Downloaded 44 times







![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
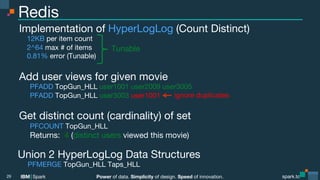
What about Average?
Average
(
a[3, 1]
((3 + 5) + (5 + 7))
20
b[5, 1] == ----------------------- == --- == 5
b[5, 1]
((1 + 2) + 1)
4
c[7, 1]
)
8
value
count
Pairwise Average
(3 + 5) (5 + 7) 8 12 20
------- + ------- == --- + --- == --- == 10 != 5
2
2
2 2
2
Divide, Add, Divide:
Not
Composable
Single Divide:
Composable!
AVG(3, 5, 5, 7) == 5](https://image.slidesharecdn.com/galvanizesparkmeetupjan282016-160130022054/85/Advanced-Apache-Spark-Meetup-Approximations-and-Probabilistic-Data-Structures-Jan-28-2016-Galvanize-8-320.jpg)

















![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
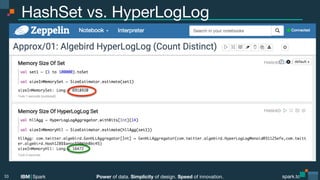
Spark Approximations
Spark Core
RDD.count*Approx()
Spark SQL
PartialResult
HyperLogLogPlus
approxCountDistinct(column)
Spark ML
Stratified sampling
PairRDD.sampleByKey(fractions: Double[ ])
DIMSUM sampling
Probabilistic sampling reduces amount of comparison shuffle
RowMatrix.columnSimilarities(threshold)
Spark Streaming
A/B testing
StreamingTest.setTestMethod(“welch”).registerStream(dstream)
30](https://image.slidesharecdn.com/galvanizesparkmeetupjan282016-160130022054/85/Advanced-Apache-Spark-Meetup-Approximations-and-Probabilistic-Data-Structures-Jan-28-2016-Galvanize-30-320.jpg)








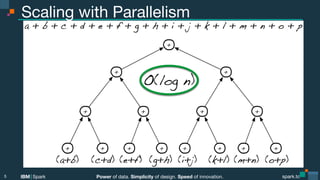
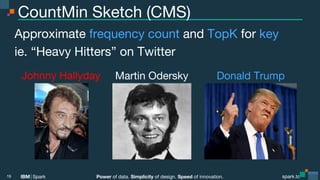
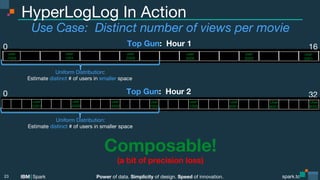
The document presents a detailed overview of advanced concepts and techniques related to Apache Spark, focusing on the power of data, simplicity of design, and speed of innovation. It covers various probabilistic data structures, approximate algorithms, and their applications, including Bloom filters, Count-Min Sketch, HyperLogLog, and Locality Sensitive Hashing, emphasizing when to approximate in data processing tasks. The presentation also highlights the mission of the Advanced Apache Spark Meetup, which has fostered significant community engagement and interest in exploring Spark and related technologies.












































![[系列活動] 資料探勘速遊](https://cdn.slidesharecdn.com/ss_thumbnails/0114ycchendmquicktour-170110050658-thumbnail.jpg?width=640&height=640&fit=bounds)









































