Downloaded 85 times




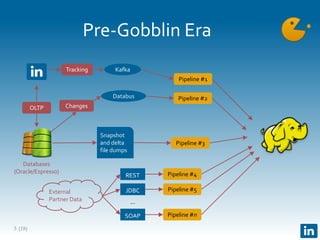
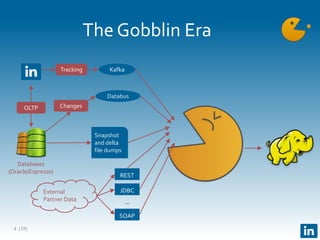

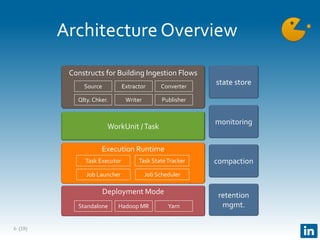
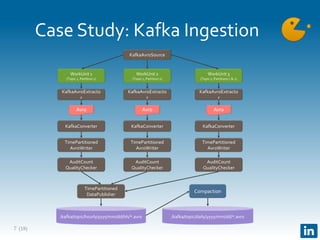
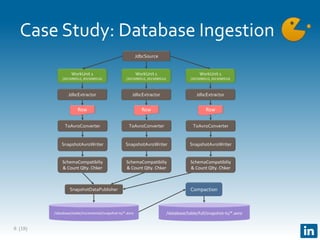
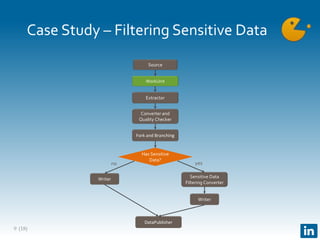
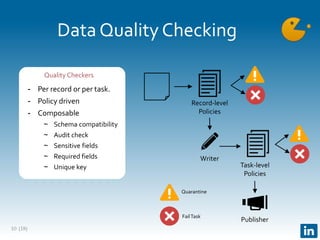
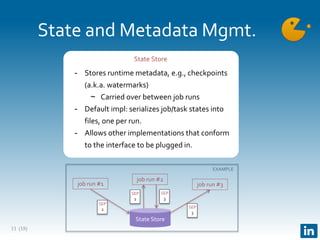
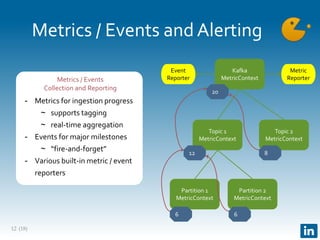
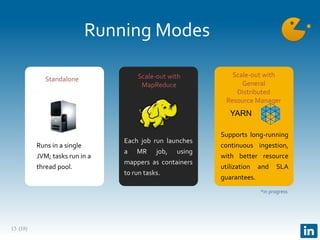






The document presents Gobblin, a unified data ingestion system developed by LinkedIn, designed to address challenges in data ingestion across various platforms. It covers the architecture, case studies, and features such as centralized state management and data quality checking, emphasizing Gobblin's production usage since 2014 with multiple data sources. Future developments include enhancements for real-time ingestion and improved integration with other data processing tools.











































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)







