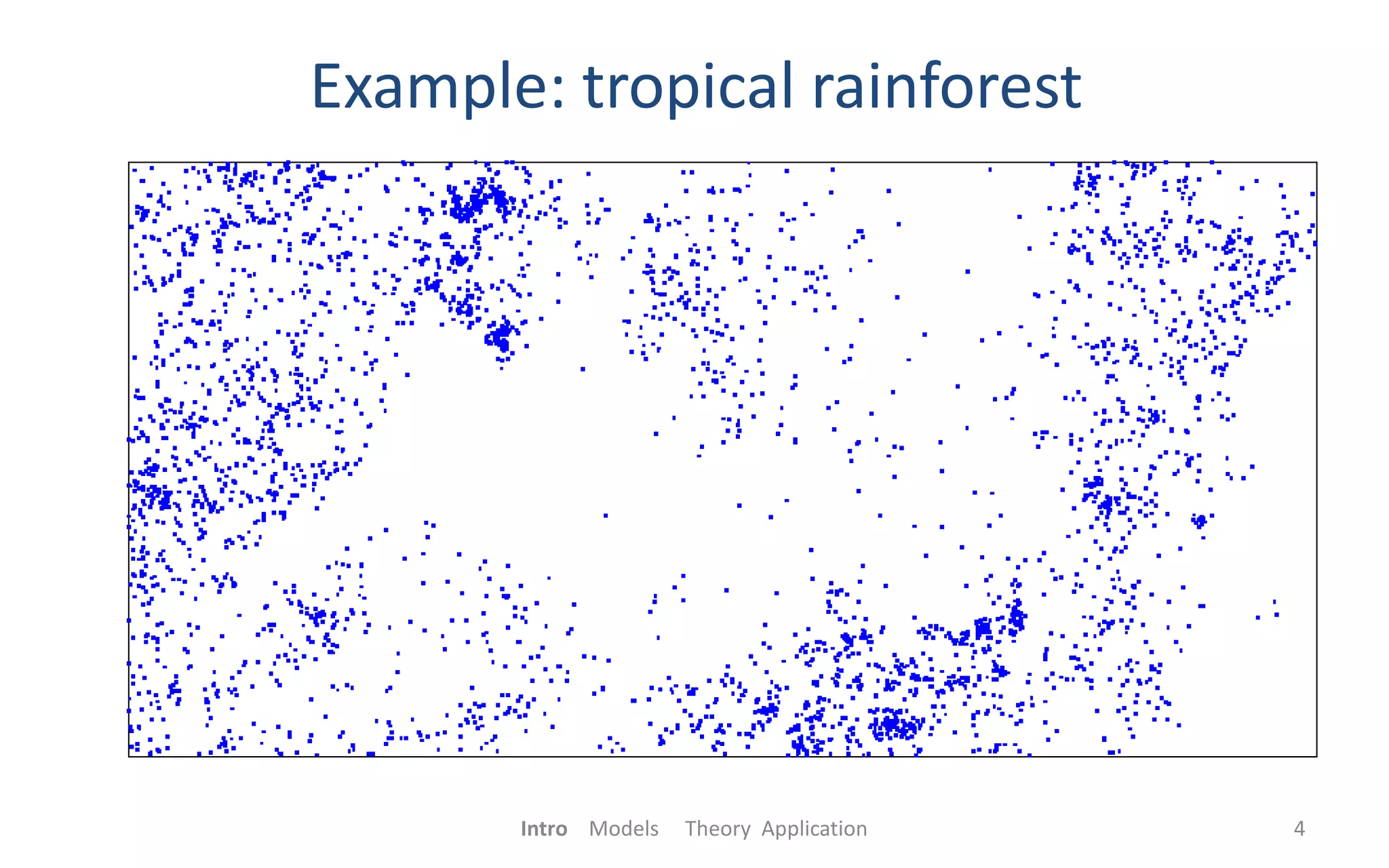
Spatial statistics can be used in epidemiology to analyze spatial point patterns of disease cases and controls. Common models include homogeneous and inhomogeneous Poisson processes, which describe patterns of complete spatial randomness and non-random clustering or dispersion. Descriptive statistics like the first-order intensity function λ(s) and second-order K-function can quantify clustering in a point pattern. A case-control study compares these statistics between case and control patterns to test for non-random spatial variations in disease risk. Monte Carlo simulations are used to calculate p-values when testing hypotheses about relative risk and clustering.














![Kernel smoothed intensity of IPP
Intro Models Theory Application
16
Kernel estimated intensity for the point pattern simulated from HPP
with λ(s) = 400xy on [0, 1] * [0, 1].](https://image.slidesharecdn.com/9077f8b1-72fb-41dd-bd8e-edacf933ceca-170126034608/75/Spatial-Point-Processes-and-Their-Applications-in-Epidemiology-16-2048.jpg)
![Summary statistics: second-order
The second-order properties of a point process involve
relationship between number of events at different locations.
• The second-order intensity of a spatial point process is
• A point process is called stationary if
• A stationary point process is isotropic if
Intro Models Theory Application 17
ji
ji
ss
ji
ss
ss
ss
ji dd
dNdNE
dd
)]()([
lim),(
0,
2
)(),(
,)(
22 jiji ssss
ss
)(),( 22 jiji ssss ](https://image.slidesharecdn.com/9077f8b1-72fb-41dd-bd8e-edacf933ceca-170126034608/75/Spatial-Point-Processes-and-Their-Applications-in-Epidemiology-17-2048.jpg)
![If a point process is stationary and isotropic, the K-function of
the process is defined by:
λK(r) = E[number of further events within distance r from an
arbitrary event]
Two properties of K-function:
• For a HPP, λK(r) = λπr2 , thus Kp(r) = πr2
• K(r) is invariant to random thinning.
Intro Models Theory Application
18
K-function
Def. random thinning: each event of a point process X is either
retained or deleted with retention probability p, independently of
other events. The resulting point process X’ contains a subset of
events of the original process X.](https://image.slidesharecdn.com/9077f8b1-72fb-41dd-bd8e-edacf933ceca-170126034608/75/Spatial-Point-Processes-and-Their-Applications-in-Epidemiology-18-2048.jpg)





![Spatial risk
relative risk:
estimated relative risk:
H0:
test statistic:
estimated test statistic:
significance: Monte Carlo test
Intro Models Theory Application
24
)(
)(
)(
0
1
s
s
s
0
1
0)(
n
n
s
n
i
T
1
2
0 ])([ ix
n
i
T
1
2
0 ])(ˆ[ˆ ix
)(ˆ
)(ˆ
)(ˆ
0
1
s
s
s
](https://image.slidesharecdn.com/9077f8b1-72fb-41dd-bd8e-edacf933ceca-170126034608/75/Spatial-Point-Processes-and-Their-Applications-in-Epidemiology-24-2048.jpg)
(
)(ˆ)(ˆ)(ˆ
01 rKrKrD
0D(r)=](https://image.slidesharecdn.com/9077f8b1-72fb-41dd-bd8e-edacf933ceca-170126034608/75/Spatial-Point-Processes-and-Their-Applications-in-Epidemiology-25-2048.jpg)
![Monte Carlo test
1). simulation with random labelling at jth iteration, j=1, 2, …, 99
• randomly select n1 points from n data points and label the selected points as “case”, label
the remaining n0 points as “control”
• with the relabelled data, estimate kernel smoother and at every data point.
• estimate K1j(r) and K0j(r) and compute D̂j(r) at a set of discrete distances {r1, r2, …, rm} .
2). test statistic
• for each j, compute
• compute the variance of D̂(rk) for each k=1, 2, …, m. then get
3). p-value
Intro Models Theory Application
26
)(ˆ),(ˆ
01 xx jj )(ˆ xj
2
1 0 ])(ˆ[ˆ
n
i ijjT x
m
k
k
kj
j
rD
rD
D
1 )](ˆvar[
)(ˆ
ˆ
)199/(]1}ˆˆ{[
)199/(]1}ˆˆ{[
99
1
2
99
1
1
j
j
j
j
DDIp
TTIp](https://image.slidesharecdn.com/9077f8b1-72fb-41dd-bd8e-edacf933ceca-170126034608/75/Spatial-Point-Processes-and-Their-Applications-in-Epidemiology-26-2048.jpg)









































