Download to read offline


















![d-VMP as a projected natural gradient ascent
Insight 1: VMP can be expressed as a projected natural
gradient ascent algorithm.
η
(t+1)
X = η
(t)
X + ρX,t[ ˆ ηL(η(t)
)]+
X (1)
[·] is the projection operator.
Int. Conf. on Probabilistic Graphical Models, Lugano, Sept. 6–9, 2016 21](https://image.slidesharecdn.com/pgm2016-160920102332/85/d-VMP-Distributed-Variational-Message-Passing-PGM2016-21-320.jpg)


![d-VMP as a projected natural gradient ascent
d-VMP is based on performing independent global updates
over the global parameters of each partition:
η
(t+1)
Jr
= η
(t)
Jr
+ ρr,t[ ˆ ηL(η(t)
)]+
Jr
ρr,t is the learning rate. If |Jr | = 1 then ρr,t = 1.
Int. Conf. on Probabilistic Graphical Models, Lugano, Sept. 6–9, 2016 24](https://image.slidesharecdn.com/pgm2016-160920102332/85/d-VMP-Distributed-Variational-Message-Passing-PGM2016-24-320.jpg)
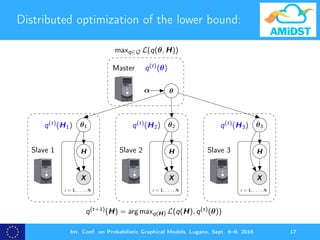
![dVMP as a distributed PNGA algorithm:
Master
θα
η
(t+1)
Jr
X
H
θ1
i = 1, . . . , N
Slave 1
η
(t+1)
1
X
H
θ2
i = 1, . . . , N
Slave 2
η
(t+1)
2
X
H
θ3
i = 1, . . . , N
Slave 3
η
(t+1)
3
η
(t)
Jr
+ ρr,t[ˆηL(η(t)
)]+
Jr
For all Jr ∈ R
maxq∈Q L(q(θ, H))
Int. Conf. on Probabilistic Graphical Models, Lugano, Sept. 6–9, 2016 25](https://image.slidesharecdn.com/pgm2016-160920102332/85/d-VMP-Distributed-Variational-Message-Passing-PGM2016-25-320.jpg)

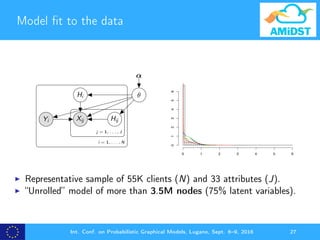










The document presents D-VMP, a distributed variational message passing algorithm aimed at improving the convergence of generative models for financial datasets. It highlights the limitations of existing methods like Stochastic Variational Inference (SVI) and showcases D-VMP's advantages in scalability and accuracy through experimental results involving large models. The method facilitates Bayesian learning with over one billion nodes, utilizing distributed computing environments for efficient processing.


















































































