Download as PDF, PPTX




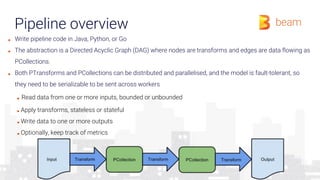



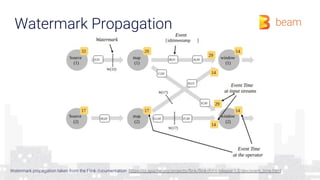








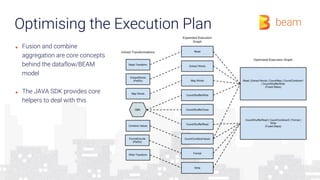


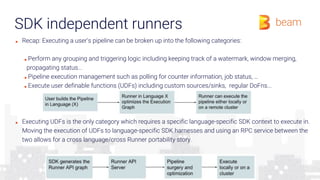

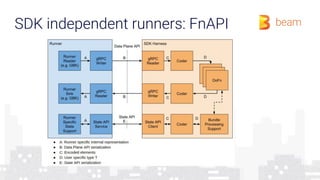



The document provides an overview of how a beam runner executes a data pipeline, detailing the pipeline's structure, which consists of a directed acyclic graph (DAG) of transforms and data flows called pcollections. It explains various components such as implementing ptransforms (e.g., read, flatten, groupbykey) and the importance of optimising execution plans, state persistence, and supporting different SDKs through the Runner API. The author emphasizes the flexibility and fault-tolerance of the Beam model while addressing the management of data across distributed systems.























































































