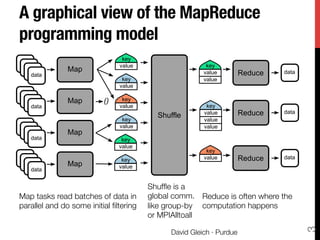
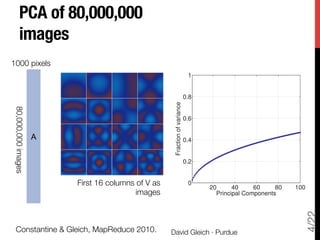
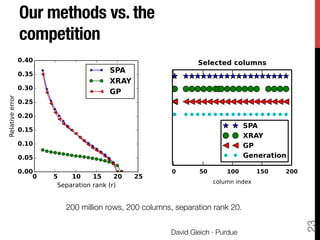
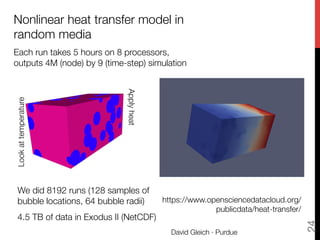
The document discusses big data matrix factorizations and overlapping community detection in graphs, focusing on various algorithms and methods for high-performance matrix computations. It emphasizes practical applications such as regression analysis on large image datasets, employing techniques like MapReduce for efficient processing. Additionally, the document covers advancements in non-negative matrix factorization and community detection using personalized PageRank algorithms.



![Models and algorithms for high performance !
matrix and network computations
David Gleich · Purdue
6
1
error
1
std
0
2
(b) Std, s = 0.39 cm
10
error
0
0
10
std
0
20
(d) Std, s = 1.95 cm
model compared to the prediction standard de-
bble locations at the final time for two values of
= 1.95 cm. (Colors are visible in the electronic
approximately twenty minutes to construct using
s.
ta involved a few pre- and post-processing steps:
m Aria, globally transpose the data, compute the
nd errors. The preprocessing steps took approx-
recise timing information, but we do not report
Tensor eigenvalues"
and a power method
FIGURE 6 – Previous work
from the PI tackled net-
work alignment with ma-
trix methods for edge
overlap:
i
j j0
i0
OverlapOverlap
A L B
This proposal is for match-
ing triangles using tensor
methods:
j
i
k
j0
i0
k0
TriangleTriangle
A L B
t
r
o
s.
g
n.
o
n
s
s-
g
maximize
P
ijk Tijk xi xj xk
subject to kxk2 = 1
where ! ensures the 2-norm
[x(next)
]i = ⇢ · (
X
jk
Tijk xj xk + xi )
SSHOPM method due to "
Kolda and Mayo
Big data methods
SIMAX ‘09, SISC ‘11,MapReduce ‘11, ICASSP ’12
Network alignment
ICDM ‘09, SC ‘11, TKDE ‘13
Fast & Scalable"
Network centrality
SC ‘05, WAW ‘07, SISC ‘10, WWW ’10, …
Data clustering
WSDM ‘12, KDD ‘12, CIKM ’13 …
Ax = b
min kAx bk
Ax = x
Massive matrix "
computations
on multi-threaded
and distributed
architectures](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-6-320.jpg)








![The rest of the talk"
Full TSQR code in hadoopy
15
David Gleich · Purdue
import random, numpy, hadoopy
class SerialTSQR:
def __init__(self,blocksize,isreducer):
self.bsize=blocksize
self.data = []
if isreducer: self.__call__ = self.reducer
else: self.__call__ = self.mapper
def compress(self):
R = numpy.linalg.qr(
numpy.array(self.data),'r')
# reset data and re-initialize to R
self.data = []
for row in R:
self.data.append([float(v) for v in row])
def collect(self,key,value):
self.data.append(value)
if len(self.data)>self.bsize*len(self.data[0]):
self.compress()
def close(self):
self.compress()
for row in self.data:
key = random.randint(0,2000000000)
yield key, row
def mapper(self,key,value):
self.collect(key,value)
def reducer(self,key,values):
for value in values: self.mapper(key,value)
if __name__=='__main__':
mapper = SerialTSQR(blocksize=3,isreducer=False)
reducer = SerialTSQR(blocksize=3,isreducer=True)
hadoopy.run(mapper, reducer)](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-15-320.jpg)















![We can find communities using
Personalized PageRank (PPR)
[Andersen et al. 2006]
PPR is a Markov chain on nodes
1. with probability 𝛼, ", "
follow a random edge
2. with probability 1-𝛼, ", "
restart at a seed
aka random surfer
aka random walk with restart
unique stationary distribution
David Gleich · Purdue
33](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-33-320.jpg)

![Conductance communities
Conductance is one of the most
important community scores [Schaeffer07]
The conductance of a set of vertices is
the ratio of edges leaving to total edges:
Equivalently, it’s the probability that a
random edge leaves the set.
Small conductance ó Good community
(S) =
cut(S)
min vol(S), vol( ¯S)
(edges leaving the set)
(total edges
in the set)
David Gleich · Purdue
cut(S) = 7
vol(S) = 33
vol( ¯S) = 11
(S) = 7/11
35](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-35-320.jpg)
![Andersen-
Chung-Lang"
personalized
PageRank
community
theorem"
[Andersen et al. 2006]!
Informally
Suppose the seeds are in a set
of good conductance, then the
personalized PageRank method
will find a set with conductance
that’s nearly as good.
… also, it’s really fast.
David Gleich · Purdue
36](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-36-320.jpg)
![# G is graph as dictionary-of-sets!
alpha=0.99!
tol=1e-4!
!
x = {} # Store x, r as dictionaries!
r = {} # initialize residual!
Q = collections.deque() # initialize queue!
for s in seed: !
r(s) = 1/len(seed)!
Q.append(s)!
while len(Q) > 0:!
v = Q.popleft() # v has r[v] > tol*deg(v)!
if v not in x: x[v] = 0.!
x[v] += (1-alpha)*r[v]!
mass = alpha*r[v]/(2*len(G[v])) !
for u in G[v]: # for neighbors of u!
if u not in r: r[u] = 0.!
if r[u] < len(G[u])*tol and !
r[u] + mass >= len(G[u])*tol:!
Q.append(u) # add u to queue if large!
r[u] = r[u] + mass!
r[v] = mass*len(G[v]) !
David Gleich · Purdue
37](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-37-320.jpg)

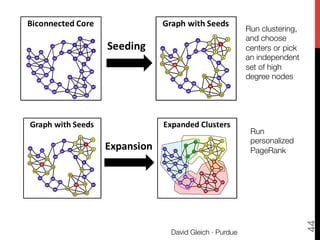
![Whang-Gleich-Dhillon,
CIKM2013 [upcoming…]
1. Extract part of the graph that might have
overlapping communities.
2. Compute a partitioning of the network into
many pieces (think sqrt(n)) using Graclus.
3. Find the center of these partitions.
4. Use PPR to grow egonets of these centers.
David Gleich · Purdue
39](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-39-320.jpg)





![Conclusion & Discussion &
PPR community detection is fast "
[Andersen et al. FOCS06]
PPR communities look real "
[Abrahao et al. KDD2012; Zhu et al. ICML2013]
Partitioning for seeding yields "
high coverage & real communities.
“Caveman” communities?!
!
!
!
David Gleich · Purdue
46
Gleich & Seshadhri
KDD2012
Whang, Gleich & Dhillon
CIKM2013
PPR Sample !
bit.ly/18khzO5!
!
Egonet seeding
bit.ly/dgleich-code!
References
Best conductance cut
at intersection of
communities?](https://image.slidesharecdn.com/practical-matrix-methods-140713200501-phpapp01/85/Big-data-matrix-factorizations-and-Overlapping-community-detection-in-graphs-46-320.jpg)



















![[Vldb 2013] skyline operator on anti correlated distributions](https://cdn.slidesharecdn.com/ss_thumbnails/vldb2013skylineoperatoronanti-correlateddistributions-160331123240-thumbnail.jpg?width=640&height=640&fit=bounds)






























































