Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Atsushi Hashimoto
PPTX, PDF
407 views
Ocha 20191204
Slides for a lecture in Ochanomizu Univ. Japan, held on 4th Dec. 2019.
Technology
◦
Related topics:
Deep Learning
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 56
2
/ 56
3
/ 56
4
/ 56
5
/ 56
6
/ 56
7
/ 56
8
/ 56
9
/ 56
10
/ 56
11
/ 56
12
/ 56
13
/ 56
14
/ 56
15
/ 56
16
/ 56
17
/ 56
18
/ 56
19
/ 56
20
/ 56
21
/ 56
22
/ 56
23
/ 56
24
/ 56
25
/ 56
26
/ 56
27
/ 56
28
/ 56
29
/ 56
30
/ 56
31
/ 56
32
/ 56
33
/ 56
34
/ 56
35
/ 56
36
/ 56
37
/ 56
38
/ 56
39
/ 56
40
/ 56
41
/ 56
42
/ 56
43
/ 56
44
/ 56
45
/ 56
46
/ 56
47
/ 56
48
/ 56
49
/ 56
50
/ 56
51
/ 56
52
/ 56
53
/ 56
54
/ 56
55
/ 56
56
/ 56
More Related Content
PDF
グラフデータ分析 入門編
by
順也 山口
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
PDF
点群深層学習 Meta-study
by
Naoya Chiba
PPTX
Graph Neural Networks
by
tm1966
PDF
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
PDF
深層生成モデルと世界モデル, 深層生成モデルライブラリPixyzについて
by
Masahiro Suzuki
グラフデータ分析 入門編
by
順也 山口
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
点群深層学習 Meta-study
by
Naoya Chiba
Graph Neural Networks
by
tm1966
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
深層生成モデルと世界モデル, 深層生成モデルライブラリPixyzについて
by
Masahiro Suzuki
What's hot
PDF
Pythonによる機械学習
by
Kimikazu Kato
PDF
論文紹介「PointNetLK: Robust & Efficient Point Cloud Registration Using PointNet」
by
Naoya Chiba
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
機械学習 入門
by
Hayato Maki
PPTX
Structural data analysis based on multilayer networks
by
tm1966
PDF
確率モデルを用いた3D点群レジストレーション
by
Kenta Tanaka
PPTX
SakataMoriLab GNN勉強会第一回資料
by
ttt_miura
PDF
[論文紹介] Convolutional Neural Network(CNN)による超解像
by
Rei Takami
PDF
[DL輪読会]Learning to Simulate Complex Physics with Graph Networks
by
Deep Learning JP
PDF
第126回 ロボット工学セミナー 三次元点群と深層学習
by
Naoya Chiba
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
Neural networks for Graph Data NeurIPS2018読み会@PFN
by
emakryo
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
日本ソフトウェア科学会第36回大会発表資料「帰納的プログラミングの初等教育の試み」西澤勇輝
by
Preferred Networks
PDF
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
PPTX
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
PDF
SSII2019企画: 点群深層学習の研究動向
by
SSII
PDF
Graph Attention Network
by
Takahiro Kubo
PPTX
20190509 gnn public
by
Jiro Nishitoba
Pythonによる機械学習
by
Kimikazu Kato
論文紹介「PointNetLK: Robust & Efficient Point Cloud Registration Using PointNet」
by
Naoya Chiba
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
機械学習 入門
by
Hayato Maki
Structural data analysis based on multilayer networks
by
tm1966
確率モデルを用いた3D点群レジストレーション
by
Kenta Tanaka
SakataMoriLab GNN勉強会第一回資料
by
ttt_miura
[論文紹介] Convolutional Neural Network(CNN)による超解像
by
Rei Takami
[DL輪読会]Learning to Simulate Complex Physics with Graph Networks
by
Deep Learning JP
第126回 ロボット工学セミナー 三次元点群と深層学習
by
Naoya Chiba
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
Neural networks for Graph Data NeurIPS2018読み会@PFN
by
emakryo
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
日本ソフトウェア科学会第36回大会発表資料「帰納的プログラミングの初等教育の試み」西澤勇輝
by
Preferred Networks
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
SSII2019企画: 点群深層学習の研究動向
by
SSII
Graph Attention Network
by
Takahiro Kubo
20190509 gnn public
by
Jiro Nishitoba
Similar to Ocha 20191204
PDF
画像処理分野における研究事例紹介
by
nlab_utokyo
PDF
敵対的生成ネットワーク(GAN)
by
cvpaper. challenge
PDF
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
PPTX
人工知能を用いた医用画像処理技術
by
Yutaka KATAYAMA
PDF
機械学習とコンピュータビジョン入門
by
Kinki University
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PDF
Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image S...
by
harmonylab
PDF
データマイニング勉強会3
by
Yohei Sato
PDF
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
[IBIS2017 講演] ディープラーニングによる画像変換
by
Satoshi Iizuka
PDF
SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜
by
SSII
PDF
VIEW2013 Binarycode-based Object Recognition
by
Hironobu Fujiyoshi
PDF
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
PPTX
画像認識 第9章 さらなる話題
by
Shion Honda
PPTX
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
PDF
PCSJ/IMPS2021 講演資料:深層画像圧縮からAIの生成モデルへ (VAEの定量的な理論解明)
by
Akira Nakagawa
PPTX
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
PPTX
NeurIPS2019参加報告
by
Masanari Kimura
PDF
20141127 py datatokyomeetup2
by
Akira Shibata
画像処理分野における研究事例紹介
by
nlab_utokyo
敵対的生成ネットワーク(GAN)
by
cvpaper. challenge
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
人工知能を用いた医用画像処理技術
by
Yutaka KATAYAMA
機械学習とコンピュータビジョン入門
by
Kinki University
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image S...
by
harmonylab
データマイニング勉強会3
by
Yohei Sato
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
[IBIS2017 講演] ディープラーニングによる画像変換
by
Satoshi Iizuka
SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜
by
SSII
VIEW2013 Binarycode-based Object Recognition
by
Hironobu Fujiyoshi
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
画像認識 第9章 さらなる話題
by
Shion Honda
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
PCSJ/IMPS2021 講演資料:深層画像圧縮からAIの生成モデルへ (VAEの定量的な理論解明)
by
Akira Nakagawa
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
NeurIPS2019参加報告
by
Masanari Kimura
20141127 py datatokyomeetup2
by
Akira Shibata
More from Atsushi Hashimoto
PPTX
関西Cvprml勉強会2017.9資料
by
Atsushi Hashimoto
PPTX
春の情報処理祭り 2015 [リクルートx情報処理学会] CVIM 橋本
by
Atsushi Hashimoto
PPTX
人の行動をモデル化して予測する -調理作業支援を題材とした行動予測と情報提示-
by
Atsushi Hashimoto
PPTX
Eccv2018 report day4
by
Atsushi Hashimoto
PPTX
Eccv2018 report day3
by
Atsushi Hashimoto
PPTX
CVPR2017 参加報告 速報版 本会議3日目
by
Atsushi Hashimoto
PPTX
Eccv2018 report day2
by
Atsushi Hashimoto
PPTX
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
PPTX
CVPR2017 参加報告 速報版 本会議 1日目
by
Atsushi Hashimoto
PPTX
CVPR2017 参加報告 速報版 本会議 4日目
by
Atsushi Hashimoto
PPTX
CVPR2018 参加報告(速報版)2日目
by
Atsushi Hashimoto
PPTX
CVPR2017 参加報告 速報版 本会議 2日目
by
Atsushi Hashimoto
PPTX
PRMU GC第二期 無形概念認識
by
Atsushi Hashimoto
PPTX
Cvpr2018 参加報告(速報版)3日目
by
Atsushi Hashimoto
PPTX
ECCV2018参加速報(一日目)
by
Atsushi Hashimoto
PPTX
人工知能研究振興財団研究助成に対する成果報告
by
Atsushi Hashimoto
PPTX
Kusk Object Dataset: Recording Access to Objects in Food Preparation
by
Atsushi Hashimoto
関西Cvprml勉強会2017.9資料
by
Atsushi Hashimoto
春の情報処理祭り 2015 [リクルートx情報処理学会] CVIM 橋本
by
Atsushi Hashimoto
人の行動をモデル化して予測する -調理作業支援を題材とした行動予測と情報提示-
by
Atsushi Hashimoto
Eccv2018 report day4
by
Atsushi Hashimoto
Eccv2018 report day3
by
Atsushi Hashimoto
CVPR2017 参加報告 速報版 本会議3日目
by
Atsushi Hashimoto
Eccv2018 report day2
by
Atsushi Hashimoto
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
CVPR2017 参加報告 速報版 本会議 1日目
by
Atsushi Hashimoto
CVPR2017 参加報告 速報版 本会議 4日目
by
Atsushi Hashimoto
CVPR2018 参加報告(速報版)2日目
by
Atsushi Hashimoto
CVPR2017 参加報告 速報版 本会議 2日目
by
Atsushi Hashimoto
PRMU GC第二期 無形概念認識
by
Atsushi Hashimoto
Cvpr2018 参加報告(速報版)3日目
by
Atsushi Hashimoto
ECCV2018参加速報(一日目)
by
Atsushi Hashimoto
人工知能研究振興財団研究助成に対する成果報告
by
Atsushi Hashimoto
Kusk Object Dataset: Recording Access to Objects in Food Preparation
by
Atsushi Hashimoto
Ocha 20191204
1.
機械学習×画像処理の先端動向 2019.12.4@御茶ノ水女子大/理学総論 オムロンサイニックエックス(株) シニアリサーチャー 橋本敦史 https://atsushihashimoto.github.io/cv/
2.
自己紹介 ~2013.3 博士(情報学)@京都大学 - 机上作業を対象とした画像処理 ~2018.3
助教@京都大学 - 作業ガイダンス 2018.4~ OMRON SINIC X 株式会社 シニアリサーチャー
3.
この講演を通じての目標 • 目指すもの • 画像処理を題材として,最新の機械学習の話題に触れる •
限りなく応用よりの基礎理論部分をオムニバス形式で紹介. • それらを通して,現状の機械学習にもまだまだ課題があることを知る • 目指さないもの • 厳密な数学的理解(ふわっとした概念的な理解はして欲しい) • 他の資料なしでコーディングに落とせるほどの理解 • 希望すること • わからないことは講義中に質問してくれた方が嬉しいです (自分がわからないことは他の人もわからないはずです). • 誰がやってもTop Conferenceに通せる可能性がある分野だと感じてもらえれば.
4.
以下の2点を通る関数を求めよ (x,y) = (-5,-11) と
(5,19)
5.
以下の2点を通る関数を求めよ (x, y) =
(-5,-11) と (5,19) y = 3x + 4 中学校で習う連立方程式
6.
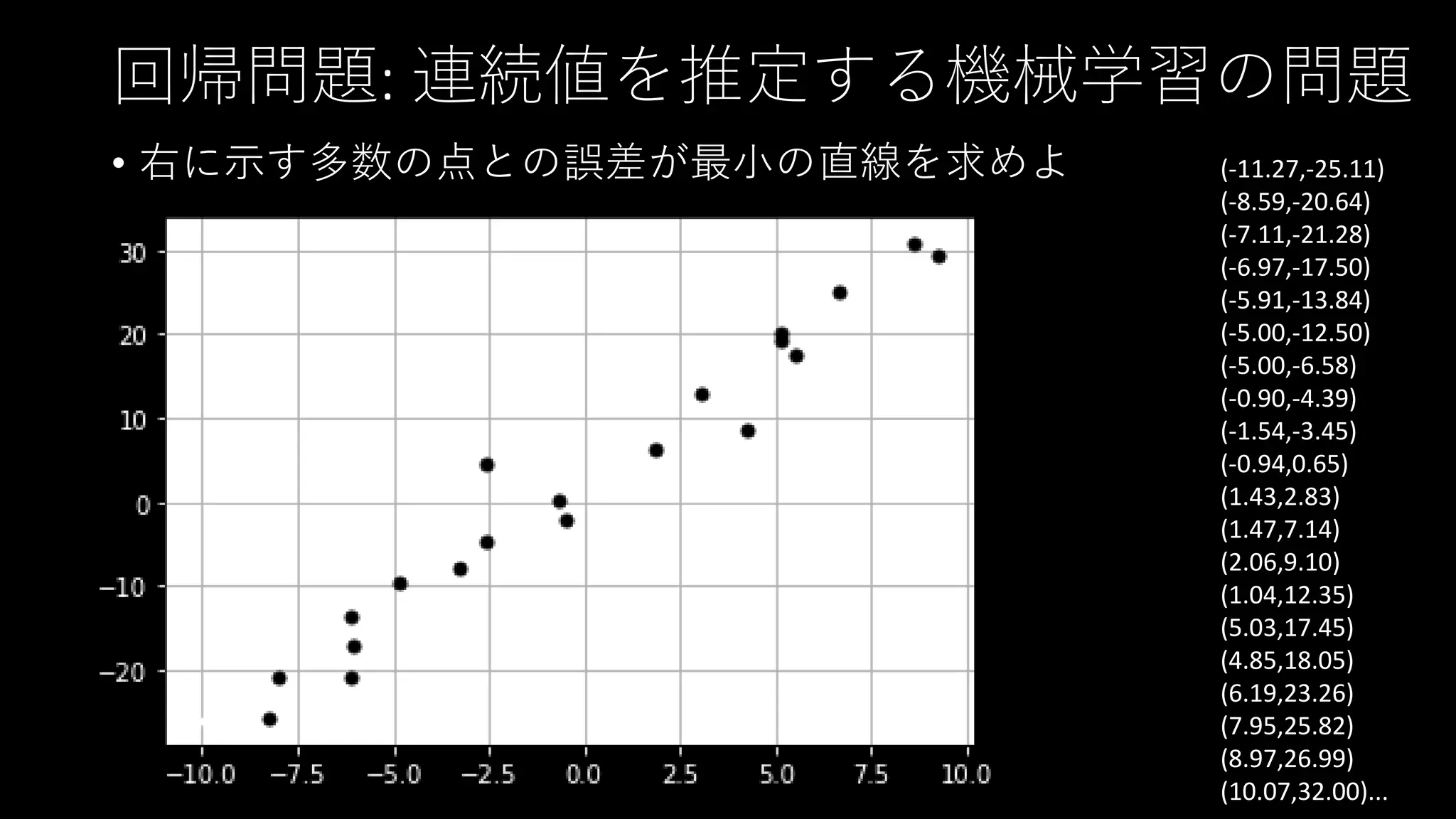
回帰問題: 連続値を推定する機械学習の問題 • 右に示す多数の点との誤差が最小の直線を求めよ
(-11.27,-25.11) (-8.59,-20.64) (-7.11,-21.28) (-6.97,-17.50) (-5.91,-13.84) (-5.00,-12.50) (-5.00,-6.58) (-0.90,-4.39) (-1.54,-3.45) (-0.94,0.65) (1.43,2.83) (1.47,7.14) (2.06,9.10) (1.04,12.35) (5.03,17.45) (4.85,18.05) (6.19,23.26) (7.95,25.82) (8.97,26.99) (10.07,32.00)...
7.
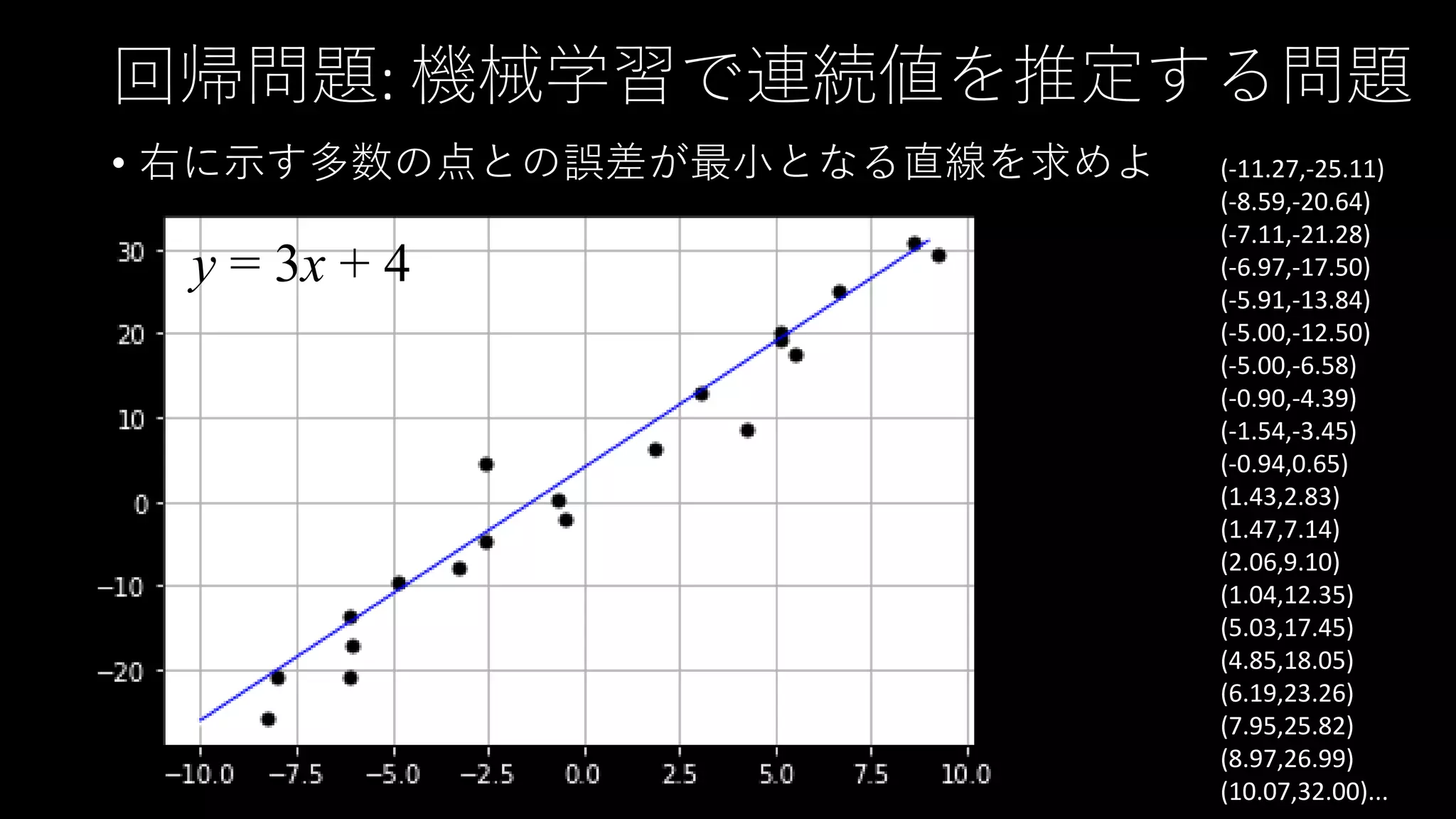
回帰問題: 機械学習で連続値を推定する問題 • 右に示す多数の点との誤差が最小となる直線を求めよ
(-11.27,-25.11) (-8.59,-20.64) (-7.11,-21.28) (-6.97,-17.50) (-5.91,-13.84) (-5.00,-12.50) (-5.00,-6.58) (-0.90,-4.39) (-1.54,-3.45) (-0.94,0.65) (1.43,2.83) (1.47,7.14) (2.06,9.10) (1.04,12.35) (5.03,17.45) (4.85,18.05) (6.19,23.26) (7.95,25.82) (8.97,26.99) (10.07,32.00)... y = 3x + 4
8.
先程の例での仮定: きれいな関数+ノイズ (-11.27,-25.11) (-8.59,-20.64) (-7.11,-21.28) (-6.97,-17.50) (-5.91,-13.84) (-5.00,-12.50) (-5.00,-6.58) (-0.90,-4.39) (-1.54,-3.45) (-0.94,0.65) (1.43,2.83) (1.47,7.14) (2.06,9.10) (1.04,12.35) (5.03,17.45) (4.85,18.05) (6.19,23.26) (7.95,25.82) (8.97,26.99) (10.07,32.00) = (-10.00,-26.00) (-9.00,-23.00) (-8.00,-20.00) (-7.00,-17.00) (-6.00,-14.00) (-5.00,-11.00) (-4.00,-8.00) (-3.00,-5.00) (-2.00,-2.00) (-1.00,1.00) (0.00,4.00) (1.00,7.00) (2.00,10.00) (3.00,13.00) (4.00,16.00) (5.00,19.00) (6.00,22.00) (7.00,25.00) (8.00,28.00) (9.00,31.00) + n
(~N(0,1)) ノイズを正規分布と仮定 x*x
9.
つまり回帰問題とは? • データに載ったノイズを除去した時に現れるであろう法則を推 定し,y=f(x)という関数のパラメタを推定する問題. Wx-y=0 連立方程式 argmin 𝑊 |Wx−y| 回帰問題 xとyの組は2個で必要十分 (xが一次元かつf(x)が線形の場合) ノイズの影響を減らすには xとyの組が多いほどよい. いわゆる誤差 ただしx=(x,1)t
10.
識別問題: 空間を分割する機械学習の問題 • 右に示す多数の点を正しくカテゴリ毎にグループ分けせよ 赤い点:
c = +1 青い点: c = -1
11.
識別問題: 空間を分割する機械学習の問題 • 右に示す多数の点を正しくカテゴリ毎にグループ分けせよ 赤い点:
y = -1 青い点: y = +1 x2 = 3x1 + 4
12.
識別問題: 空間を分割する機械学習の問題 • Wx-y>0かどうかで空間を分割(「識別モデル」の場合) argmin 𝑊 |sign(Wx)
− y| 識別問題 • ノイズの影響を減らすにはxとyの組が多いほどよい • ちなみにsign 関数(符号を返す関数)は微分不可能等の理由で深 層学習ではロジスティック回帰(sigmoid/softmax)が用いられる • 「識別モデル」↔「生成モデル」(本講演では割愛) ただしx=(x1, x2, 1)t
13.
結局の所,機械学習とは?? • ノイズが含まれるデータから目的(回帰,識別,それらの組み合わ せ)を達成できる関数 f
(x)- y の形状を推定する問題 • ノイズって何?(実問題では正規分布になるとは全く限らない) • ラベルノイズ • タグの付け間違い • 観測ノイズ(Feature noiseとも) • センサーノイズ • (画像なら)手ブレなど • 撮影条件の違い(撮影角度,明るさetc.) • 観測対象の状態の違い(事故でバンパーがボコボコになった車の車種を認識できる?) • etc...
14.
昔ながらの実用例(深層学習以前) • 郵便番号の自動読み取り(手書き数字認識) • メールのスパム検知 •
顔検出・笑顔認識・顔ランドマーク検出 • 異常検知(クレジットカード利用履歴,工場での製品検査) • etc...
15.
学術・産業的な盛り上がり. • 今は第3次AIブームと呼ばれている.(下記年代はWikipediaより) • 第1次:
1956-1974, 探索と推論 • 第2次: 1980-1987, ニューラルネットワークなど複雑な識別モデルの登場 • 第3次ブームと今までとの違い: 産業活用に大きく展開できた • スマートスピーカー,物体認識による仕分け,自動運転,etc. • 結果として,Top Levelの国際会議が急速に肥大化している. • NeurIPS / CVPR / ACL / IJCAI ... • 開発競争が激しすぎて半年で陳腐化する技術もざらにある. • 技術開発から実応用までの期間が大幅に短縮されている • Git, Docker, AWS...
16.
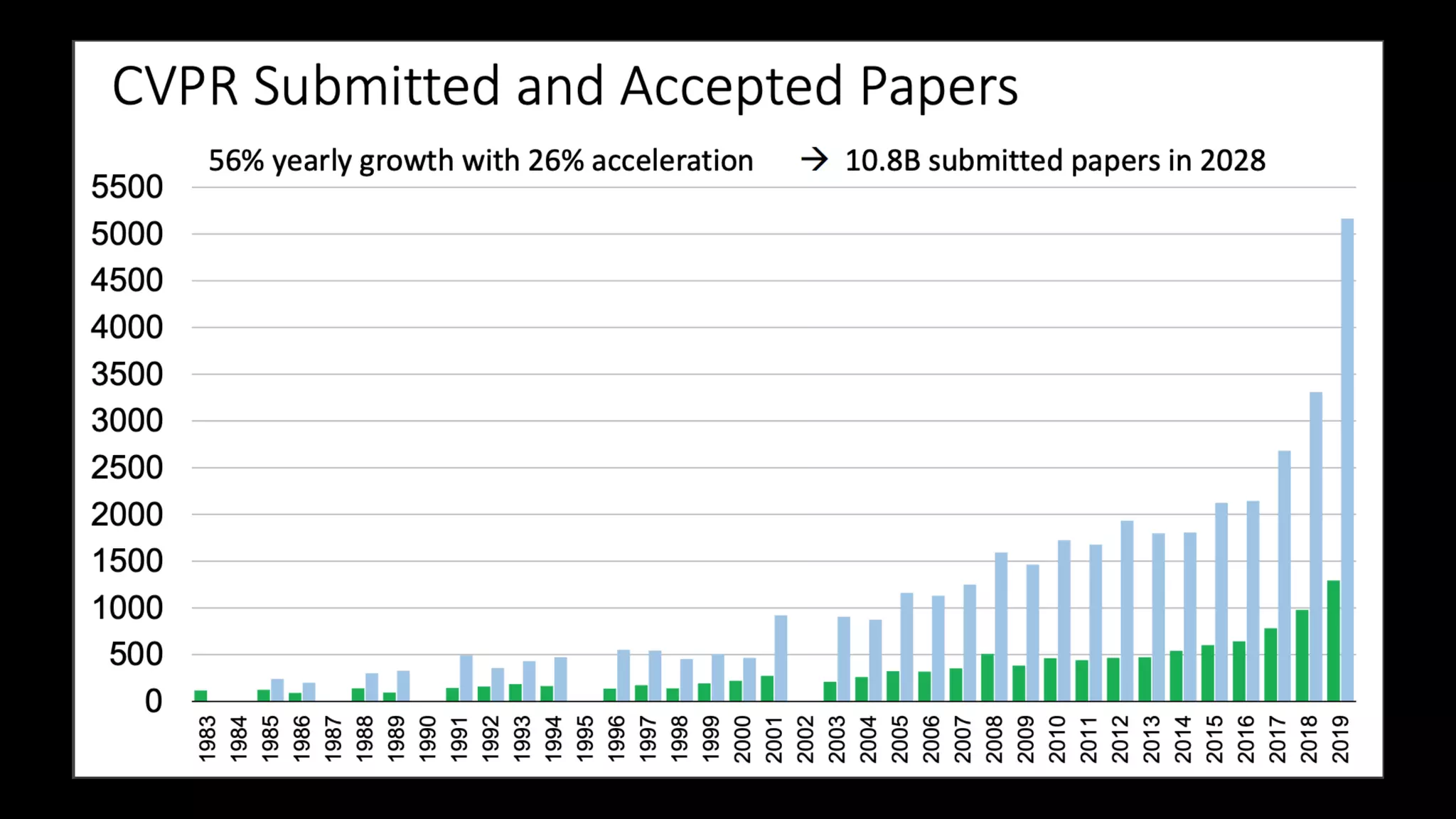
CVPR2019参加レポートより抜粋 (情報処理学会誌2019年11月号) CVPRとは International Conference on
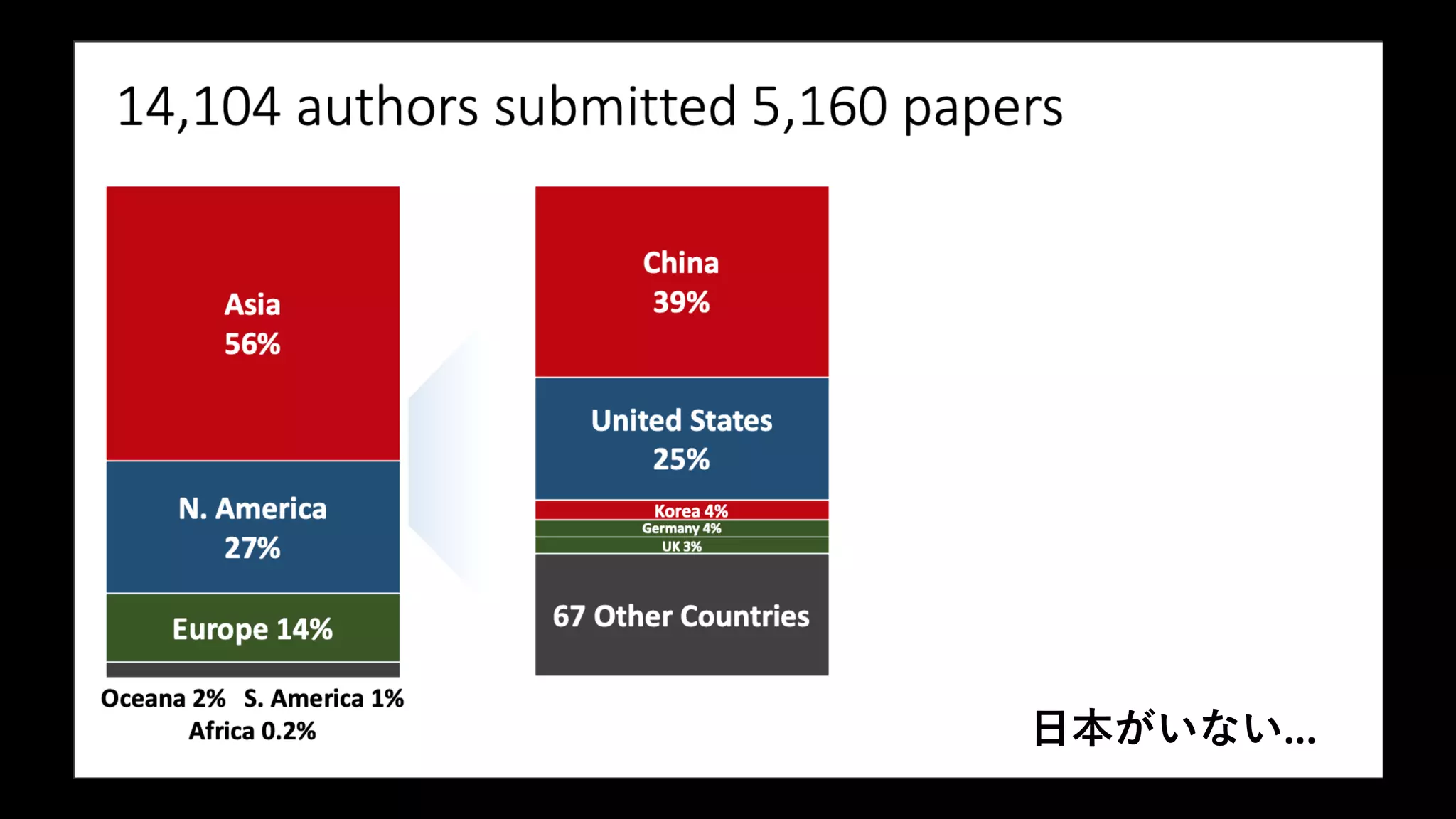
Computer Vision and Pattern Recognition(CVPR)は,IEEE Computer Society と Computer Vision Foundation が主催しているコン ピュータヒ ゙ジョンとパターン認識に関する国際会議であ る.今年の開催場所はロサン ゼルス近郊のロングビー チで,2019 年 6 月 16 日から 20 日にかけて行わ れた. その熱狂的な状況をどのように表現したら読者諸氏に お伝えできるだ ろうか.たとえば,2019 年の Google Scholar Metrics に よ れ ば,CVPR の H5- index は 現 在 240 であり,これは情報処理に関する国際会議の中で 1 位,科学 雑誌を含む全分野のランキングでも 10 位に位置している.参加者は 1 万人弱, スポンサーは 284 社, 団体展示は 104 あり,企業などからの寄付金総額は約 3 億 3 千万円に上る.論文の投稿数は 5,160 本に達し, 採択されたのは 1,294 本, すなわち,4,000 本弱は不採択という巨大かつ競争の激しい状況になっている.
17.
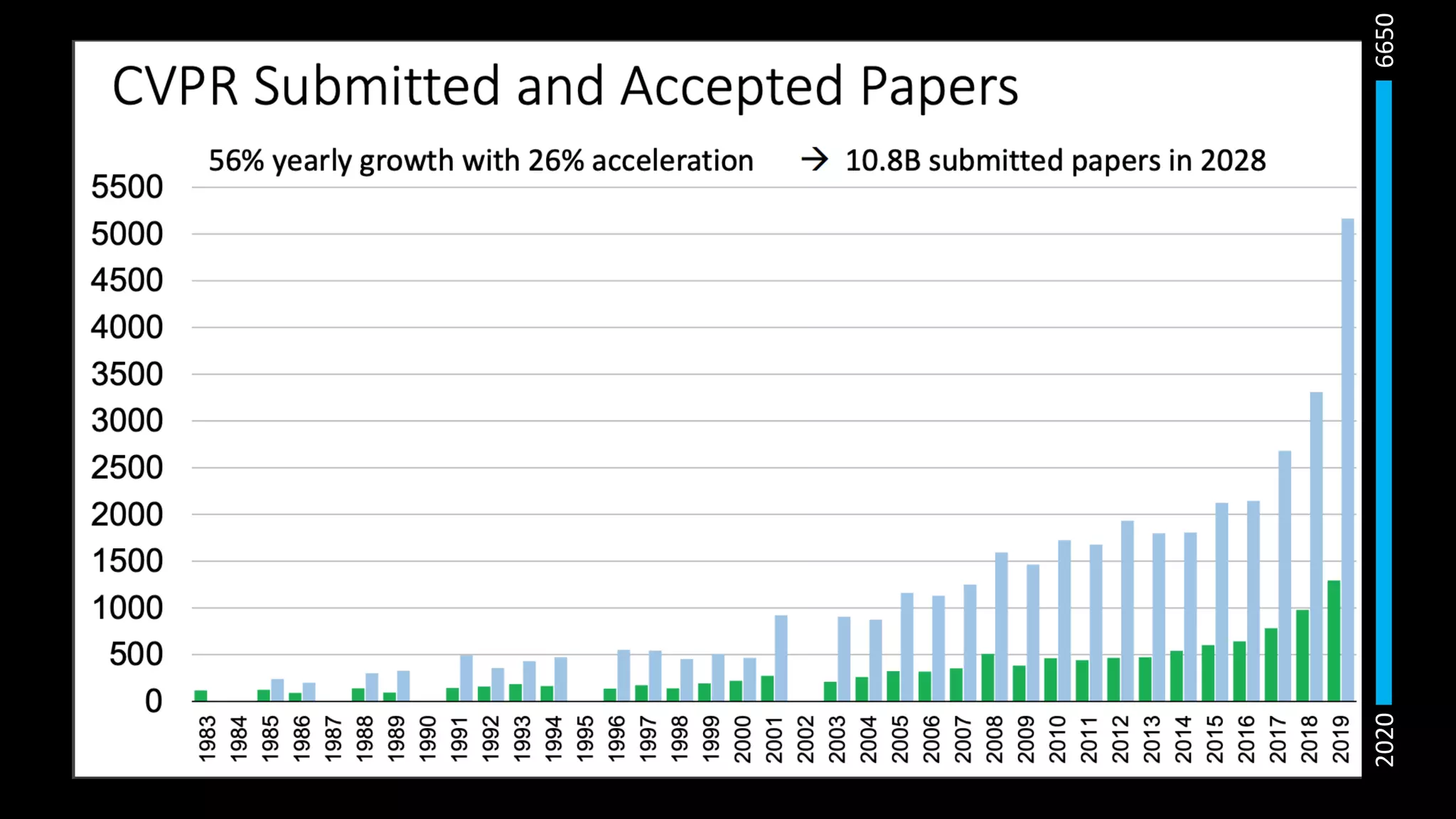
機械学習系のTop会議はどれも似たような曲線で推移している!
20.
20206650
21.
日本がいない...
22.
関数の自由度 • 実際には直線(xが多次元ベクトルの場合は超平面)で回帰で きる問題はごく限られている • 非線形な関数を使った回帰ができると推定精度が上がって嬉し い?
(下図はy = 0.1x2-0.3x+0.4にノイズN(0,1)を加えた例) 線形当てはめ(1次関数) 非線形当てはめ(2次関数) 推定された関数 y= -0.44x + 4.01 推定された関数 y= 0.13x2 -0.51x -0.02
23.
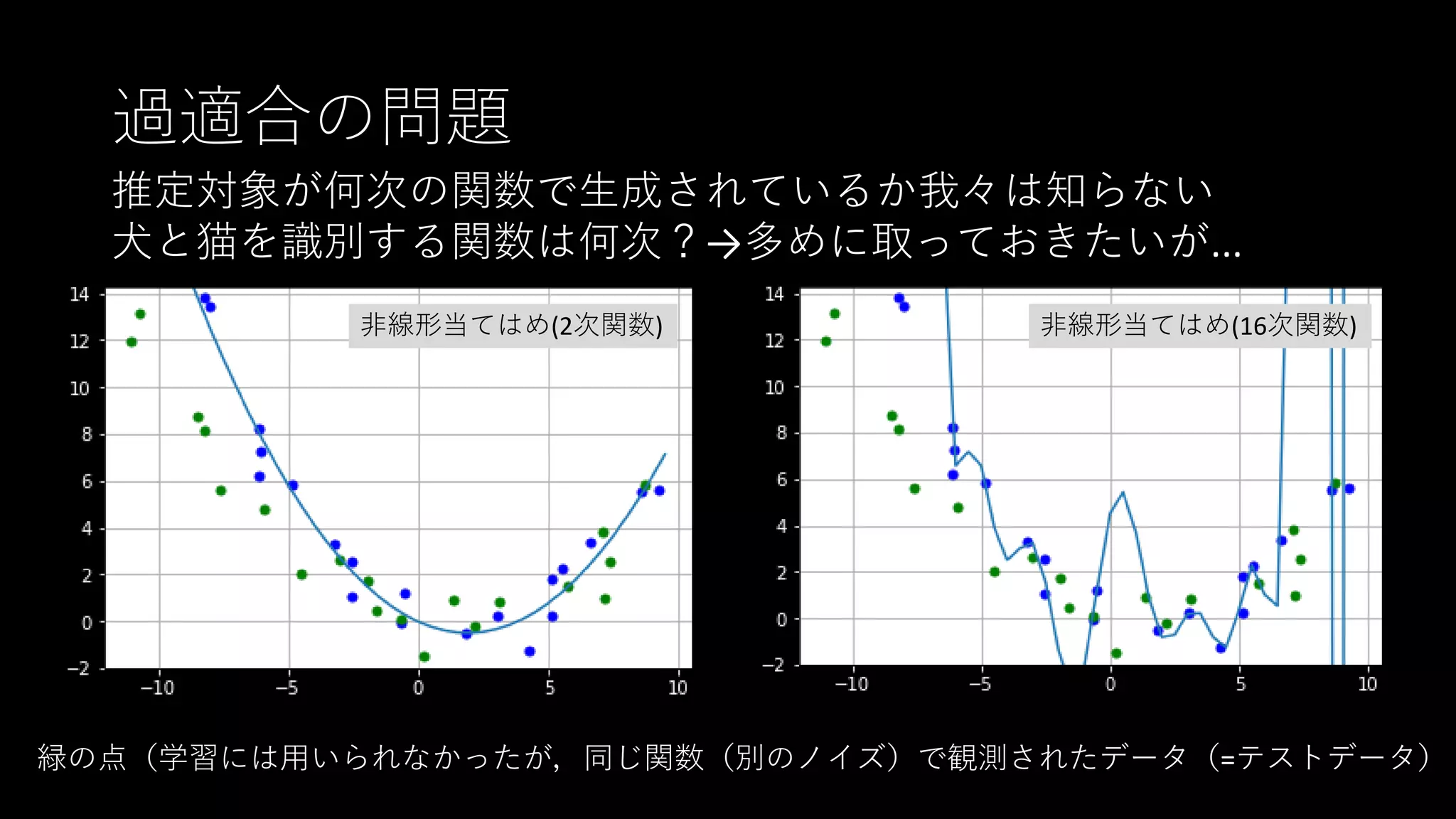
過適合の問題 推定対象が何次の関数で生成されているか我々は知らない 犬と猫を識別する関数は何次?→多めに取っておきたいが... 非線形当てはめ(2次関数) 非線形当てはめ(16次関数) 緑の点(学習には用いられなかったが,同じ関数(別のノイズ)で観測されたデータ(=テストデータ)
24.
探索空間の広さの問題 • パラメタが多いほど,かつ,層が深いほど,関数の形状 も複雑になり,過学習もしやすくなる. → 複雑な関数のパラメタ推定には大量の学習データが必要 非線形当てはめ(16次関数) 学習データ:
200点 非線形当てはめ(16次関数) 学習データ: 20点
25.
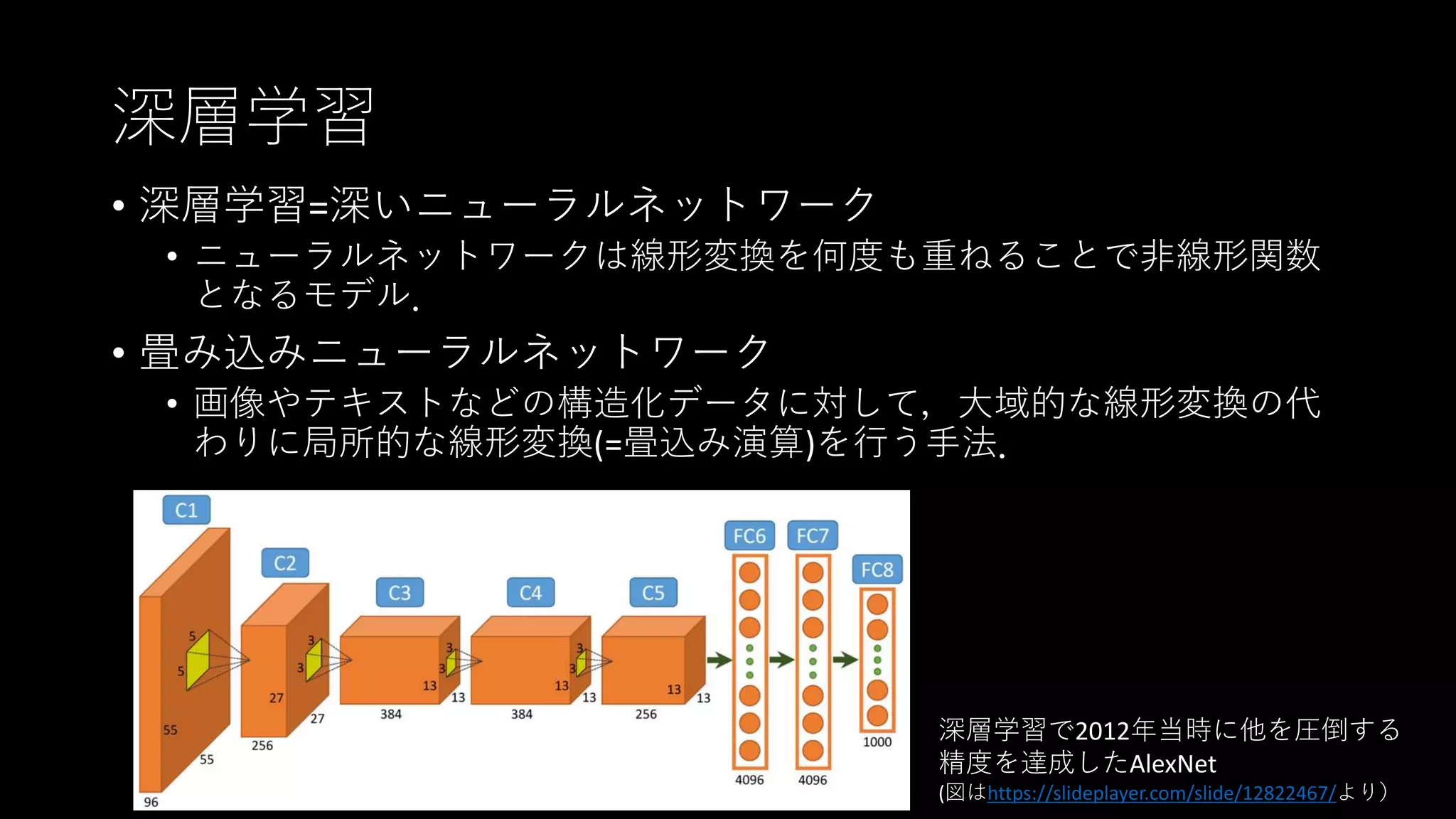
深層学習 • 深層学習=深いニューラルネットワーク • ニューラルネットワークは線形変換を何度も重ねることで非線形関数 となるモデル. •
畳み込みニューラルネットワーク • 画像やテキストなどの構造化データに対して,大域的な線形変換の代 わりに局所的な線形変換(=畳込み演算)を行う手法. 深層学習で2012年当時に他を圧倒する 精度を達成したAlexNet (図はhttps://slideplayer.com/slide/12822467/より)
26.
なぜ深層学習が上手く動くのか? • AlexNetは8層,パラメタ数は62M個 • 学習データ(ImageNet)は約1.2M枚 •
over-parameterization(パラメタ数の方が学習データより多い) • 実はなぜ上手く動くのか,厳密には未だ理論的証明がされていない • 様々な特殊条件下で大域最適解に収束することなどが証明されている. • 万能近似定理: ニューラルネットワークはどんな関数でも近似できる • 宝くじ仮説(2018年3月): パラメタの初期値により作られた一部のルートが最適解 に収束できる(大量のパラメタにより宝くじを買い漁ったような状況) • 日本語の解説スライド • 仮説を裏付ける実験結果は得られている.枝刈りをしても精度が下がりにくいことは知られ ていた→枝刈り後の小さなモデルに元の初期値を振り直して再学習しても精度下がらず.
27.
画像処理における典型的な実用例 (物体検出・カテゴリ領域分割,個体領域分割) Mask R-CNN, ICCV2017 https://github.com/srihari- humbarwadi/cityscapes-segmentation-with- Unet
より.手法はU-net, MICCAI 2015 Faster R-CNN, NIPS2015
28.
物体検出 (Object Detection) •
Faster R-CNN, SSD, Yolo v2などが2年ほどの間に立て続けに出現 • その後もRetinaNet, Yolo v3など. • 問題としては,下記の3つのタスクからなる. 1. ある局所領域内に検出対象物体が存在するかどうかの2クラス識別 2. その物体を囲む矩形の座標の回帰問題 3. その矩形内の物体の種類の分類 Faster R-CNN, NIPS2015
29.
カテゴリ領域分割(semantic segmentation) • 矩形ではなく,領域を分割.画素ごとのクラス分類として定式化 •
代表的なU-Netは元々は細胞領域の特定のために提案された. • その後,その汎用性から,他の様々な問題に応用され,発展した. Cityscapes Datasetへの適用結果(https://github.com/srihari- humbarwadi/cityscapes-segmentation-with-Unet より)U-net, MICCAI 2015
30.
個体領域分割(Instance segmentation) Mask R-CNN,
ICCV2017 • カテゴリ領域分割では同じ種類の物体が隣り合う時に境界を区別 できなかった • まずは物体検出により個体ごとの矩形を得て,その後で矩形内で 画素ごとに矩形の注目物体領域か否かを2クラス識別
31.
Yet another hot-topic:
GAN 画像はSpectral Normalization for Generative Adversarial Networks, ICLR2018 より あるデータ集合(例えば写真 群)を表すデータ分布 pdata があ るとする. G ∘ U (−1,1)= Gによってpdataと同じ形状 のデータ分布 qを得たい 種となる分布pz (例: 一様分布) ニューラルネット
32.
敵対的学習によるデータ生成(GAN) Generator z~𝑝 𝑧 G xfake xreal Discriminator D y ∈
{real, fake} 𝑦 ~𝑝 𝑑𝑎𝑡𝑎 様々な手法があるが,基本的には2つの分布のDivergenceを最小化する形に帰着される. 優れたGANのチュートリアル: https://www.slideshare.net/TomohiroTakahashi2/miru-miru-gan 目的関数
33.
GANはMin-max 最適化(鞍点探索) Dの最適化 (できるだけreal/fakeを識別) Gの最適化 (できるだけDを騙す) 目指すべき パラメタの点 目的変数 パラメタ空間 実際には様々な理由により学習が難しい(大抵はDが強くなりすぎる) . 簡便に最適化するための理論・Bad
knowhowが混在. → WGAN-gp (NIPS2015), Spectral Normalization(ICLR2018)など → GANを学習させるための14のテクニック
34.
GANの実用例(画像修復,超解像,Semantic Manipulation) Beyond Human-level
License Plate Super- resolution with Progressive Vehicle Search and Domain Priori GAN, ACMMM2017 実際の入力は同じような解像度の複数枚の画像 Generative Image Inpainting with Contextual Attention, CVPR2018 High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, CVPR2018
35.
Food Change Lens:
https://www.youtube.com/watch?v=QNNgyZi11fY
36.
なぜ深層学習が上手く動くかないのか?
37.
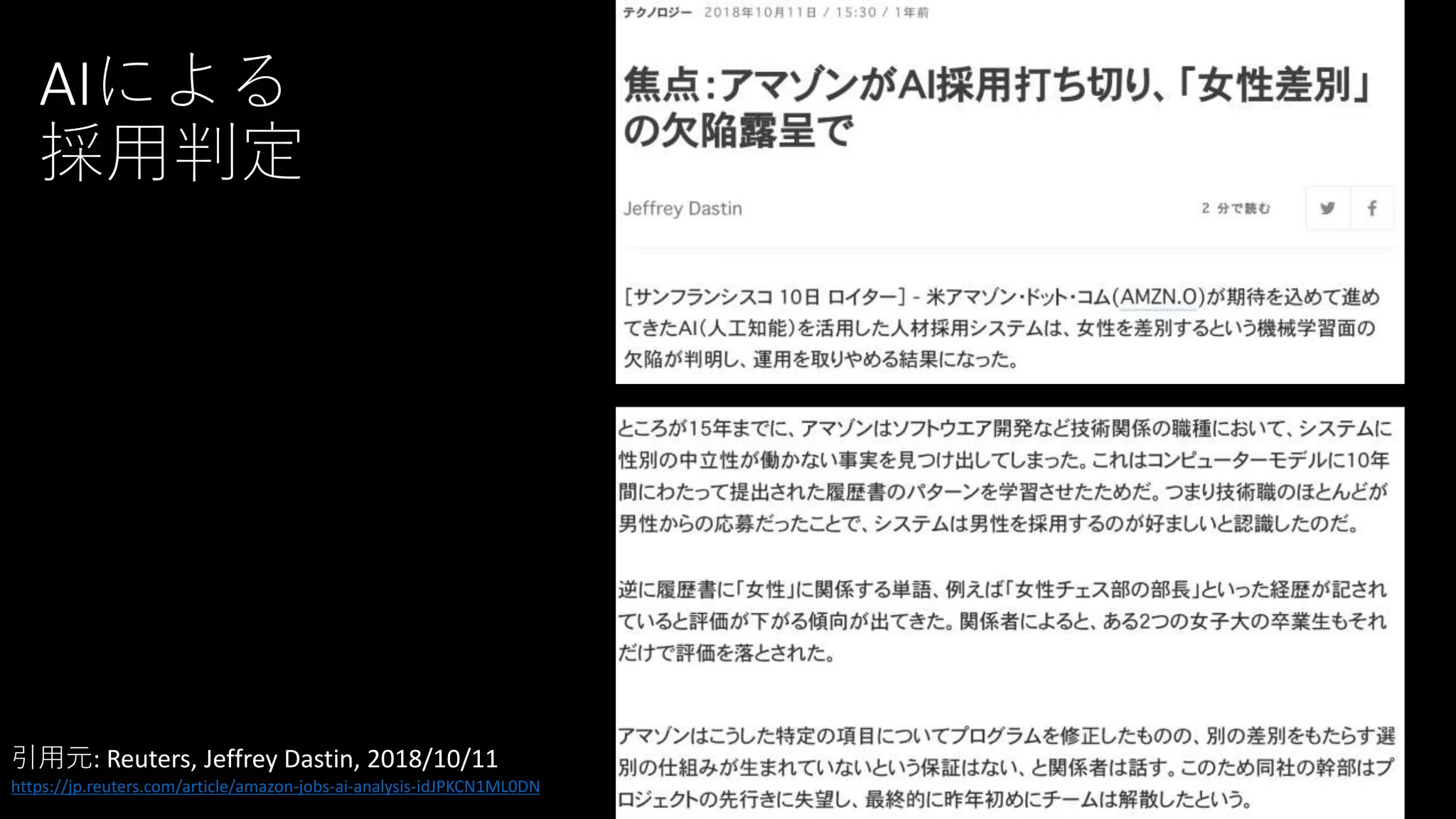
AIによる 採用判定 引用元: Reuters, Jeffrey
Dastin, 2018/10/11 https://jp.reuters.com/article/amazon-jobs-ai-analysis-idJPKCN1ML0DN
38.
顔認識技術が全く動作しないトラブル 引用元: MIT Tech
Review, Niall Firth, 2019/4/10 https://www.technologyreview.jp/nl/new-yorks-mass-face-recognition-trial-on-drivers-has-been-a-spectacular-failure/
39.
上手く動かない場合に備えた保険まで... 引用元: 日本経済新聞 電子版,
2019/7/30 https://www.nikkei.com/article/DGXMZO47986460Q9A730C1EE9000/
40.
なぜ深層学習が上手く動くかないのか? • 学習データのBias(偏り)の影響を取り除く機構がない
41.
特徴量の制御: 公平性/ドメイン不変性 • ネットワークにより抽出する特徴量
z に対して,以下の2つを同 時に満たすように学習を行う 1. ある目的変数 y の予測性能を最大化する 2. バイアス説明変数 s に対する依存性を最小化する →これはつまりmin-max 最適化問題に落ちる?? • バイアス説明変数 s の例 • 公平性: 性別,人種,収入, etc. • ドメイン不変性: 観測環境,観測条件 etc.
42.
Adversarial Discriminative Domain
Adaptation (CVPR2017) 識別器 Discriminator 特徴抽出器 学習データX1 (s=1) 学習データX2 (s=2) x z 𝑦 𝑠 敵対的学習部分 予測性能を最大化 Dは 𝑠の予測性能最大化 Eは 𝑠の予測性能最小化 D E 敵対学習を特徴量からの「情報の引き算」に使う手法
43.
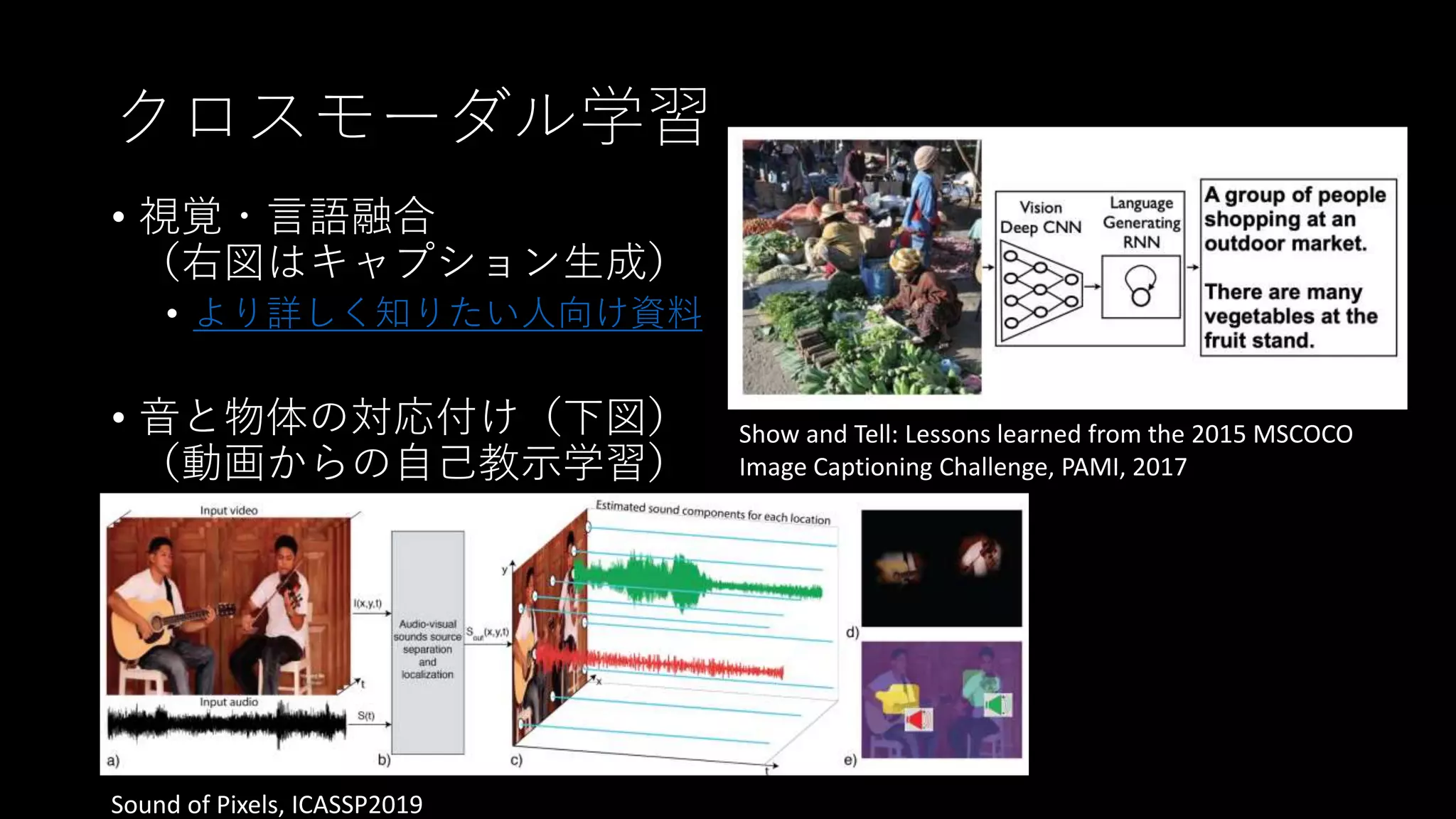
クロスモーダル学習 • 視覚・言語融合 (右図はキャプション生成) • より詳しく知りたい人向け資料 •
音と物体の対応付け(下図) (動画からの自己教示学習) Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge, PAMI, 2017 Sound of Pixels, ICASSP2019
44.
動画からの密なキャプション生成 • Dense Captioning
(CVPR2016) • 静止画からの密なキャプション生成 (物体検出+キャプション生成) • 膨大なデータセットの作成 (Visual Genom) https://visualgenome.org/ • Dense Captioning Events in Videos (ICCV2017) • 動画の部分時系列に対するキャプション (次頁動画で紹介) DenseCap: Fully Convolutional Localization Networks for Dense Captioning, CVPR2016
46.
その他の視覚・言語融合技術 • キャプション→画像・動画 • 言語指示による彩色 •
質問応答(画像に関する質問の回答を生成) • etc. • いずれも,データセットの作成が肝 • データセットにないものは作れないことが多い. • 特にキャプションのみで画像・動画を生成するのは非常に困難 (言語的に明示されない要素が多い=曖昧性が大きい)
47.
視聴覚融合: 「音」と「音源」の関係を学習 • 動画:
映像と音声が時間的に同期している • 時間的な同期を教師情報とする,一種の自己教示学習 • 視覚・言語融合と違って,データセットの構築は比較的容易. • 顔と声,楽器と音質など. • Seeing voices and Hearing Faces: Cross-modal biometric matching , CVPR2018 https://www.robots.ox.ac.uk/~vgg/research/CMBiometrics/ • The sounds of pixel, ICASSP2019, http://sound-of-pixels.csail.mit.edu/
50.
自己教示学習 • 正解ラベルを人手でつけることは非常にコストが大きい • 昔からコスト削減のための様々なアプローチが研究されている •
半教師あり学習 • ラベルが付けられた一部のデータ+大量のラベルなしデータ • 弱教師あり学習 • 解きたい課題に対して(容易にラベル付け可能な)ヒント付きデータで学習 (例: 領域分割→画像中の物体ラベルのみ付与) • 能動学習 • できるだけ少ないデータへのラベル付けで高い精度を得る • グループごとのラベル付けや,ラベル付けすべきサンプルを自動選択する • 自己教示学習 • 全く人手でのラベル付けなしで,内容を良く表現する特徴抽出器を学習
51.
データ操作→操作内容推定に基づく自己教示学習 • 時空間的な組み換えによるもの • Jigsaw,
Jigsaw++,...: 組み換えを元に戻す操作を推定 • Shuffle and learn (右図), ... • 与えられた系列が時系列順か否かを推定 • 他にも,色付けや回転角度推定など... 網羅的なサーベイ: https://github.com/jason718/awesome-self-supervised-learning Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles, ECCV2016 Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV2016
52.
時空間的な内挿・外挿に基づく自己教示学習 網羅的なサーベイ: https://github.com/jason718/awesome-self-supervised-learning Unsupervised Learning
of Long-Term Motion Dynamics for Videos, CVPR2017 未来(直後)のOpticalFlow(画素毎の動き)を予測 Self-Supervised Feature Learning by Learning to Spot Artifacts 欠損復元画像か未欠損画像かの識別
53.
情報理論的なアプローチによる自己教示学習 • 入力画像 x
と特徴量 z の相互情報量 I(x;z)(の下限)を最大化する 網羅的なサーベイ: https://github.com/jason718/awesome-self-supervised-learning Learning Deep Representations by Mutual Information Estimation and Maximization, ICLR2017 • 従来の発見的手法と違い,理論的な議論 が可能なアプローチ • xとz の正例ペアと負例ペアを識別する だけで良い. • zを知ること≒xを知ることとなるよう学習. • 自己符号化器(Auto-Encoder)と違い, 復号部分の設計が不要 • 特にx,zに局所性を持たせることでより良い 特徴表現を得られる. • とにかく,発見的手法ではない(より抽象 的・汎用的手法)という触れ込み.
54.
以上,オムニバス形式で最新トピックを紹介した CVPR2019参加レポートより抜粋 (情報処理学会誌2019年11月号)
55.
深層学習の未解決問題は山程ある. 1. 調整の難しさ(ハイパーパラメタ調整) • 現状は探索ベース(try&error) •
離散空間の探索は難しい(勾配が得られない→進むべき方向が不明) • (特に強化学習や逆強化学習で顕著) 2. 最適性の保証がない. • たどり着いたモデルパラメタは飽くまでも「とても良い局所解」 • 理論的な最適保証があり,かつ,深層学習並の精度を達成する方法はない? 3. 得られるものは飽くまでも「統計量」であって「知識」ではない. • 深層学習単体をAIと呼ぶことは危険. 4. 説明性・可読性の不足 • 事故調査が困難 → Serious Tech.への利用における高いリスク • なぜうまく動くかわからない→今の所,工学的ではあるが科学的ではない???
56.
まとめ • 機械学習の応用に関する最新動向を``いくつか’’紹介 • 深層学習・敵対的学習(min-max最適化)・クロスモーダル学習・自己教示学習 •
より基礎的な内容は下記のような資料がわかりやすい. • 産業総合研究所・神嶌先生の講義資料 • http://www.kamishima.net/jp/kaisetsu/ • (ちょっとむずかしいですが)PRML本(大学院生レベル) • パターン認識と機械学習(上・下) C.M. ビショップ著 • 逆にとにかくプログラミングを学びたい実践派であれば • Amazonで 深層学習+ライブラリ名(pytorch, chainer, tensorflow, keras, mxnet...)で 検索すると大量にヒットします. • Papers with Codes https://paperswithcode.com/ には近年のTop Conferenceに採録 された手法でcodeが提供されているものが問題別に検索可能です.
Download


















































![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)











![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)













![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)



![春の情報処理祭り 2015 [リクルートx情報処理学会] CVIM 橋本](https://cdn.slidesharecdn.com/ss_thumbnails/ipjsseminer-150317071445-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)














