Downloaded 404 times











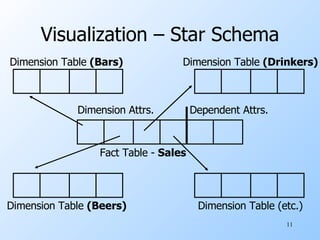













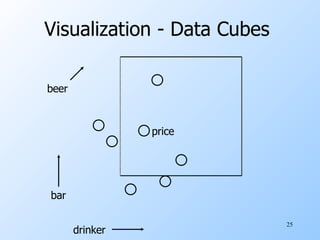

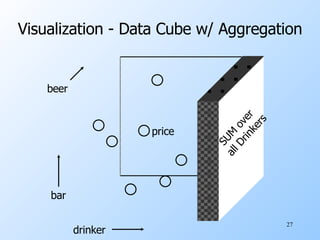




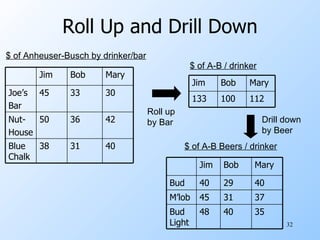











The document discusses various techniques for data warehousing and online analytical processing (OLAP), including constructing data warehouses, star schemas, materialized views, data cubes, and data mining. Specifically, it describes how a data warehouse can be used to integrate data from multiple sources and support complex OLAP queries run against historical data. It provides examples of star schemas, materialized views, data cubes, and market basket analysis to find frequent itemsets.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











