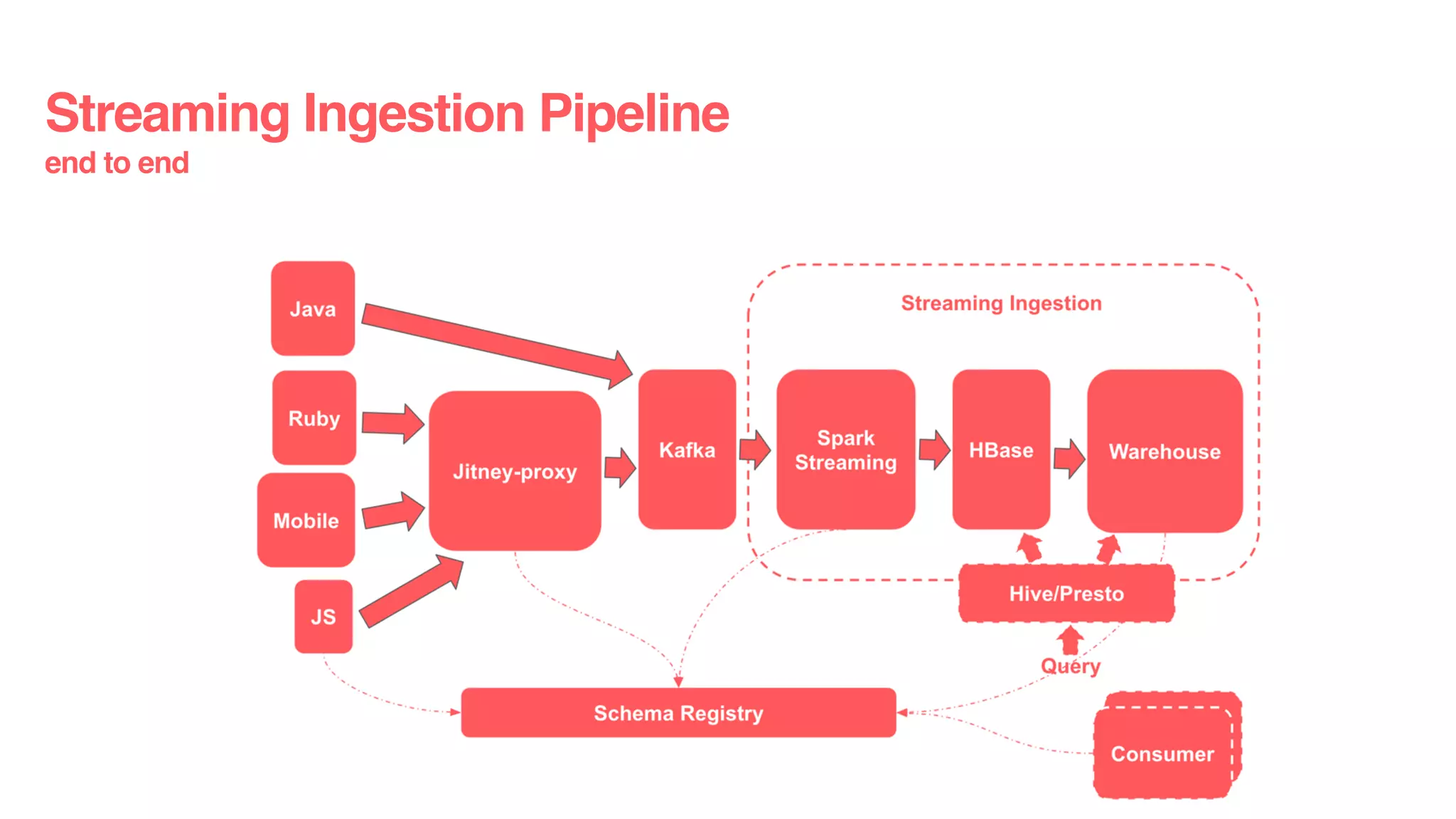
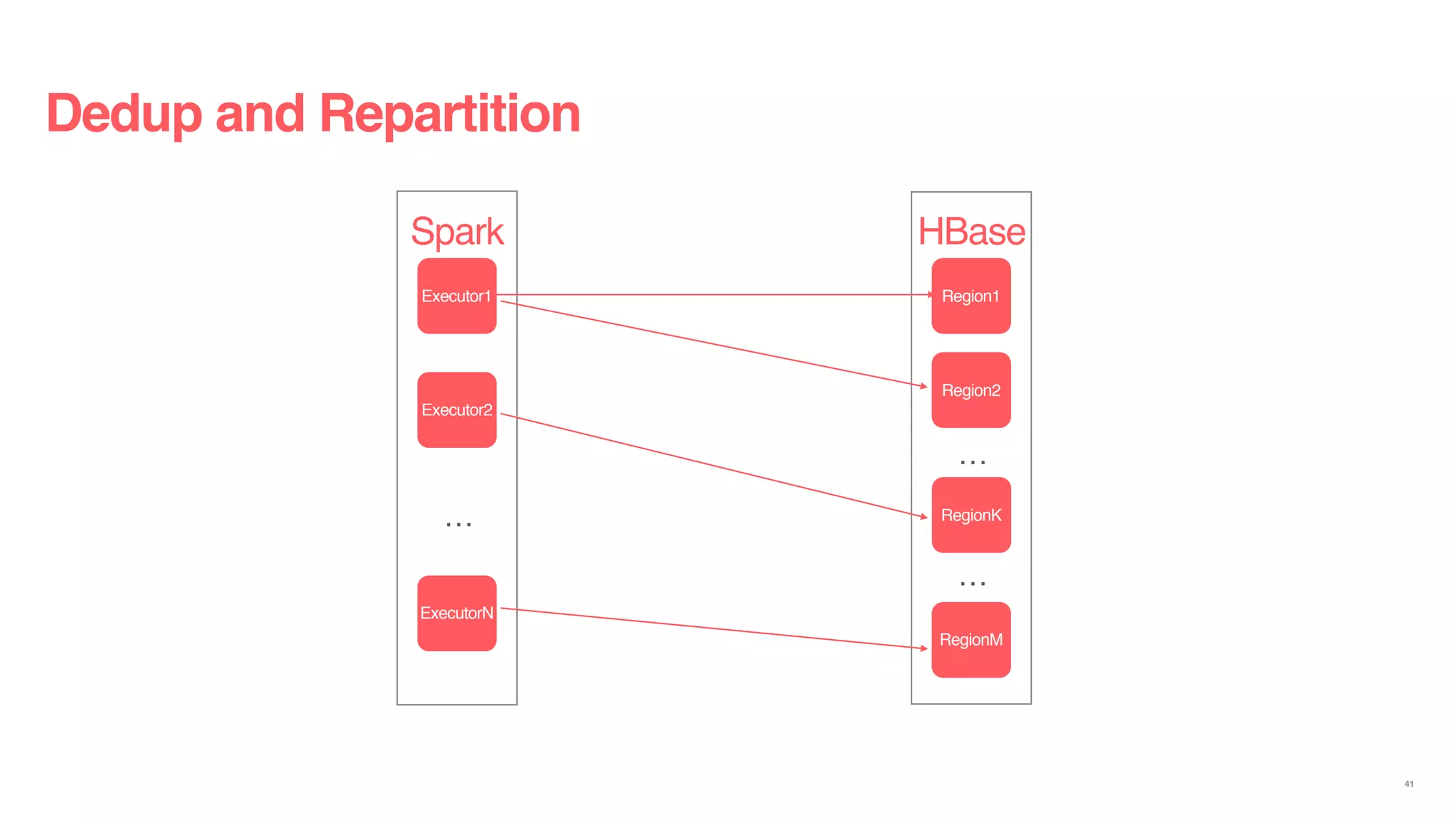
Download as PDF, PPTX


























![HBase Row Key
• Event key = event_type.event_name.event_uuid.
Ex: air_event.canaryevent.016230ae-a3d8-434e
• Shard id = Hash (Event key) % Shard_num
• Shard key = Region_start_keys[Shard_id].
Ex: 0000000
• Row key = Shard_key.Event_key.
Ex: 0000000.air_events.canaryevent.016230-a3db-434e
40](https://image.slidesharecdn.com/june29500airbnbzhangputtaswamy-160711181834/75/Reliable-and-Scalable-Data-Ingestion-at-Airbnb-40-2048.jpg)



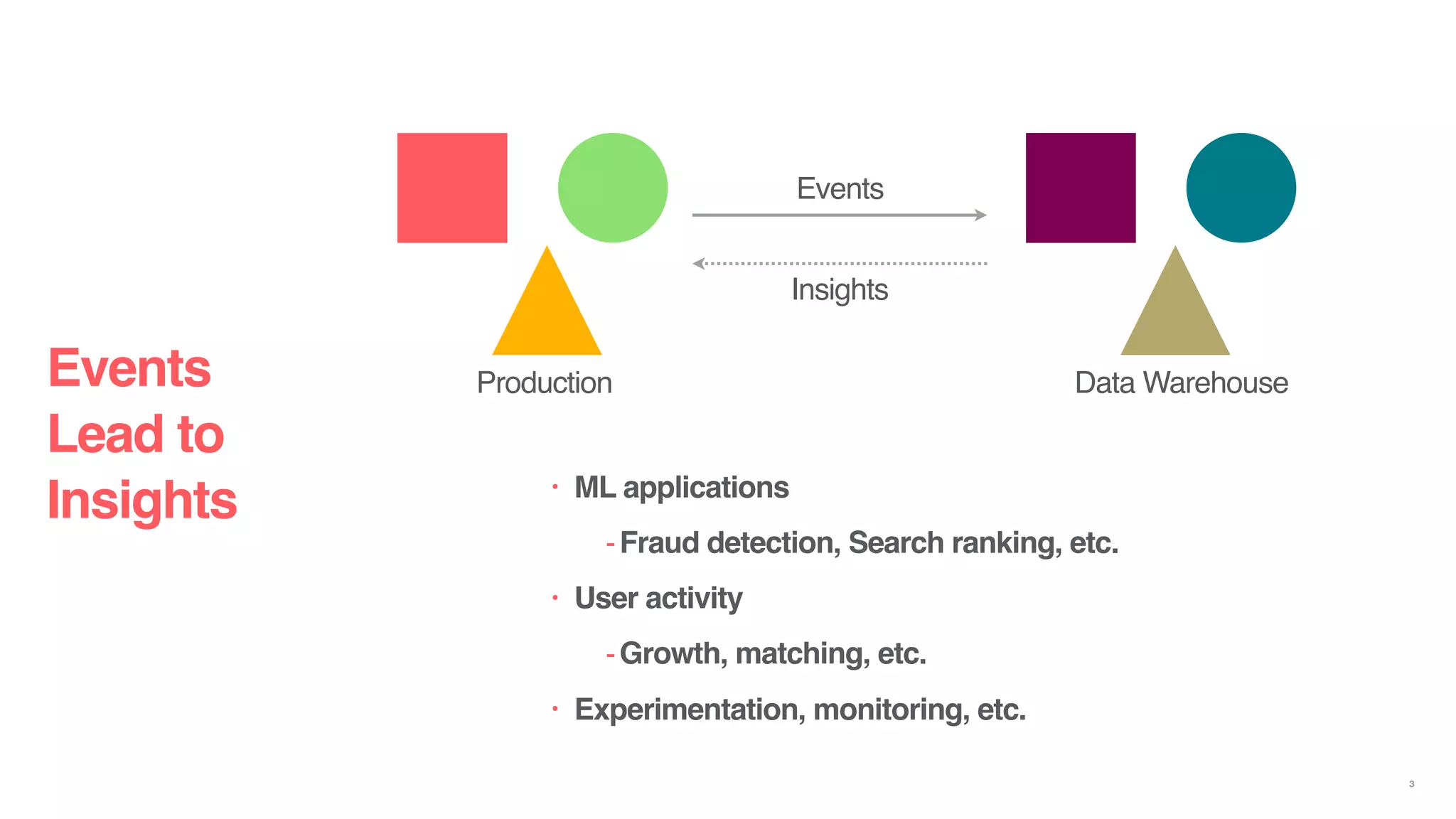
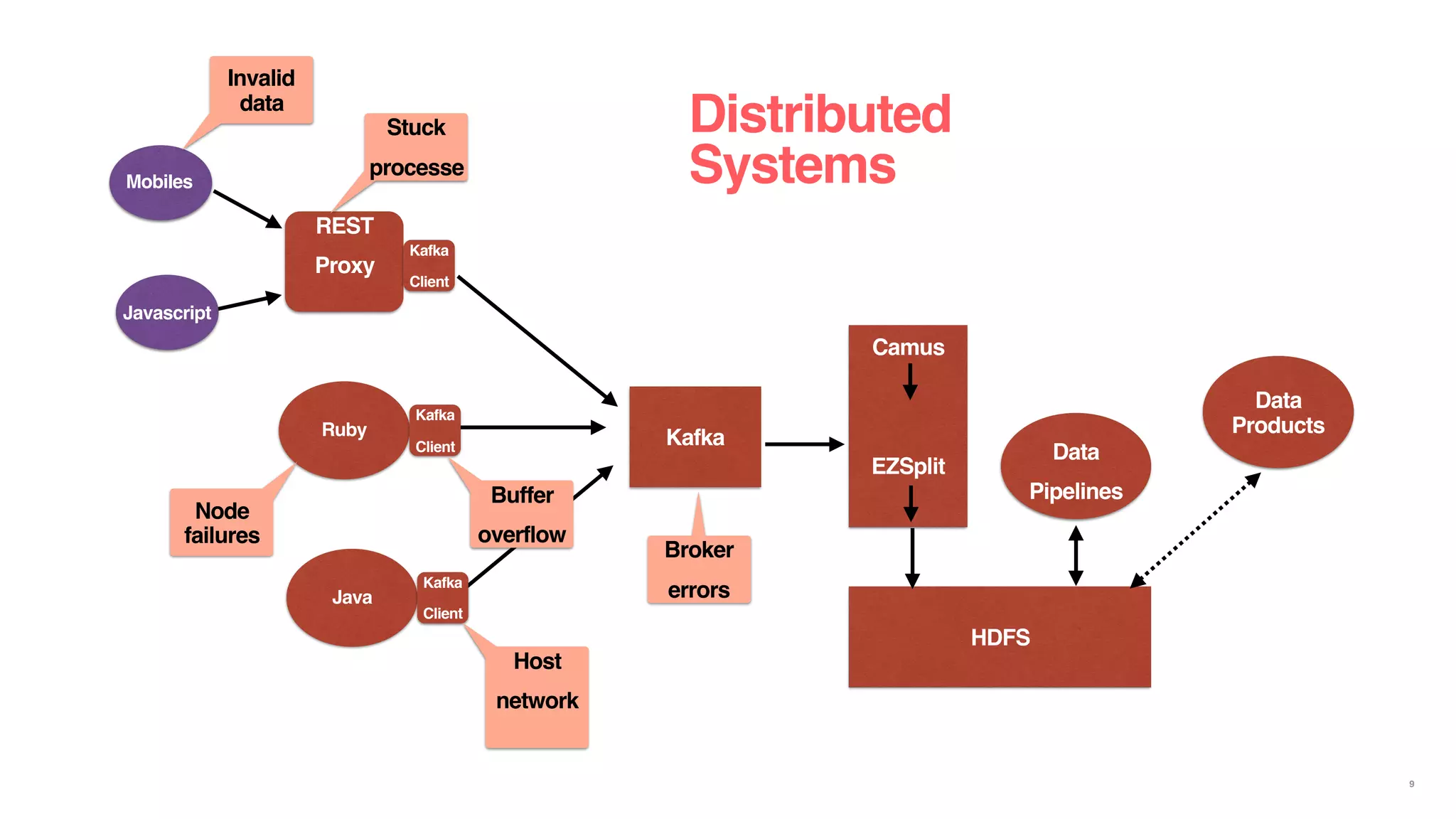
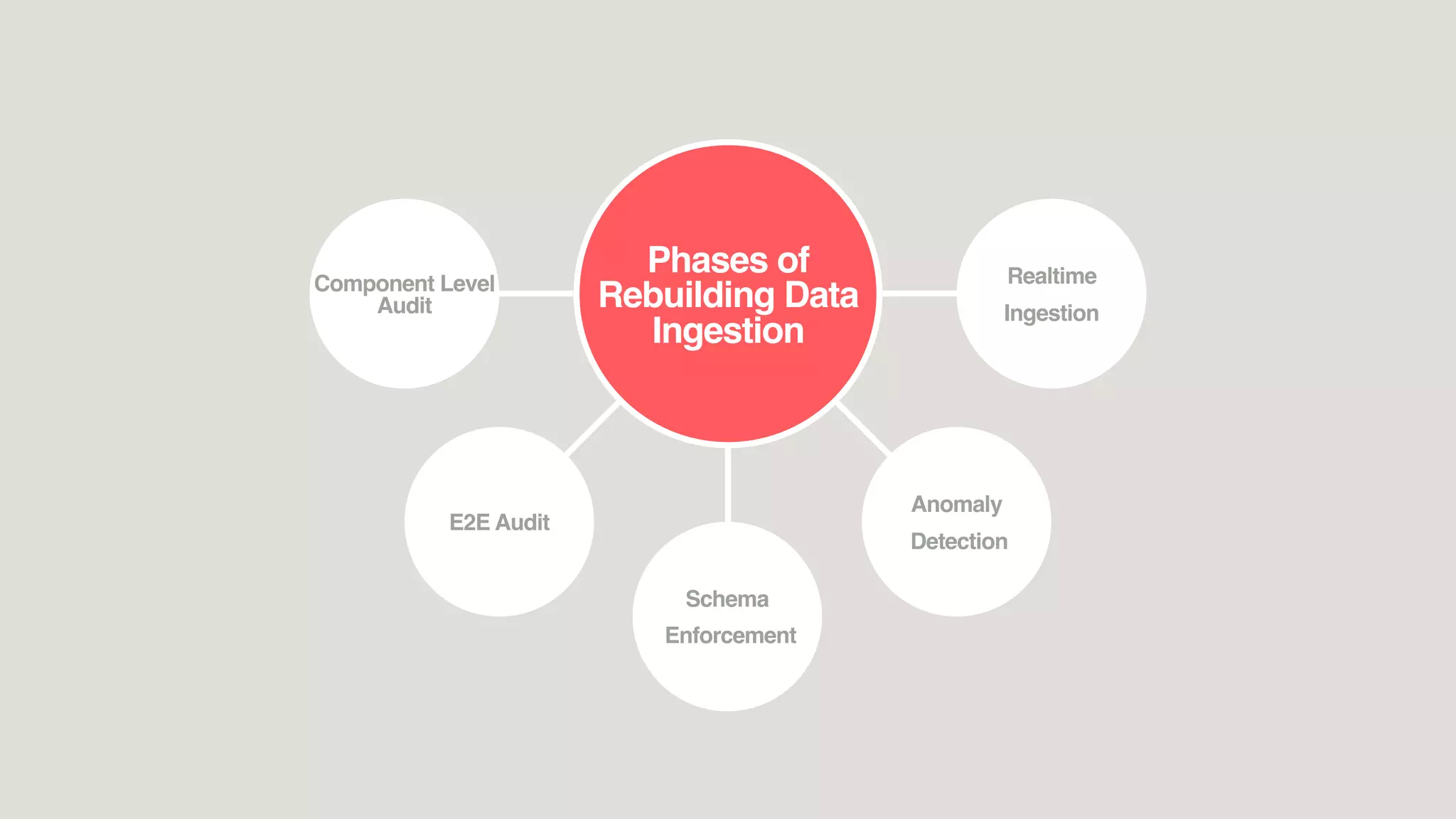
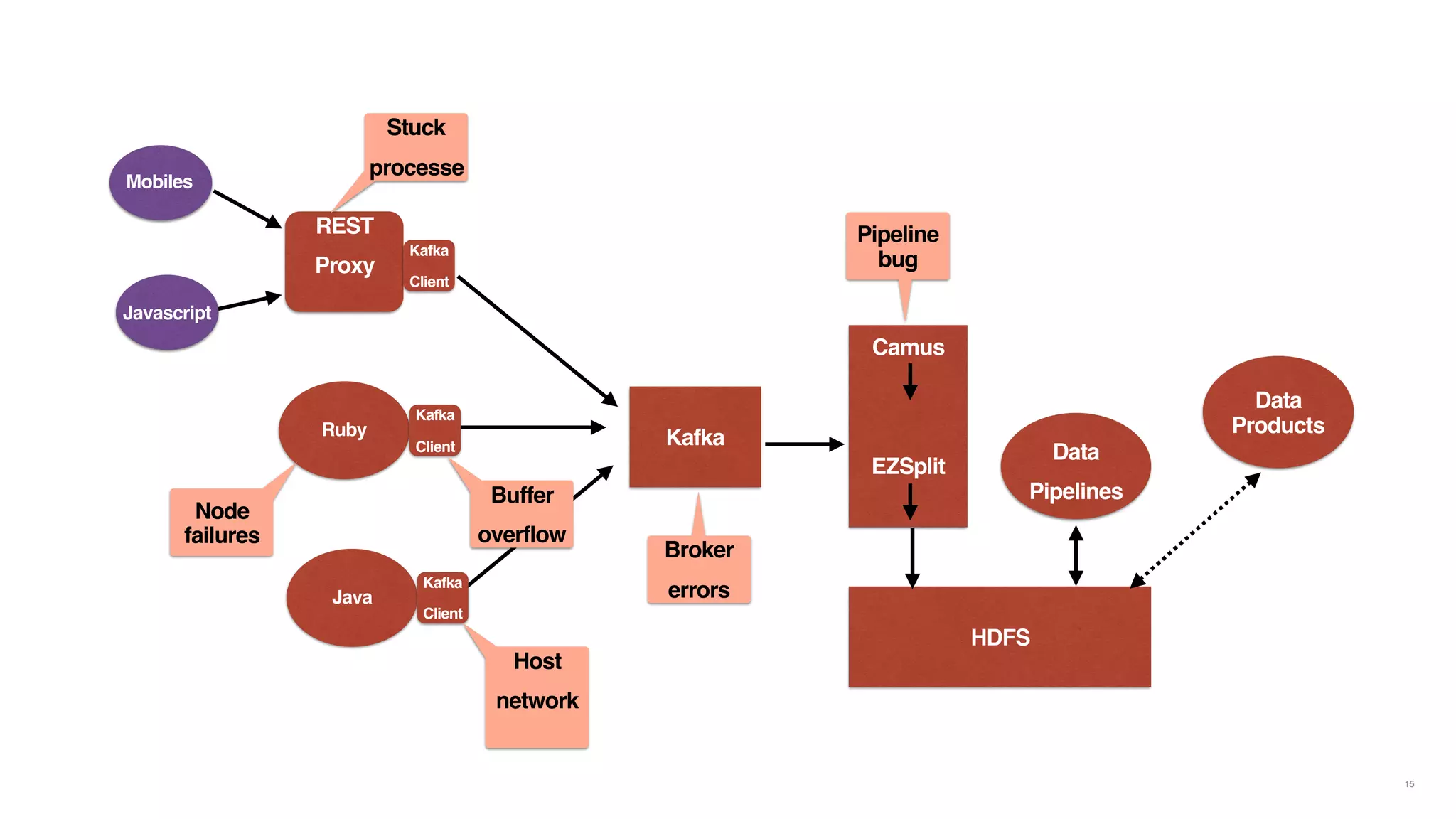
The document discusses reliable and scalable data ingestion at Airbnb. It describes the challenges they previously faced with unreliable and low quality data. It then outlines the five phases taken to rebuild their data ingestion system to be reliable: 1) auditing each component, 2) auditing the end-to-end system, 3) enforcing schemas, 4) implementing anomaly detection, and 5) building a real-time ingestion pipeline. The new system is able to ingest over 5 billion events per day with less than 100 events lost.




































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


