Download to read offline



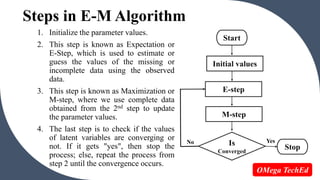




The EM algorithm is an iterative method used to find maximum likelihood estimates of parameters in statistical models where the data contains missing values or latent variables. It consists of an expectation step (E-step) where the missing data is estimated given the observed data and current estimates of the parameters, and a maximization step (M-step) where the parameters are estimated by maximizing the log-likelihood function, found using the estimates of missing data from the E-step. The algorithm repeats these two steps until the parameter estimates converge. The EM algorithm is commonly used for unsupervised learning techniques like clustering and can be applied to problems in computer vision, natural language processing, and healthcare. However, it converges slowly and may only find local optim























































































