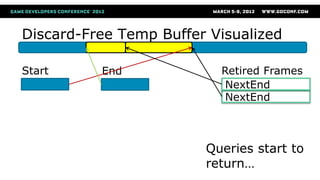
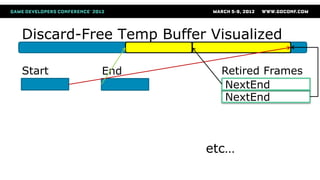
The document discusses efficient buffer management techniques for GPU programming, emphasizing CPU-GPU synchronization points and their negative impact on performance. It presents various buffer types, their usage patterns, and effective strategies to minimize API calls, reduce synchronization issues, and enhance overall performance in Direct3D 11. Key recommendations include using dynamic buffers, grouping constant buffers by update frequency, and leveraging the D3D11 debug runtime for performance investigation.