Download as PDF, PPTX












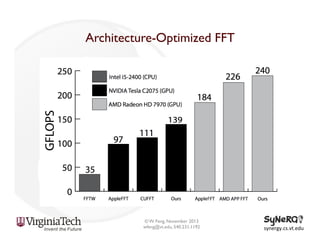









![Programmability: Why Accelerated OpenMP?
# pragma omp parallel for
shared(in1,in2,out,pow)
for (i=0; i<end; i++){
out[i] = in1[i]*in2[i];
pow[i] = pow[i]*pow[i];
}
Traditional OpenMP
# pragma acc_region_loop
acc_copyin(in1[0:end],in2[0:end])
acc_copyout(out[0:end])
acc_copy(pow[0:end])
for (i=0; i<end; i++){
out[i] = in1[i] * in2[i];
pow[i] = pow[i]*pow[i];
}
OpenMP Accelerator Directives
# pragma acc_region_loop
acc_copyin(in1[0:end],in2[0:end])
acc_copyout(out[0:end])
acc_copy(pow[0:end])
hetero(<cond>[,<scheduler>[,<ratio>
[,<div>]]])
for (i=0; i<end; i++){
out[i] = in1[i] * in2[i];
pow[i] = pow[i]*pow[i];
}
Our Proposed Extension
© W. Feng, November 2013
wfeng@vt.edu, 540.231.1192
synergy.cs.vt.edu](https://image.slidesharecdn.com/hc-4022wuchunfeng-131206074918-phpapp01/85/HC-4022-Towards-an-Ecosystem-for-Heterogeneous-Parallel-Computing-by-Wu-Feng-49-320.jpg)
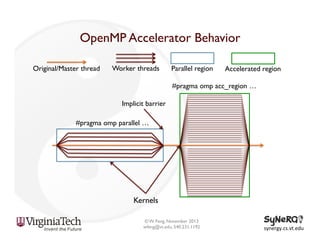
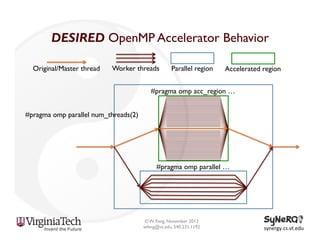
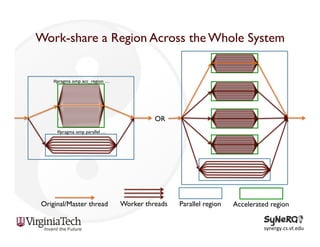




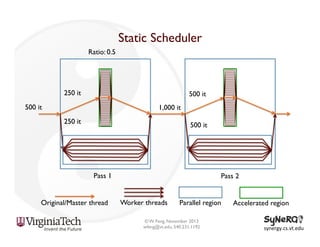
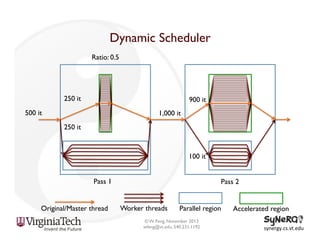
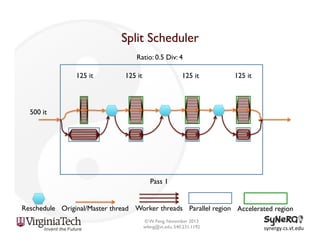
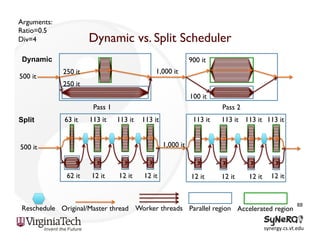
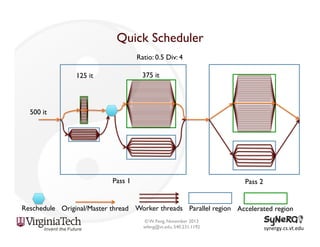
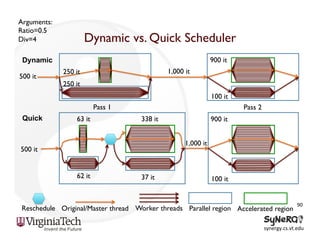


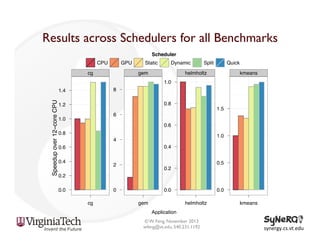
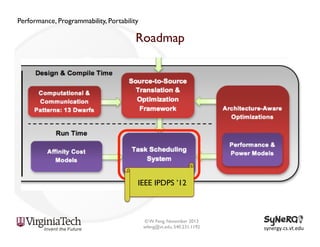
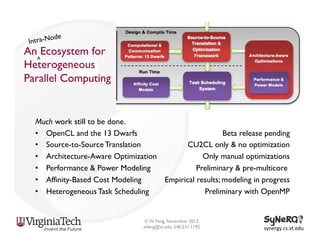
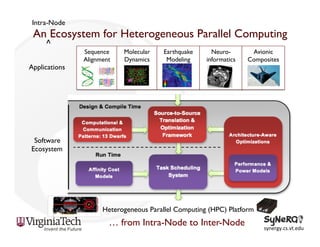
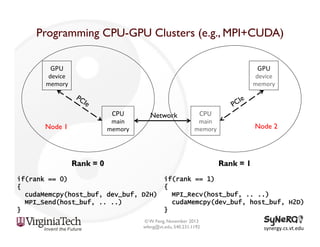
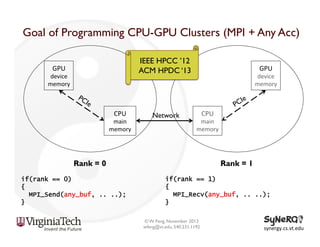
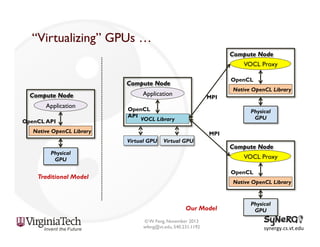





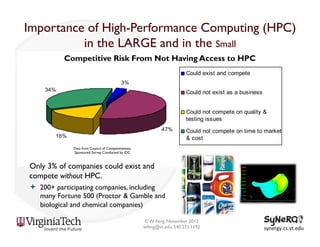
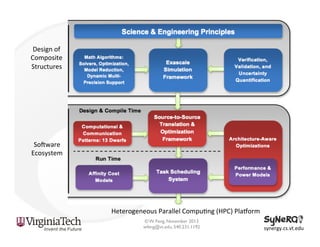
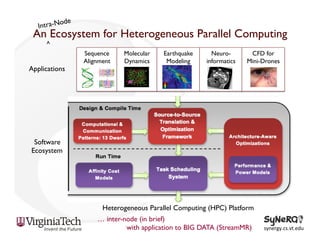
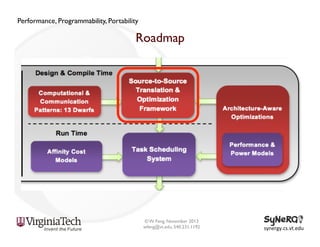
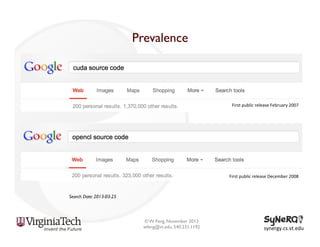
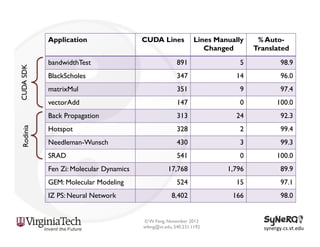
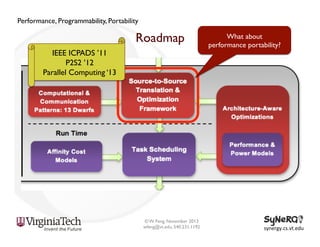
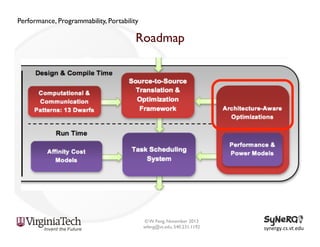
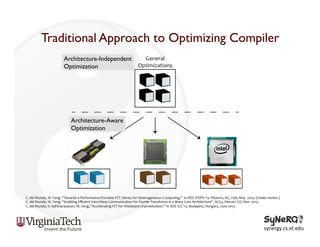
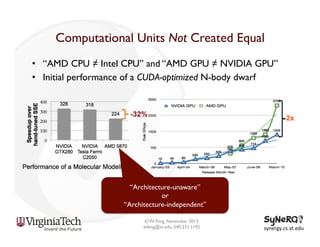
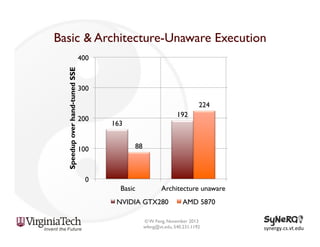
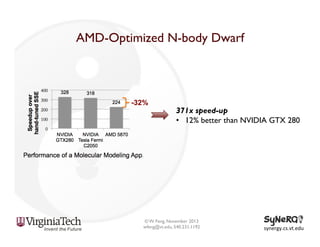
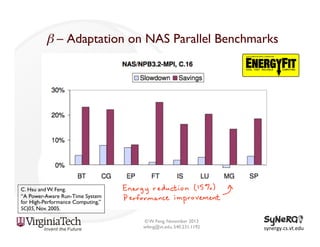
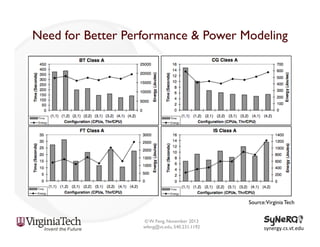
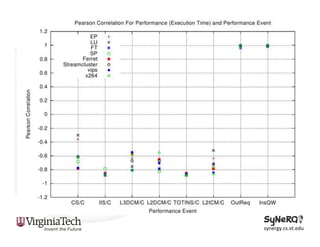
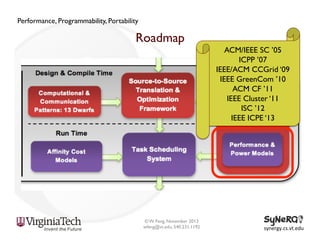
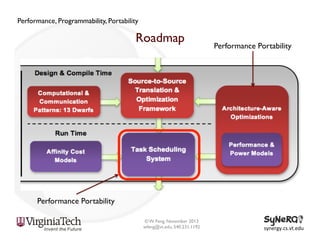
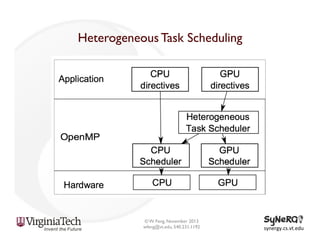
The document discusses the evolution and importance of heterogeneous parallel computing and high-performance computing (HPC), emphasizing the competitive risks companies face without HPC access. It introduces concepts like the 'Beowulf cluster' and a roadmap for performance, programmability, and portability, including tools such as CUDA and OpenCL for optimizing GPU programming. The importance of a reliable ecosystem for HPC, the role of computational dwarfs, and advances in performance and power modeling are also highlighted.











































![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















































