• [H. Liu+,ICLR’22] Hong Liu, Jeff Z HaoChen, Adrien Gaidon, Tengyu Ma. Self-supervised Learning is More
Robust to Dataset Imbalance. In International Conference on Learning Representations, 2022.
• [A. Jsaiswal+, 20] Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, Fillia
Makedon. A survey on contrastive self-supervised learning. Technologies, MDPI, 2020.
• [T. Chen+, ICML’20] Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton. A Simple Framework
for Contrastive Learning of Visual Representations. In International Conference on Machine Learning, 2020.
• [I. Misra+, CVPR’20] Ishan Misra, Laurens van der Maaten. Self-Supervised Learning of Pretext-Invariant
Representations. In Computer Vision and Pattern Recognition Conference, 2020.
• [K. He+, CVPR’20] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick. Momentum Contrast for
Unsupervised Visual Representation Learning. In Computer Vision and Pattern Recognition Conference, 2020.
• [M. Caron+, NeurIPS’20] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand
Joulin. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. In Neural Information
Processing Systems, 2020.
• [P. Foret+, ICLR’21] Pierre Foret, Ariel Kleiner, Hossein Mobahi, Behnam Neyshabur. Sharpness-Aware
Minimization for Efficiently Improving Generalization. In International Conference on Learning Representations,
2021.
参考文献 15
16.
• [K. Cao+,NeurIPS’19] Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning
imbalanced datasets with label-distribution-aware margin loss. In Neural Information Processing Systems, volume
32, pages 1565–1576. Curran Associates, Inc., June 2019.
• [K. Cao+, ICLR’21] Kaidi Cao, Yining Chen, Junwei Lu, Nikos Arechiga, Adrien Gaidon, and Tengyu Ma.
Heteroskedastic and imbalanced deep learning with adaptive regularization. In International Conference on
Learning Representations, 2021.
• [T. Lin+, ICCV’17] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dolla ́r. Focal loss for dense
object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
• [B. Knag+, ICLR’20] Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and
Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. In International Conference
on Learning Representations, 2020.
• [T. Wang+, ECCV’20] Tao Wang, Yu Li, Bingyi Kang, Junnan Li, Junhao Liew, Sheng Tang, Steven Hoi, and
Jiashi Feng. The devil is in classification: A simple framework for long-tail instance segmentation. In European
Conference on computer vision, pages 728–744. Springer, 2020.
• [Y. Yang & Z. Xu, NeurIPS’20] Yuzhe Yang and Zhi Xu. Rethinking the value of labels for improving class-
imbalanced learning. In Advances in Neural Information Processing Systems, volume 33, pages 19290–19301.
Curran Associates, Inc., 2020.
参考文献 16



![• 似ているデータは,潜在空間 でも似た表現を
獲得することを期待し,正例ペアを近づけ,
負例ペアを遠ざけるように学習
正例ペア:original image とデータ拡張した image
負例ペア:original image とそれ以外の image
• 損失関数
NCE 損失が基本系で,派生系が多数提案
: query (original image),
: positive key (augmented positive image),
: negative key (negative image)
• 詳しく知りたい人は omiita さんの Qitta 記事が分かりやすい
𝒵
LNCE = − log
exp(sim(q, k+)/τ)
exp(sim(q, k+)/τ) + exp(sim(q, k−)/τ)
q
k+
k−
対照学習 4
[A. Jaiswal+, 20]](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-4-320.jpg)
![対照学習 5
構造
手法
SimCLR
[T. Chen+, ICML 20]
PIRL
[I. Misra+, CVPR 20]
MoCo
[K. He+, CVPR 20]
SwAV
[M. Caron+, NeurIPS 20]
特徴
End2End で学習する
シンプルな構造
key に関しては MB を
活用してメモリ節約
指数移動平均で
MB を更新
クラスタリングによって
近いサンプルも positive に](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-5-320.jpg)
![• 分布内 vs 分布外
分布内領域(ID; in distribution):事前学習用データセットの分布 と目標データセットの領域
が同じ
分布外領域(OOD; out of distribution):事前学習用データセットの領域 と目標データセットの領
域 が異なる
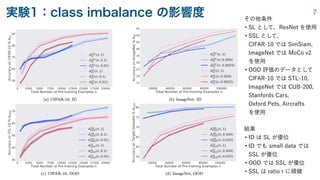
• 実験1:class imbalance の影響度合いの評価
実験条件
- class imbalanced なデータセットを用いて事前学習を行い,class balanced な目標データセットで
fi
ne-tune
-
class imbalance ratio を変えて実験
- class imbalance な分布として long-tailed な exponential and Pareto 分布を使用
- linear probing(潜在空間における線形分類)の top-1 accuracy で評価
𝒟
pre
⊂
𝒳
×
𝒴
𝒟
target
⊂
𝒳
×
𝒴
𝒟
pre
⊂
𝒳
×
𝒴
𝒟
target
⊂
𝒳
×
𝒴
r =
minj∈[C] P(y = j)
maxj∈[C] P(y = j)
≤ 1
分布内領域 vs 分布外領域 6](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-6-320.jpg)


![• 局所最適解には,良い解と悪い解があり,一般に周りが平坦なほど良い解とされている
• SAM では,損失が最小かつその周りも平坦な解を探索する
• 最適化問題
周囲 近傍の中での最大値を損失関数に取る
周囲 近傍を用いた min-max 最適問題となる
• @omiita さんの Qiita 記事による日本語解説あり
ρ
LSAM
𝒮
(w) ≜ max
∥ϵ∥p≤ρ
L
𝒮
(w + ϵ)
ρ
min
w
[ max
∥ϵ∥p≤ρ
L
𝒮
(w + ϵ) − L
𝒮
(w)] + L
𝒮
(w) + λ∥w∥2
2
SAM (Sharpness-Aware Minimization) [P. Foret+, ICLR 21] 10
Sharp な悪い局所最適解
Flat な良い局所最適解](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-10-320.jpg)
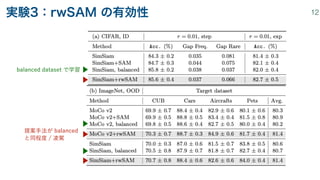
![• SSL の汎化ギャップは,frequent class の方が rare class より小さい
汎化ギャップ (generalization gap):
期待損失 経験損失
アイディア:Rare class のサンプルにより強い正則化をかけることで,rare class に対する汎化性能を向上させる
• Reweighted SAM (rwSAM)
近傍探索用の損失関数に sample ごとに重み を与えて SAM による最適化を行う
重み は特徴空間においてカーネル密度比推定(KDE; kernel density estimation)することによって与える
RBF kernel の bandwidth parameter と はハイパラであり,CV で決定
𝔼
(x,y)∼Pall[l(x, y)] −
𝔼
(x,y)∼Pdata[l(x, y)]
i wi
min
ϕ
L(ϕ + ϵw(ϕ)), where ϵw(ϕ) = arg max
∥ϵ∥<ρ
ϵT
∇ϕLw(ϕ), Lw(ϕ) =
1
|B| ∑
j∈B
wjl(xj, ϕ)
wi
wi =
(
1
n
K(fϕ(xi) − fϕ(xj), h)
)
−α
h α > 0
再重み付き正則化手法 rwSAM の提案 11](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-11-320.jpg)
![• 古典的手法
Resampling:希少なクラスを多くリサンプリングしておく
Re-weighting:希少なクラスの学習重みを大きく設定する
• 最近の手法
Re-weighting regularization [K. Cao+, NeurIPS 19]:希少なクラスの正則化重みを大きく設定
Heteroskedastic adaptive regularization [K. Cao+, ICLR 21]:不均衡でノイズが多い場合に損失の局所的な曲率
を正則化
Focal loss [T. Lin+, ICCV 17]:学習が難しいサンプルの学習を促進
[B. Knag+, ICLR 20] & [T. Wang+, ECCV 20]:SL の表現は分類器よりもクラス不均衡に対して頑健であることを
証明
[Y. Yang & Z. Xu, NeurIPS 20]:クラス不均衡な SL に対して SSL の事前学習を活用
先行研究(クラス不均衡に対処する SL) 13](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-13-320.jpg)

![• [H. Liu+, ICLR’22] Hong Liu, Jeff Z HaoChen, Adrien Gaidon, Tengyu Ma. Self-supervised Learning is More
Robust to Dataset Imbalance. In International Conference on Learning Representations, 2022.
• [A. Jsaiswal+, 20] Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, Fillia
Makedon. A survey on contrastive self-supervised learning. Technologies, MDPI, 2020.
• [T. Chen+, ICML’20] Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton. A Simple Framework
for Contrastive Learning of Visual Representations. In International Conference on Machine Learning, 2020.
• [I. Misra+, CVPR’20] Ishan Misra, Laurens van der Maaten. Self-Supervised Learning of Pretext-Invariant
Representations. In Computer Vision and Pattern Recognition Conference, 2020.
• [K. He+, CVPR’20] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick. Momentum Contrast for
Unsupervised Visual Representation Learning. In Computer Vision and Pattern Recognition Conference, 2020.
• [M. Caron+, NeurIPS’20] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand
Joulin. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. In Neural Information
Processing Systems, 2020.
• [P. Foret+, ICLR’21] Pierre Foret, Ariel Kleiner, Hossein Mobahi, Behnam Neyshabur. Sharpness-Aware
Minimization for Efficiently Improving Generalization. In International Conference on Learning Representations,
2021.
参考文献 15](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-15-320.jpg)
![• [K. Cao+, NeurIPS’19] Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning
imbalanced datasets with label-distribution-aware margin loss. In Neural Information Processing Systems, volume
32, pages 1565–1576. Curran Associates, Inc., June 2019.
• [K. Cao+, ICLR’21] Kaidi Cao, Yining Chen, Junwei Lu, Nikos Arechiga, Adrien Gaidon, and Tengyu Ma.
Heteroskedastic and imbalanced deep learning with adaptive regularization. In International Conference on
Learning Representations, 2021.
• [T. Lin+, ICCV’17] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dolla ́r. Focal loss for dense
object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
• [B. Knag+, ICLR’20] Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and
Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. In International Conference
on Learning Representations, 2020.
• [T. Wang+, ECCV’20] Tao Wang, Yu Li, Bingyi Kang, Junnan Li, Junhao Liew, Sheng Tang, Steven Hoi, and
Jiashi Feng. The devil is in classification: A simple framework for long-tail instance segmentation. In European
Conference on computer vision, pages 728–744. Springer, 2020.
• [Y. Yang & Z. Xu, NeurIPS’20] Yuzhe Yang and Zhi Xu. Rethinking the value of labels for improving class-
imbalanced learning. In Advances in Neural Information Processing Systems, volume 33, pages 19290–19301.
Curran Associates, Inc., 2020.
参考文献 16](https://image.slidesharecdn.com/220707ishizoneclassimbalancessl-220707052913-ce2b086e/85/220707_ishizone_class_imbalance_SSL-pdf-16-320.jpg)
![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20210625robustnetlin-210625020332-thumbnail.jpg?width=640&height=640&fit=bounds)











