Download to read offline



![The Bellman equation
V(s) = max [R(s,a) + γV(s`)] Where,
• State(s): current state where the agent is in the environment.
• Next State(s’): After acting(a) at state(s) the agent reaches s’.
• Value(V): Numeric representation of a state which helps the agent to find
its path. V(s) here means the value of the state s.
• R(s): reward for being in the state s.
• R(s,a): reward for being in the state and performing an action a.
4
OMega TechEd](https://image.slidesharecdn.com/5reinforcementlearning-ii-231203161050-d8a4dd7a/85/Bellman-s-equation-Reinforcement-learning-II-4-320.jpg)
![For 1st block
V(s3) = max [R(s,a) + γV(s`)], here V(s')= 0 because there is no further state
to move.
V(s3)= max[R(s,a)]=> V(s3)= 1.
5
Using the Bellman equation, we
will find value at each state of the
given environment. We will start
from the block, which is next to
the target block.
OMega TechEd](https://image.slidesharecdn.com/5reinforcementlearning-ii-231203161050-d8a4dd7a/85/Bellman-s-equation-Reinforcement-learning-II-5-320.jpg)
![For 2nd block
V(s2) = max [R(s,a) + γV(s`)],
here γ= 0.9(lets), V(s')= 1, and R(s, a)= 0, because there is no reward at this
state.
V(s2)= max[0.9(1)]=> V(s2) =0.9
6
1
OMega TechEd](https://image.slidesharecdn.com/5reinforcementlearning-ii-231203161050-d8a4dd7a/85/Bellman-s-equation-Reinforcement-learning-II-6-320.jpg)
![For 3rd block
V(s1) = max [R(s,a) + γV(s`)],
here γ= 0.9(lets), V(s')= 0.9, and R(s, a)= 0, because there is no reward at this
state also.
V(s1)= max[0.9(0.9)]=> V(s1) =0.81
7
1
0.9
OMega TechEd](https://image.slidesharecdn.com/5reinforcementlearning-ii-231203161050-d8a4dd7a/85/Bellman-s-equation-Reinforcement-learning-II-7-320.jpg)
![For 4th block
V(s5) = max [R(s,a) + γV(s`)],
here γ= 0.9(lets), V(s')= 0.81, and R(s, a)= 0, because there is no reward at this
state also.
V(s5)= max[0.9(0.81)]=> V(s5) =0.73
8
1
0.9
0.81
OMega TechEd](https://image.slidesharecdn.com/5reinforcementlearning-ii-231203161050-d8a4dd7a/85/Bellman-s-equation-Reinforcement-learning-II-8-320.jpg)
![For 5th block
V(s9) = max [R(s,a) + γV(s`)],
here γ= 0.9(lets), V(s')= 0.73, and R(s, a)= 0, because there is no reward at this
state also.
V(s9)= max[0.9(0.73)]=> V(s4) =0.66
9
1
0.9
0.81
0.73
OMega TechEd](https://image.slidesharecdn.com/5reinforcementlearning-ii-231203161050-d8a4dd7a/85/Bellman-s-equation-Reinforcement-learning-II-9-320.jpg)
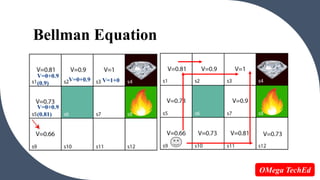


The Bellman equation is used to calculate the value of states in reinforcement learning and dynamic programming. It defines the value of a state based on the expected rewards from being in that state plus the discounted value of the next state. The document provides an example of using the Bellman equation to calculate the value of different states in an environment by starting from the final state and working backwards. Key elements of the Bellman equation include the action, next state, reward, and discount factor for weighing future rewards.























































































