Downloaded 43 times














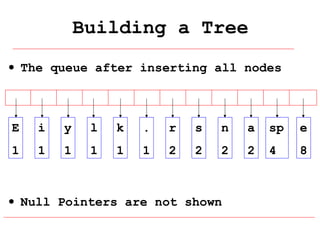

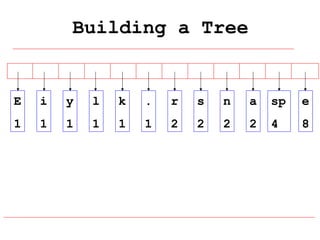
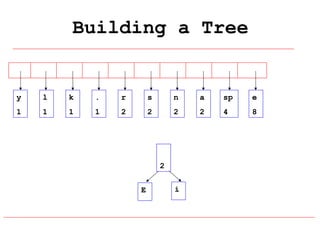
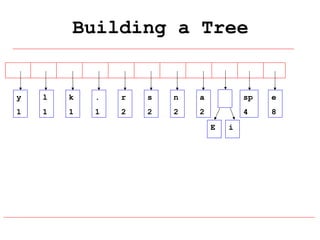
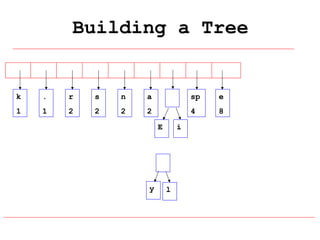
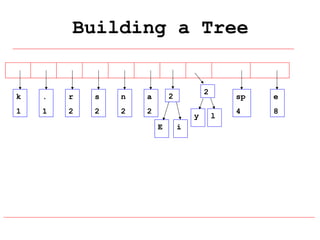
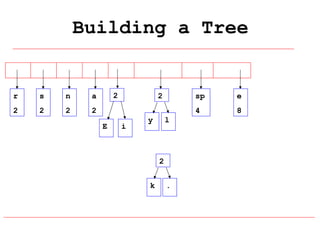
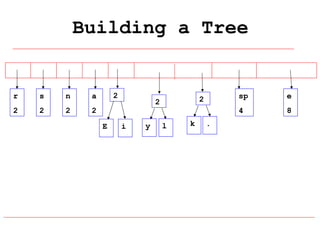
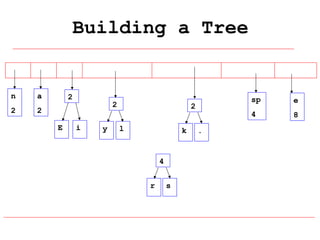
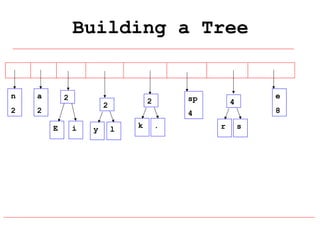
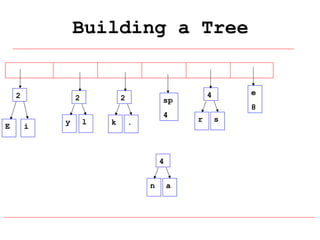
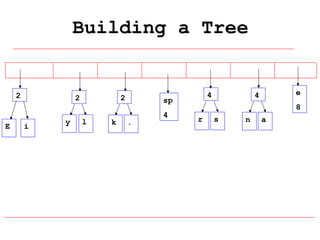
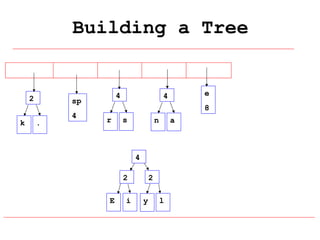
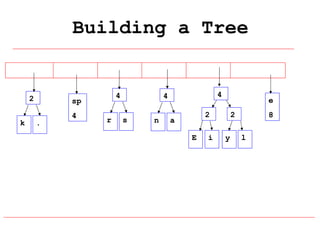
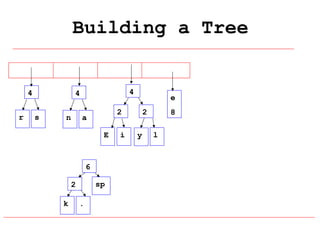
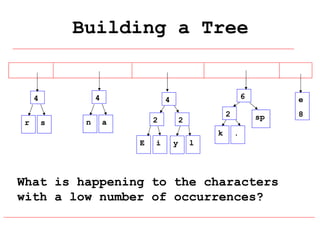
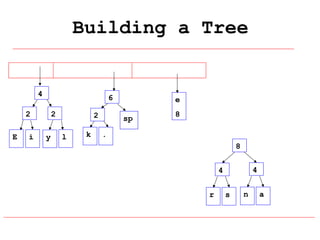
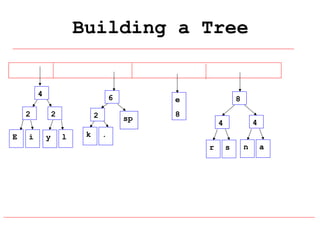
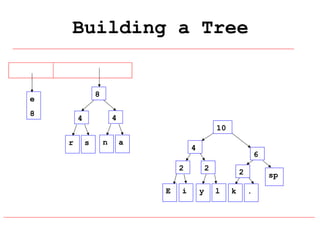
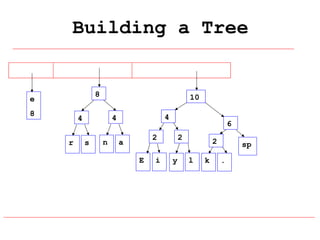
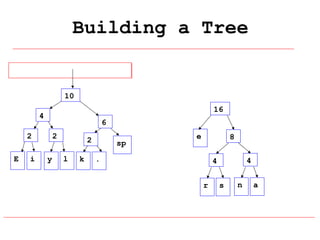
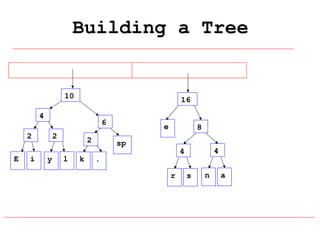
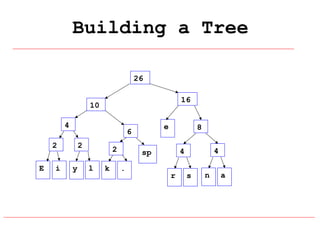
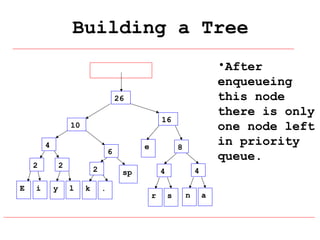
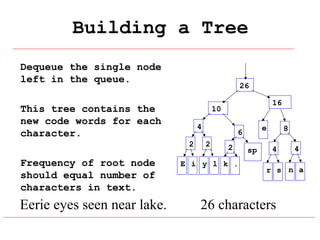
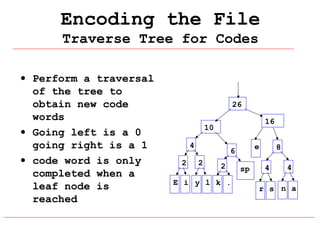
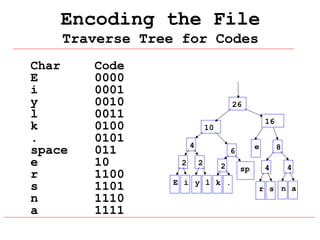



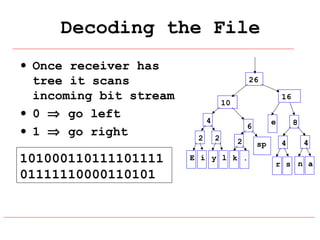




Huffman coding is a data compression technique that uses variable-length code words to encode characters based on their frequency of occurrence. It involves building a Huffman tree from character frequencies, assigning code words by traversing the tree, and encoding the text. This results in more common characters having shorter code words, reducing the number of bits needed and allowing for smaller file sizes compared to fixed-length encodings like ASCII.
































































