



















































![Reinforcement Learning Algorithms
Value-Based:
In a value-based Reinforcement Learning method, you should try to
maximize a value function V(s). In this method, the agent is
expecting a long-term return of the current states under policy π.
Policy-based:
In a policy-based RL method, you try to come up with such a policy
that the action performed in every state helps you to gain maximum
reward in the future.
Two types of policy-based methods are:
Deterministic: For any state, the same action is produced by the
policy π.
Stochastic: Every action has a certain probability, which is
determined by the following equation.Stochastic Policy:
n{as) = PA, = aS, =S]](https://image.slidesharecdn.com/mlbyrj-200914044749/85/Machine-Learning-by-Rj-52-320.jpg)













































![ Remove outliers: if the number of records which are outliers is
not many, a simple approach may be to remove them.
Imputation : one other way is to impute (assign) the value with
mean or median or mode.The value of the most simmiler data
element may also be used for imputation.
Capping :For the values that lie outside the 1.5[x] IQR
( interquartile range) limits, we can cap them by replacing those
observations below the lower limit value of 5th percentile and those
that lie above the upper limit, with the value of 95th percentile.](https://image.slidesharecdn.com/mlbyrj-200914044749/85/Machine-Learning-by-Rj-98-320.jpg)

























![>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]](https://image.slidesharecdn.com/mlbyrj-200914044749/85/Machine-Learning-by-Rj-126-320.jpg)






![>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
. print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]](https://image.slidesharecdn.com/mlbyrj-200914044749/85/Machine-Learning-by-Rj-133-320.jpg)


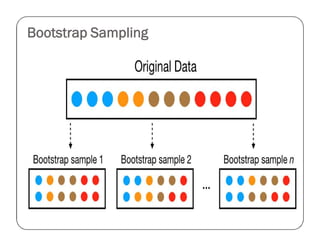

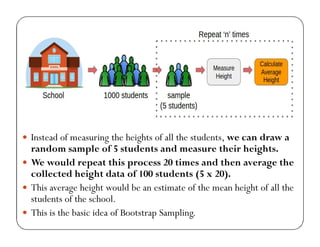
![Code for bootstrap sampling
# scikit-learn bootstrap
from sklearn.utils import resample
# data sample
data = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
# prepare bootstrap sample
boot = resample(data, replace=True, n_samples=4, random_state=1)
print('Bootstrap Sample: %s' % boot)
# out of bag observations
oob = [x for x in data if x not in boot]
print('OOB Sample: %s' % oob)
Output:
Bootstrap Sample: [0.6, 0.4, 0.5, 0.1]
OOB Sample: [0.2, 0.3]](https://image.slidesharecdn.com/mlbyrj-200914044749/85/Machine-Learning-by-Rj-139-320.jpg)






















This document provides an overview of machine learning presented by Mr. Raviraj Solanki. It discusses topics like introduction to machine learning, model preparation, modelling and evaluation. It defines key concepts like algorithms, models, predictor variables, response variables, training data and testing data. It also explains the differences between human learning and machine learning, types of machine learning including supervised learning and unsupervised learning. Supervised learning is further divided into classification and regression problems. Popular algorithms for supervised learning like random forest, decision trees, logistic regression, support vector machines, linear regression, regression trees and more are also mentioned.























































































