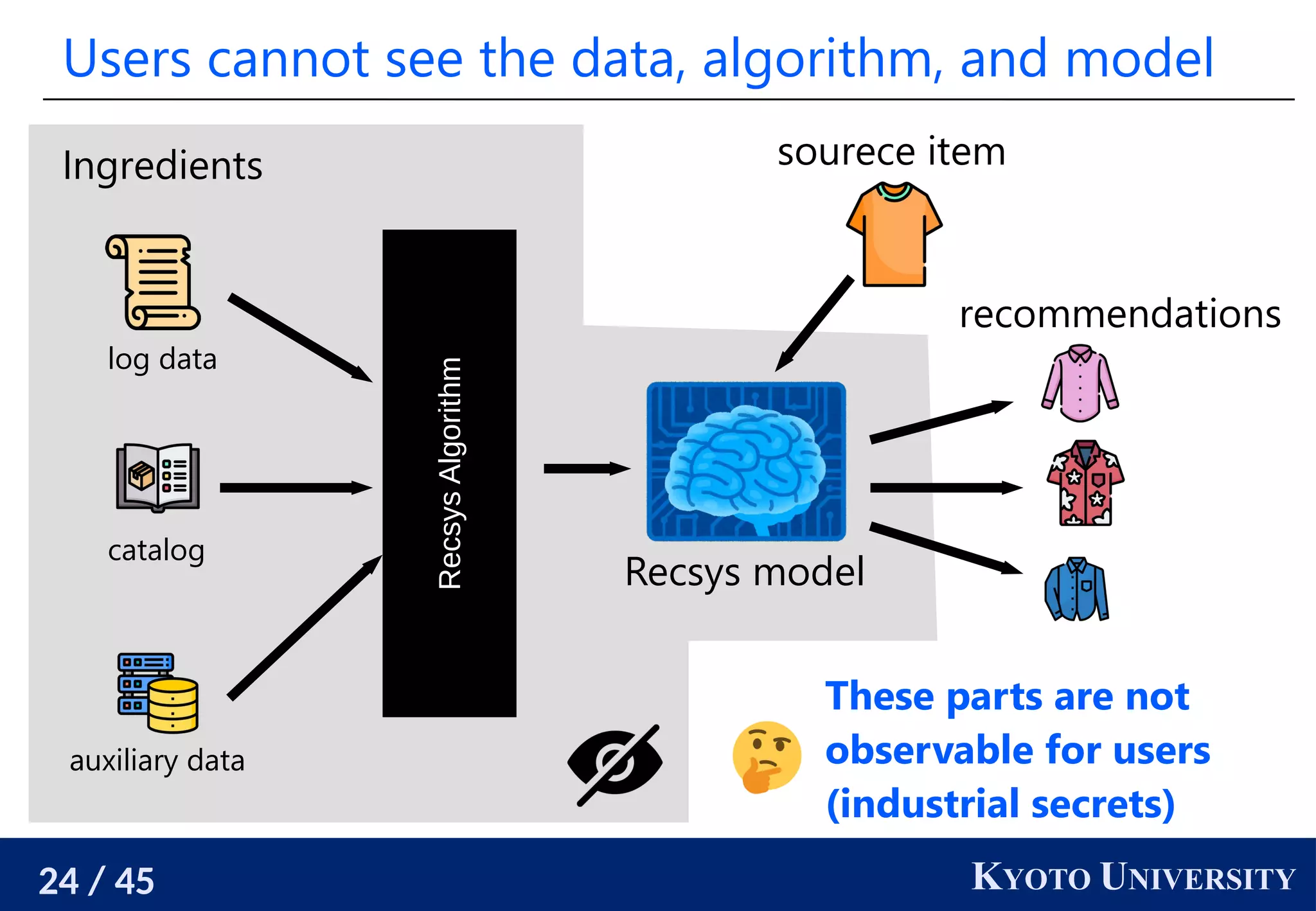
![22 / 45 KYOTO UNIVERSITY
We need powerful and principled user-side Recsys
[Sato 2022]’s user-side recommender system is realized in an
ad-hoc manner, and the performance is not so high.
We need a way to build user-side recommender systems in a
systematic manner and a more powerful one.
Hopefully one that is as strong as the official one.
Ryoma Sato. Private Recommender Systems: How Can Users Build Their Own Fair Recommender Systems without
Log Data? SDM 2022.](https://image.slidesharecdn.com/slides-230601083149-2d57737b/75/Metric-Recovery-from-Unweighted-k-NN-Graphs-22-2048.jpg)

















![[IRTalks@The University of Glasgow] A Topology-aware Analysis of Graph Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/irtalksdanielemalitesta-240213122149-51207659-thumbnail.jpg?width=640&height=640&fit=bounds)















![250908_JH_Labmeeting[GRAPH NEURAL NETWORKS GONE HOGWILD].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250908jhlabmeetingenergygnns-250909013819-a4f9d5fb-thumbnail.jpg?width=640&height=640&fit=bounds)








































