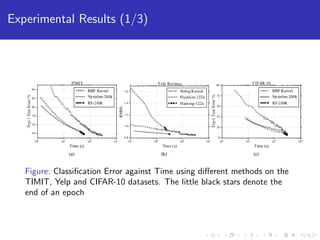
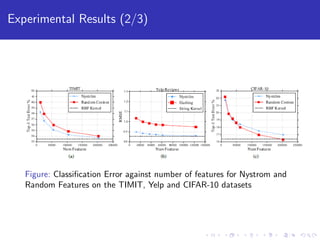
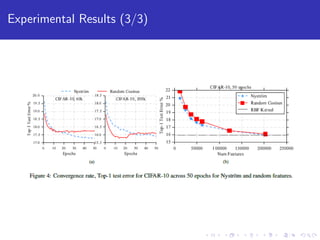
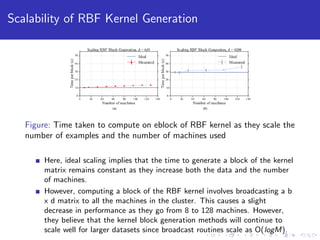
This paper explores using block coordinate descent to scale kernel learning methods to large datasets. It compares exact kernel methods to two approximation techniques, Nystrom and random Fourier features, on speech, text, and image datasets. Experimental results show that Nystrom generally achieves better accuracy than random features but requires more iterations. The paper also analyzes the performance and scalability of computing kernel blocks in a distributed setting.





































![[딥논읽] Meta-Transfer Learning for Zero-Shot Super-Resolution paper review](https://cdn.slidesharecdn.com/ss_thumbnails/210228mzsrv1-210304064113-thumbnail.jpg?width=640&height=640&fit=bounds)




![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt1580-thumbnail.jpg?width=640&height=640&fit=bounds)










































