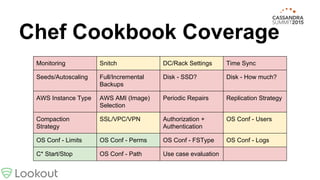
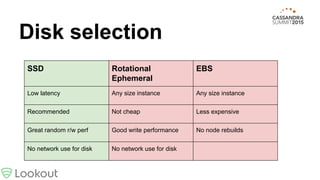
This document provides best practices for deploying Cassandra from tarball to production, covering topics like monitoring, configuration, backups, hardware selection, and more. It recommends using a Chef cookbook to automate the installation and configuration of Cassandra for consistency. While the cookbook covers many areas, there are additional steps discussed like setting the right snitch, adding racks, time synchronization, repair scheduling, authentication, and log consolidation.














![I don’t have time for this
Clusters must have synchronized time
You will get lots of drift with: [0-3].amazon.pool.
ntp.org
Community cookbook doesn’t cover anything
here](https://image.slidesharecdn.com/cassandra-fromtarballtoproduction4-150929203029-lva1-app6892/85/Cassandra-from-tarball-to-production-16-320.jpg)





































![[AWSKRUG&JAWS-UG Meetup #1] 70% Cost Reduction with On-demand resizing](https://cdn.slidesharecdn.com/ss_thumbnails/awsjawsondemandresizing-160526114219-thumbnail.jpg?width=640&height=640&fit=bounds)





















































