Downloaded 492 times








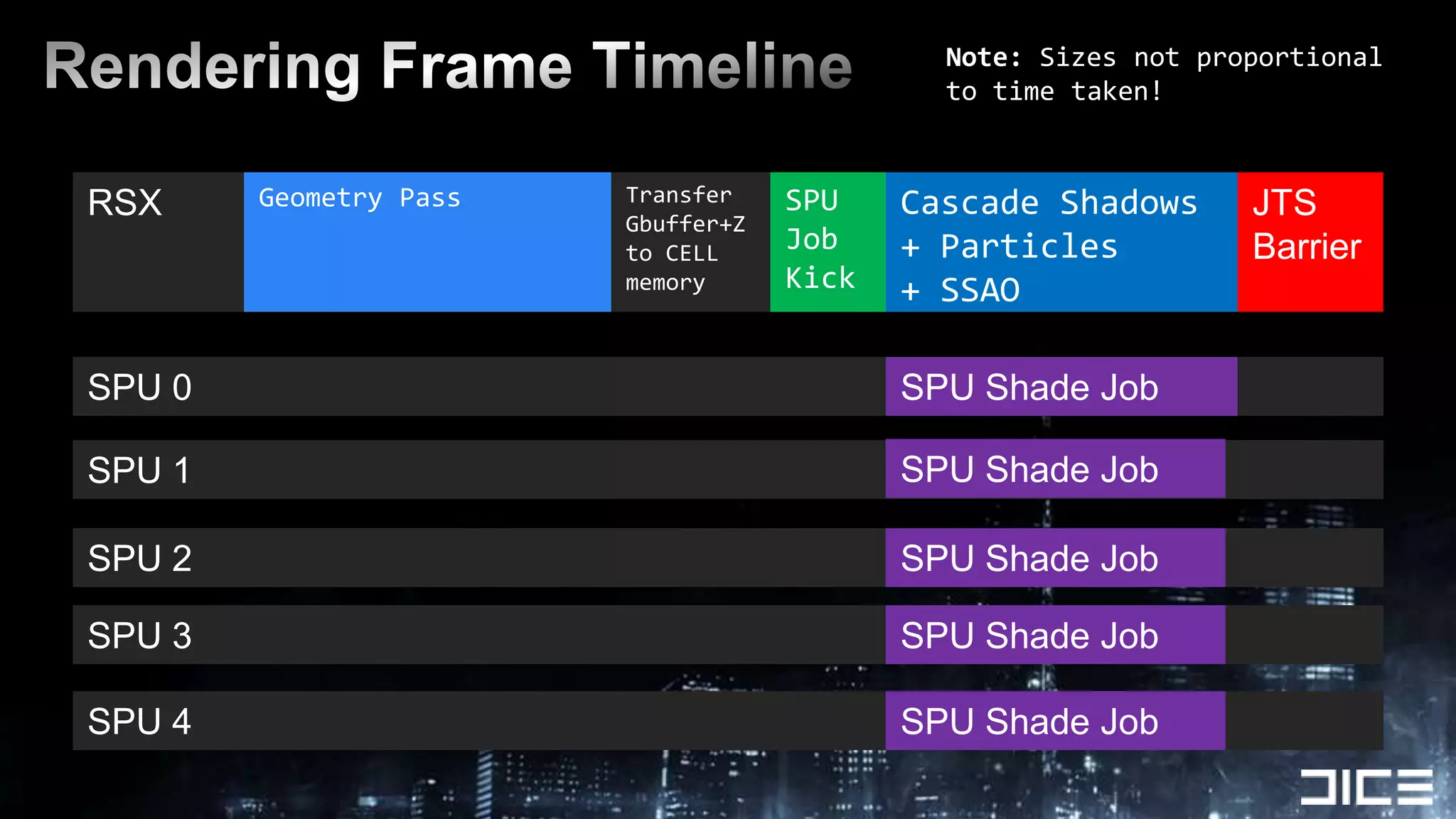
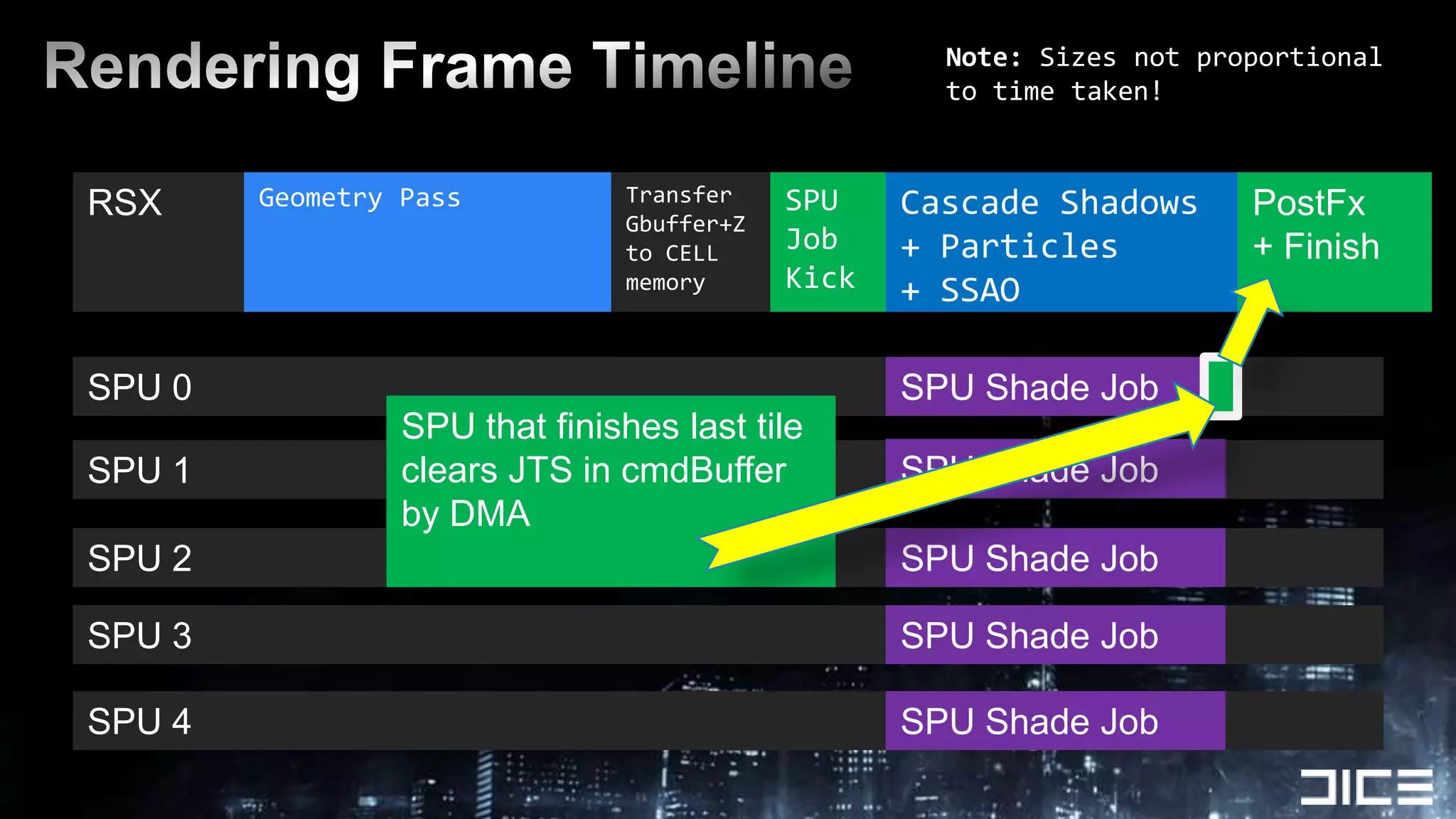

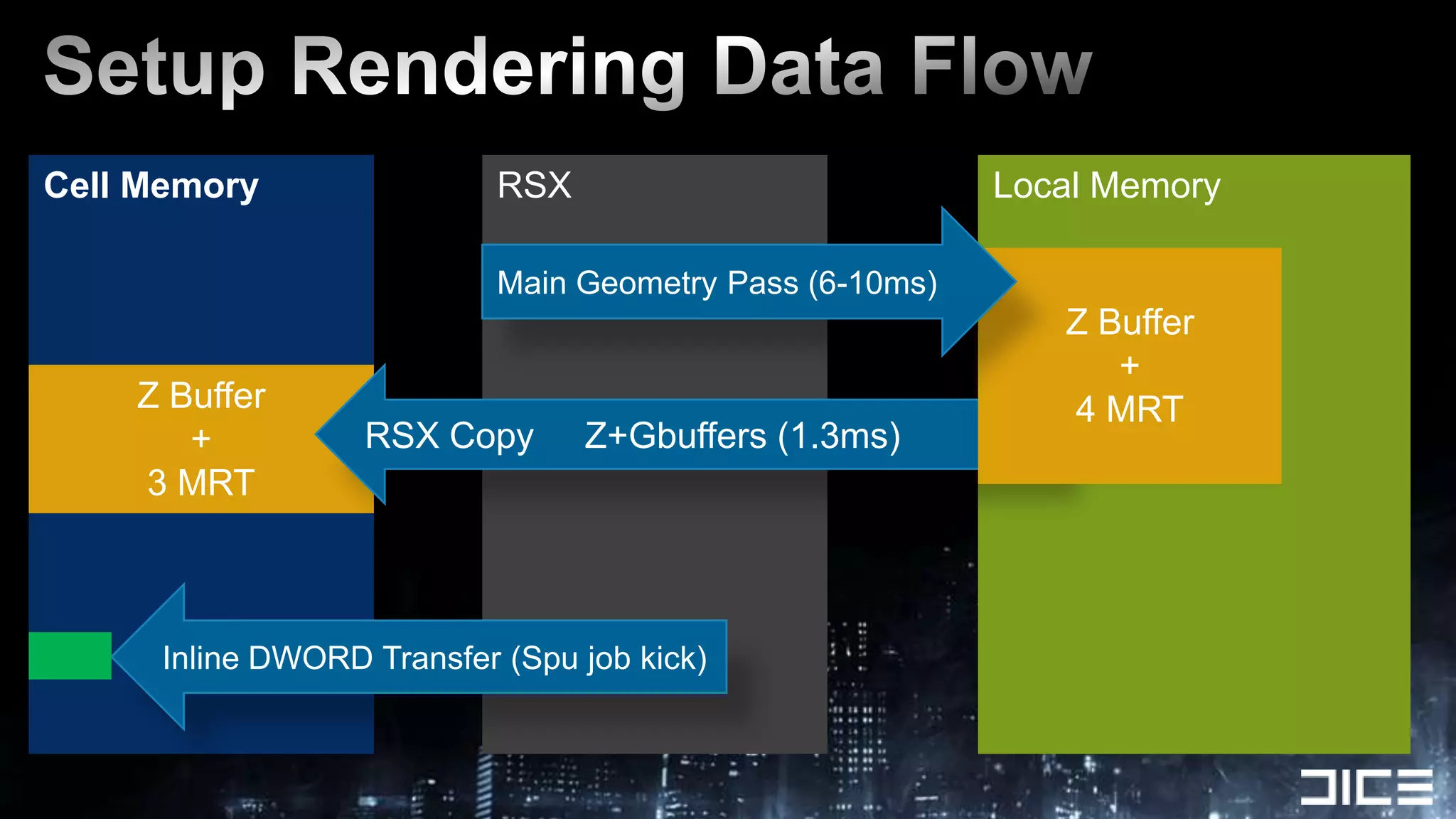
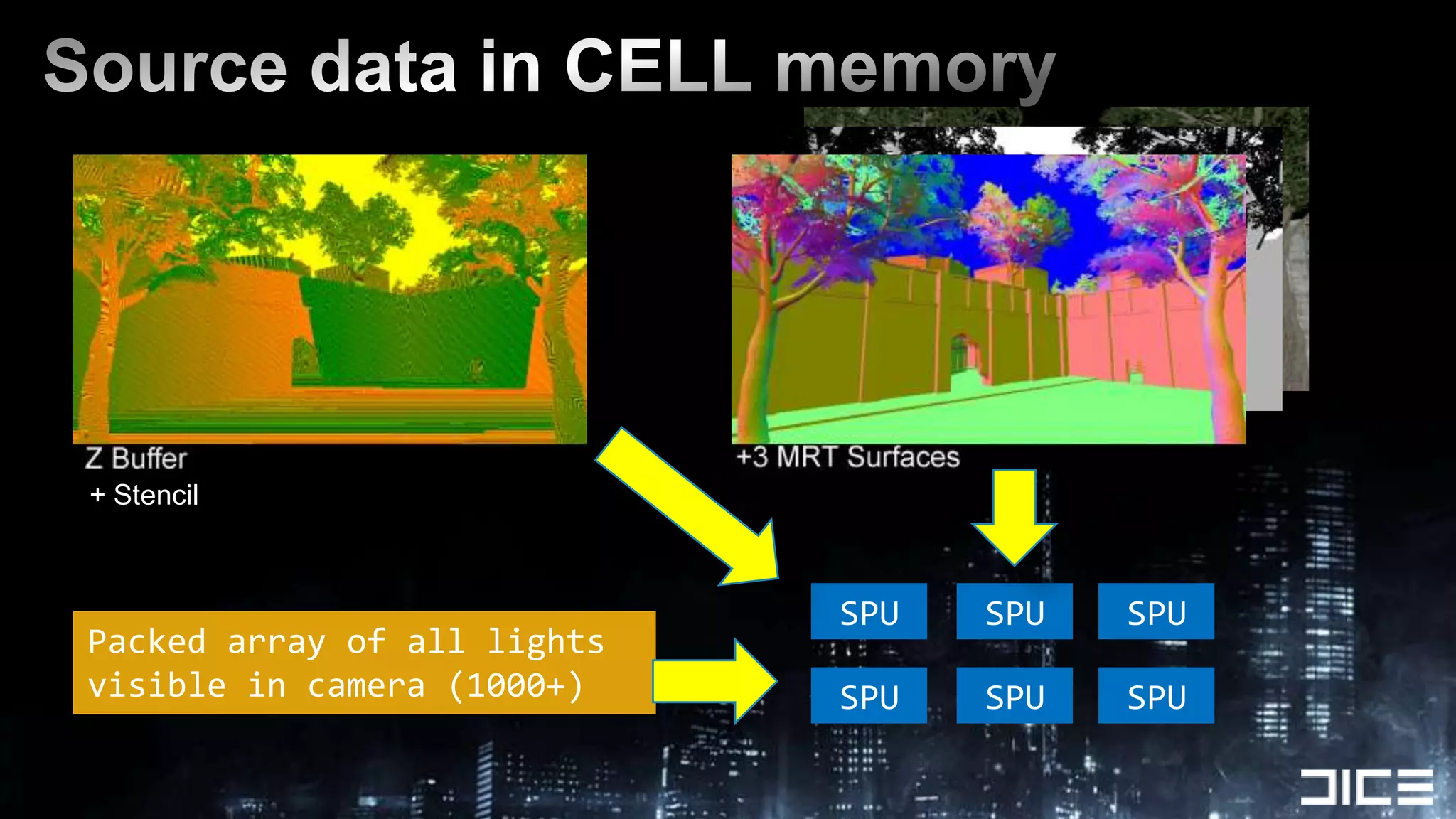
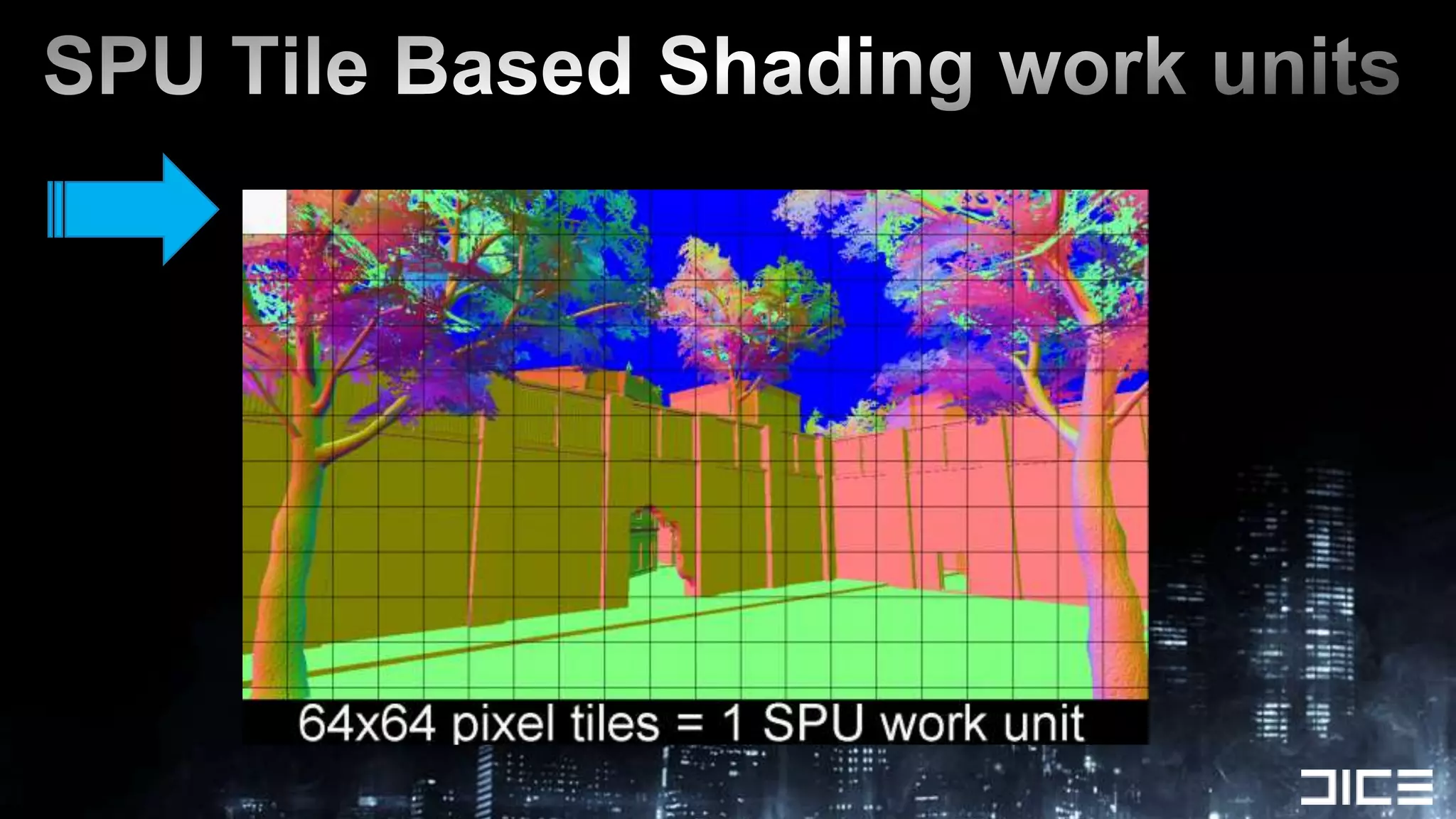
















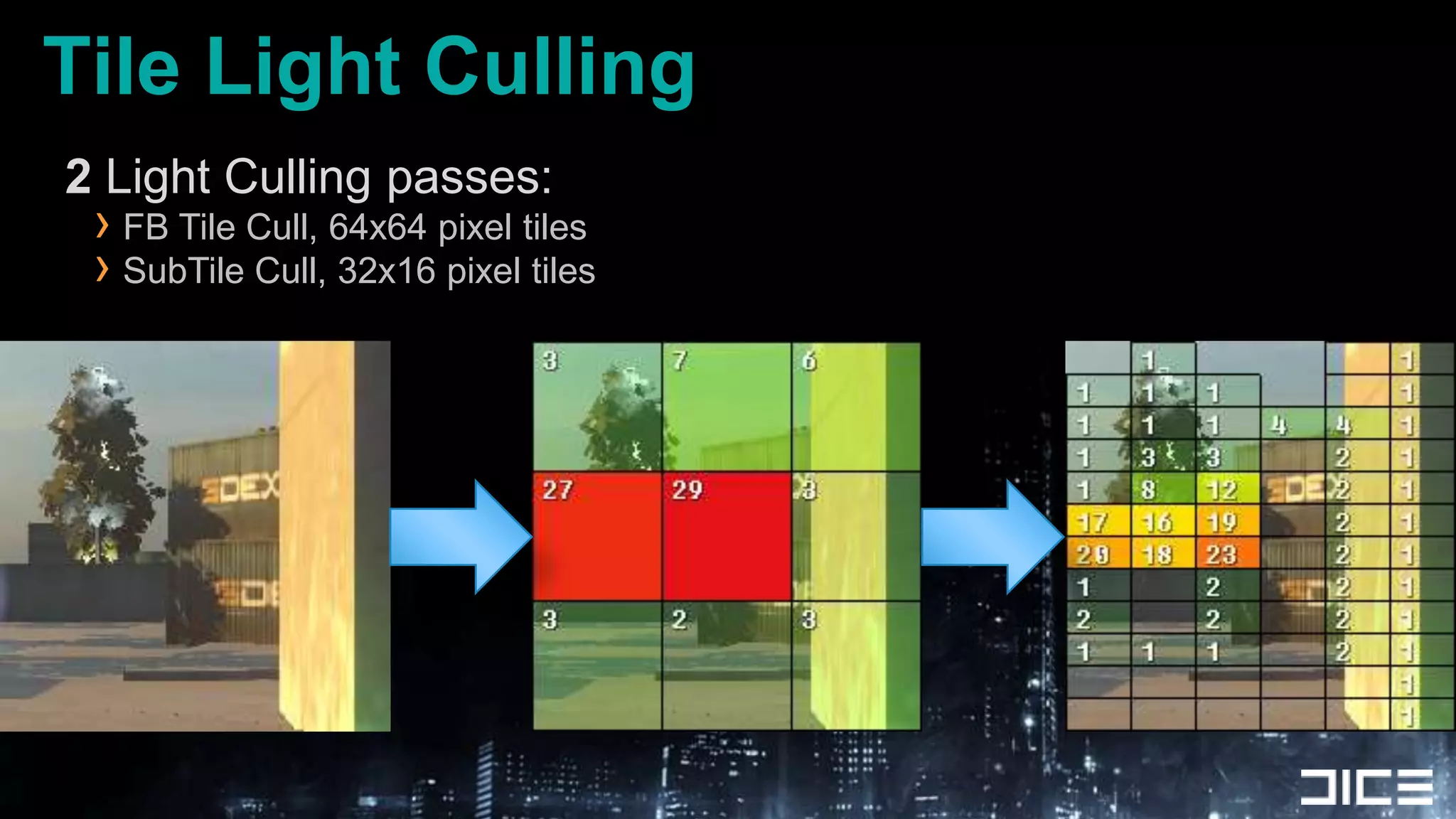
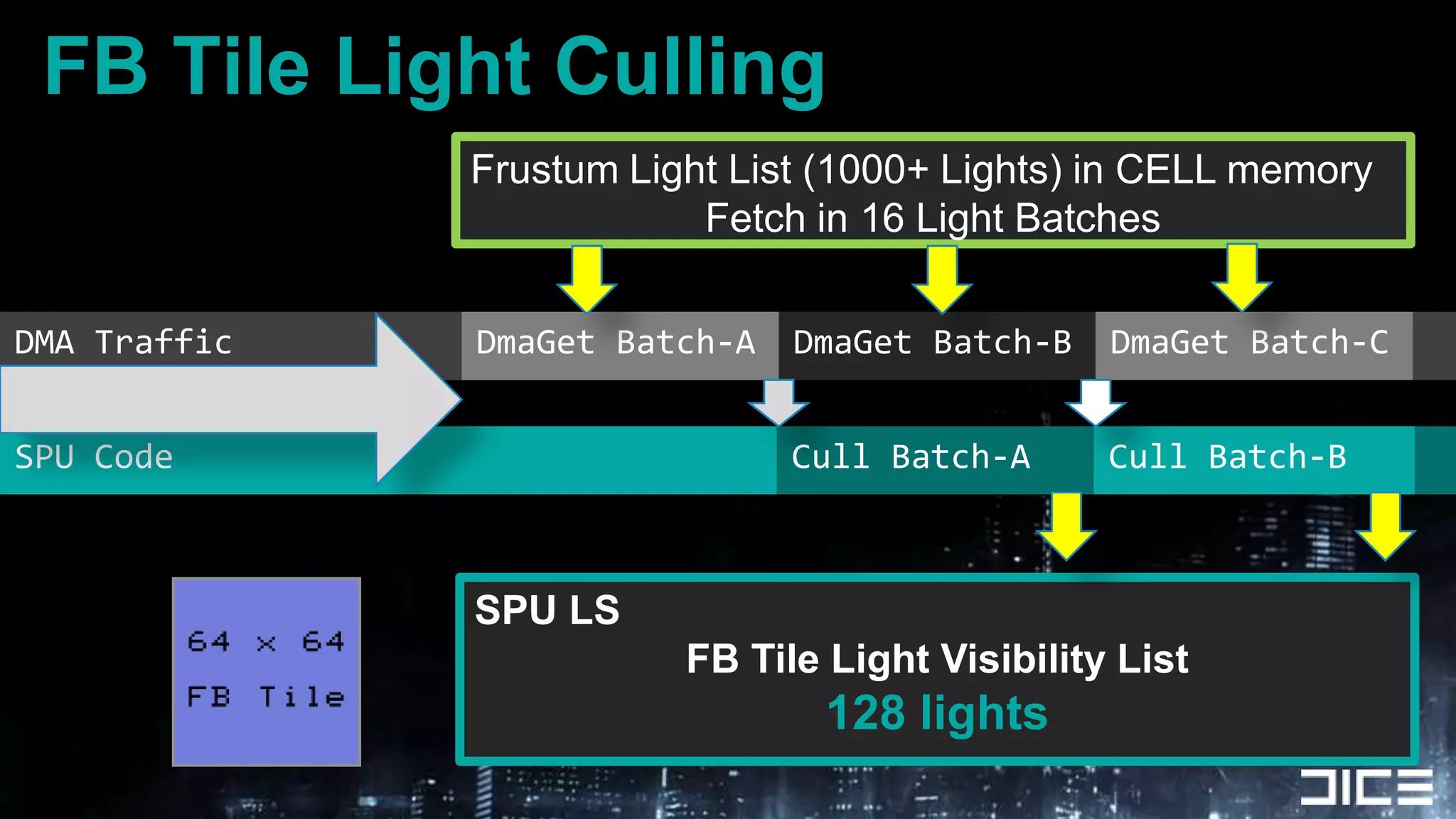
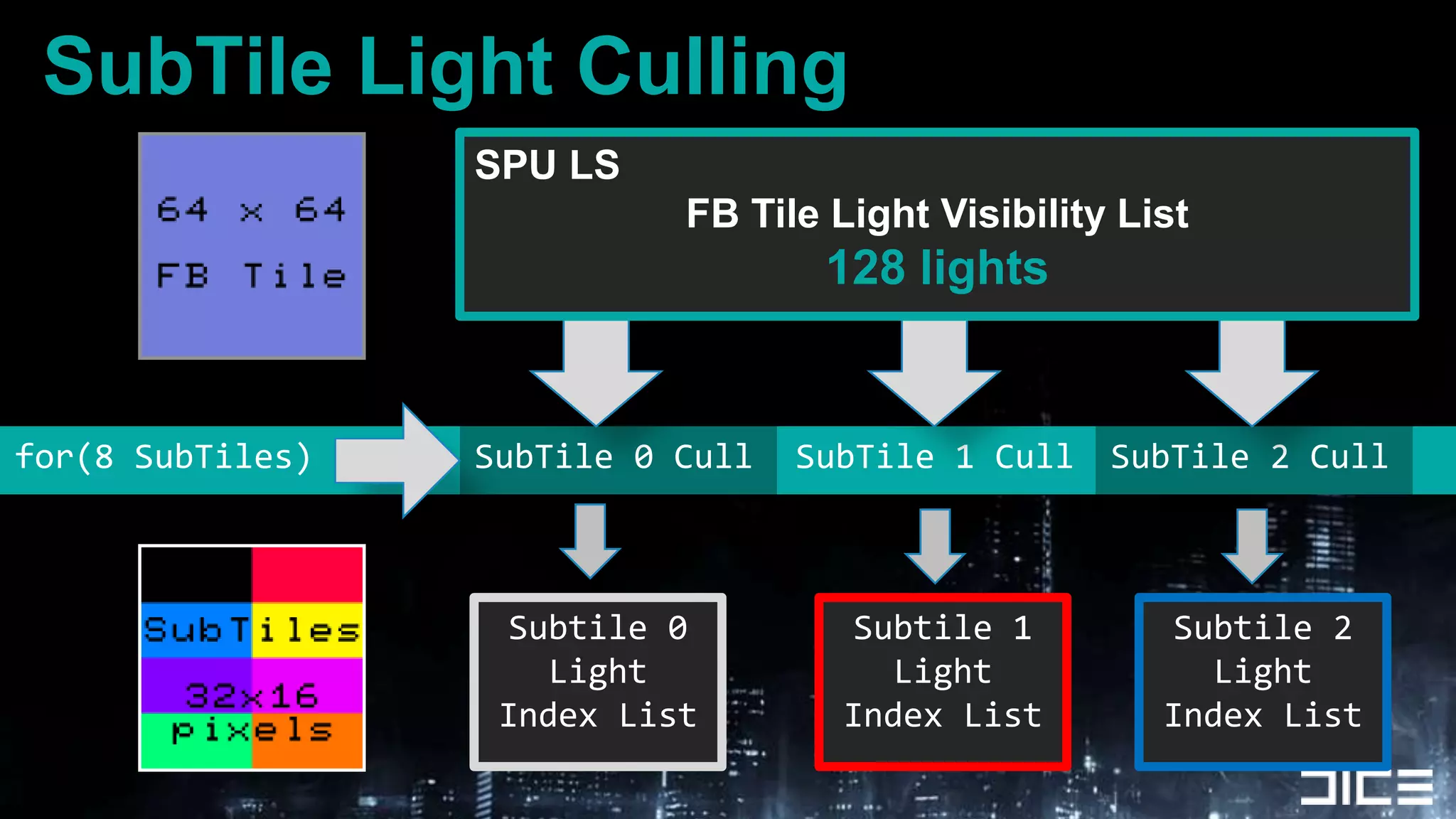

















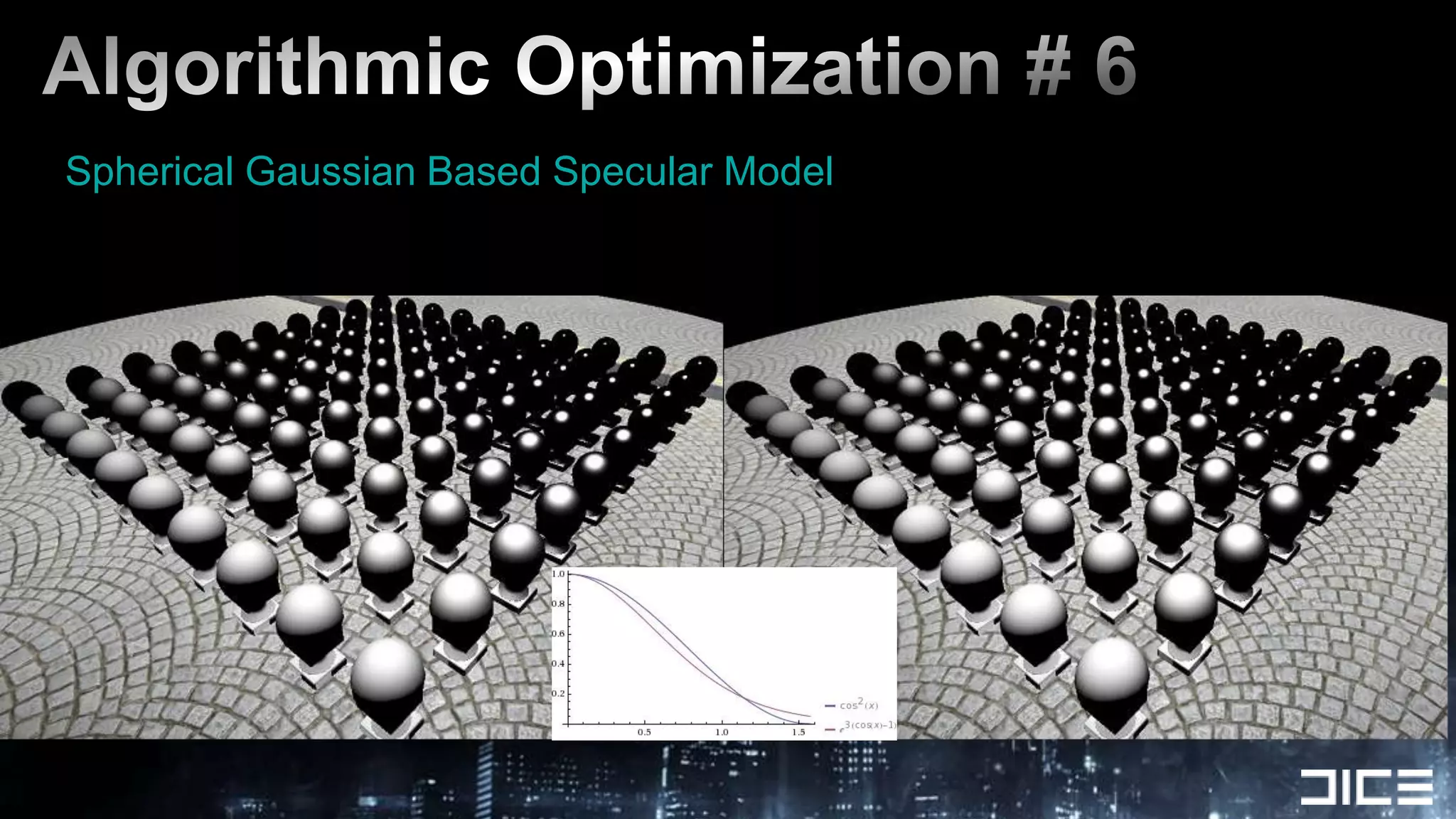









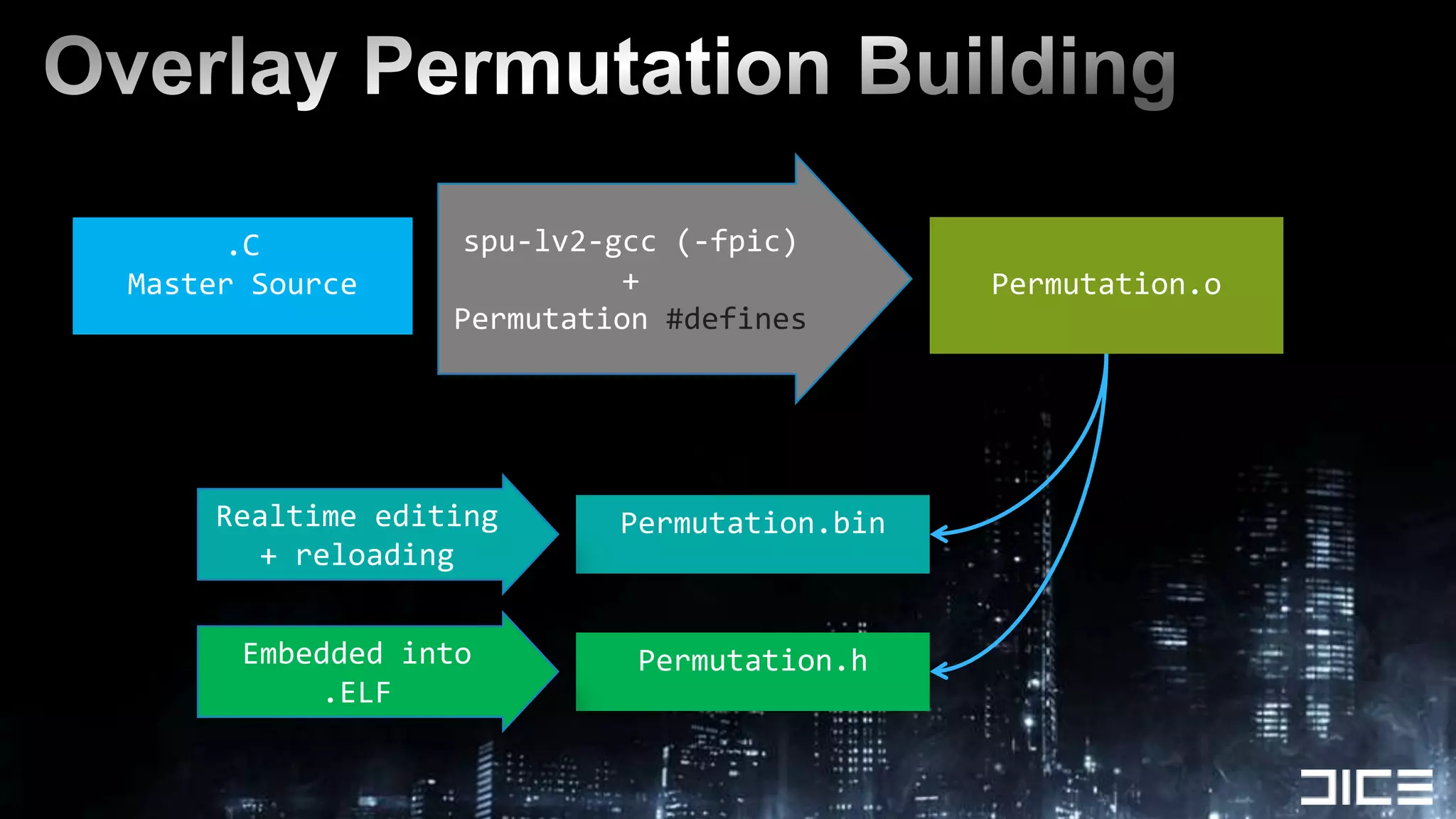










This document discusses using the SPUs on the PlayStation 3 to perform deferred shading for Battlefield 3, offloading work from the GPU. It provides an overview of the SPU-based deferred shading approach, including breaking the screen into tiles that are processed by multiple SPUs in parallel. Algorithmic optimizations discussed include aggressive light culling, material classification, and using lookup tables. Code optimizations focus on data layout, instruction scheduling, and generating shader permutations at compile time. Best practices include tools for rapid development and profiling permutation usage.
































































































