Download to read offline






![8
contains no code points in the reserved range U+D800–U+DFFF,[clarification needed] a UCS-2 text is
valid UTF-16 text.
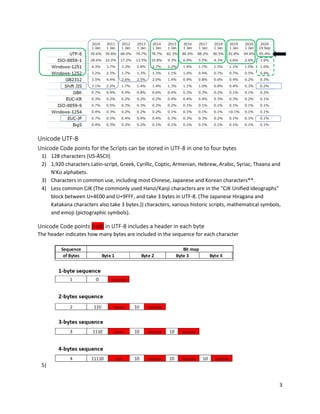
UTF-8 is defined to encode code points in one to four bytes, depending on the number of significant bits
in the numerical value of the code point. The following table shows the structure of the encoding. We
will focus portability aspects between UTF-8 and UTF-16 (used by Teradata and some other large
databases) and start with 1-byte, 2-bytes, and 3-bytes characters in this example with three samples
characters:
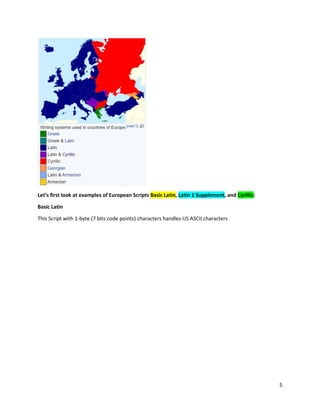
We will tokenize the above yellow code points in the following examples.
Examples of Tokenization of Unicode
Token Fabric generated from input of Unicode Code Points
A fabric of intermediate tokens is created to increase the entropy of each final token. The blue tokens
represent temporary results and the final token values are green:](https://image.slidesharecdn.com/dataencryptionandtokenizationforinternationalunicode-210429102332/85/Data-encryption-and-tokenization-for-international-unicode-8-320.jpg)



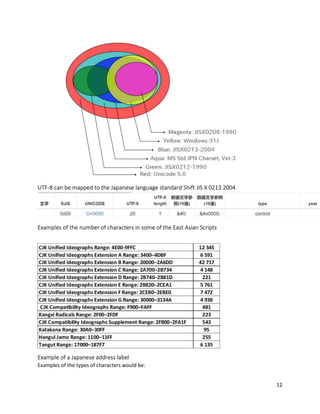





The document discusses the Unicode character encoding standard, detailing its implementation, character encodings such as UTF-8 and UTF-16, and the importance of data encryption and tokenization for international Unicode content. It emphasizes the usage of UTF-8 for web applications and outlines the structure of encoding and examples of various character scripts, especially focusing on East Asian languages like Japanese. Additionally, it addresses practical considerations such as data security measures, including tokenization and encoding preservation.























































































