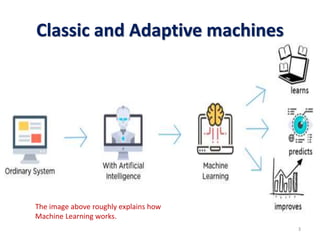
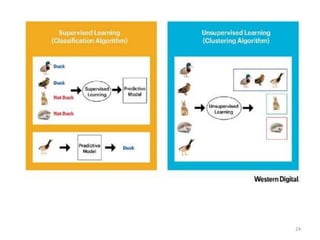
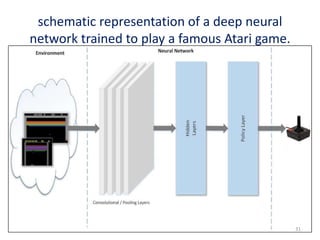
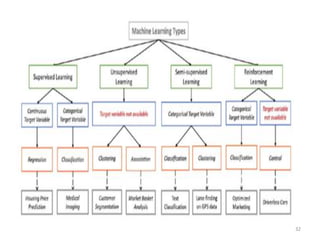
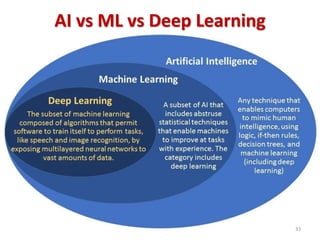
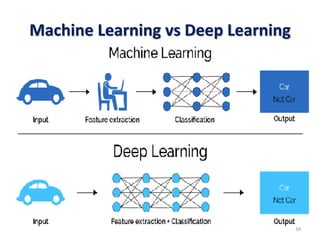
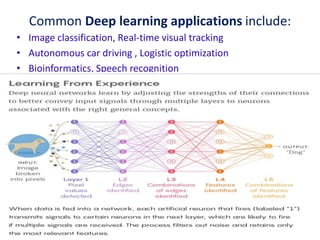
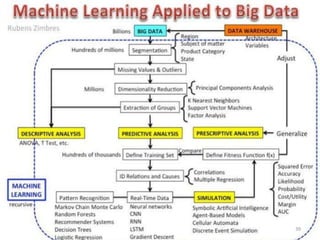
Machine learning, deep learning, and artificial intelligence are summarized. Machine learning involves using algorithms to learn from data and make predictions without being explicitly programmed. Deep learning uses neural networks with many layers to learn representations of data with multiple levels of abstraction. Artificial intelligence is the broader field of building intelligent machines that can think and act like humans. Supervised, unsupervised, semi-supervised and reinforcement learning techniques are described along with common applications such as classification, clustering, recommendation systems, and game playing.

























































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)





